 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKGS-GCN: Enhancing Sparse Skeleton Sensing via Kinematics-Driven Gaussian Splatting and Probabilistic Topology for Action Recognition
Mar 16, 2026Skeleton-based action recognition is widely utilized in sensor systems including human-computer interaction and intelligent surveillance. Nevertheless, current sensor devices typically generate sparse skeleton data as discrete coordinates, which inevitably discards fine-grained spatiotemporal details during highly dynamic movements. Moreover, the rigid constraints of predefined physical sensor topologies hinder the modeling of latent long-range dependencies. To overcome these limitations, we propose KGS-GCN, a graph convolutional network that integrates kinematics-driven Gaussian splatting with probabilistic topology. Our framework explicitly addresses the challenges of sensor data sparsity and topological rigidity by transforming discrete joints into continuous generative representations. Firstly, a kinematics-driven Gaussian splatting module is designed to dynamically construct anisotropic covariance matrices using instantaneous joint velocity vectors. This module enhances visual representation by rendering sparse skeleton sequences into multi-view continuous heatmaps rich in spatiotemporal semantics. Secondly, to transcend the limitations of fixed physical connections, a probabilistic topology construction method is proposed. This approach generates an adaptive prior adjacency matrix by quantifying statistical correlations via the Bhattacharyya distance between joint Gaussian distributions. Ultimately, the GCN backbone is adaptively modulated by the rendered visual features via a visual context gating mechanism. Empirical results demonstrate that KGS-GCN significantly enhances the modeling of complex spatiotemporal dynamics. By addressing the inherent limitations of sparse inputs, our framework offers a robust solution for processing low-fidelity sensor data. This approach establishes a practical pathway for improving perceptual reliability in real-world sensing applications.
Dissecting Outlier Dynamics in LLM NVFP4 Pretraining
Feb 02, 2026Training large language models using 4-bit arithmetic enhances throughput and memory efficiency. Yet, the limited dynamic range of FP4 increases sensitivity to outliers. While NVFP4 mitigates quantization error via hierarchical microscaling, a persistent loss gap remains compared to BF16. This study conducts a longitudinal analysis of outlier dynamics across architecture during NVFP4 pretraining, focusing on where they localize, why they occur, and how they evolve temporally. We find that, compared with Softmax Attention (SA), Linear Attention (LA) reduces per-tensor heavy tails but still exhibits persistent block-level spikes under block quantization. Our analysis attributes outliers to specific architectural components: Softmax in SA, gating in LA, and SwiGLU in FFN, with "post-QK" operations exhibiting higher sensitivity to quantization. Notably, outliers evolve from transient spikes early in training to a small set of persistent hot channels (i.e., channels with persistently large magnitudes) in later stages. Based on these findings, we introduce Hot-Channel Patch (HCP), an online compensation mechanism that identifies hot channels and reinjects residuals using hardware-efficient kernels. We then develop CHON, an NVFP4 training recipe integrating HCP with post-QK operation protection. On GLA-1.3B model trained for 60B tokens, CHON reduces the loss gap to BF16 from 0.94% to 0.58% while maintaining downstream accuracy.
EDGC: Entropy-driven Dynamic Gradient Compression for Efficient LLM Training
Nov 13, 2025Training large language models (LLMs) poses significant challenges regarding computational resources and memory capacity. Although distributed training techniques help mitigate these issues, they still suffer from considerable communication overhead. Existing approaches primarily rely on static gradient compression to enhance communication efficiency; however, these methods neglect the dynamic nature of evolving gradients during training, leading to performance degradation. Accelerating LLM training via compression without sacrificing performance remains a challenge. In this paper, we propose an entropy-driven dynamic gradient compression framework called EDGC. The core concept is to adjust the compression rate during LLM training based on the evolving trends of gradient entropy, taking into account both compression efficiency and error. EDGC consists of three key components.First, it employs a down-sampling method to efficiently estimate gradient entropy, reducing computation overhead. Second, it establishes a theoretical model linking compression rate with gradient entropy, enabling more informed compression decisions. Lastly, a window-based adjustment mechanism dynamically adapts the compression rate across pipeline stages, improving communication efficiency and maintaining model performance. We implemented EDGC on a 32-NVIDIA-V100 cluster and a 64-NVIDIA-H100 cluster to train GPT2-2.5B and GPT2-12.1B, respectively. The results show that EDGC significantly reduces communication latency and training time by up to 46.45% and 16.13% while preserving LLM accuracy.
Exchange Policy Optimization Algorithm for Semi-Infinite Safe Reinforcement Learning
Nov 06, 2025Safe reinforcement learning (safe RL) aims to respect safety requirements while optimizing long-term performance. In many practical applications, however, the problem involves an infinite number of constraints, known as semi-infinite safe RL (SI-safe RL). Such constraints typically appear when safety conditions must be enforced across an entire continuous parameter space, such as ensuring adequate resource distribution at every spatial location. In this paper, we propose exchange policy optimization (EPO), an algorithmic framework that achieves optimal policy performance and deterministic bounded safety. EPO works by iteratively solving safe RL subproblems with finite constraint sets and adaptively adjusting the active set through constraint expansion and deletion. At each iteration, constraints with violations exceeding the predefined tolerance are added to refine the policy, while those with zero Lagrange multipliers are removed after the policy update. This exchange rule prevents uncontrolled growth of the working set and supports effective policy training. Our theoretical analysis demonstrates that, under mild assumptions, strategies trained via EPO achieve performance comparable to optimal solutions with global constraint violations strictly remaining within a prescribed bound.
InstGenIE: Generative Image Editing Made Efficient with Mask-aware Caching and Scheduling
May 27, 2025
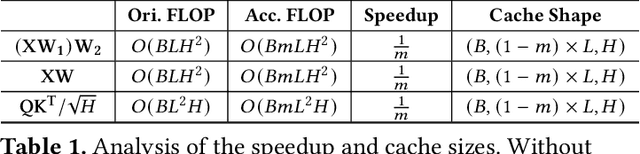
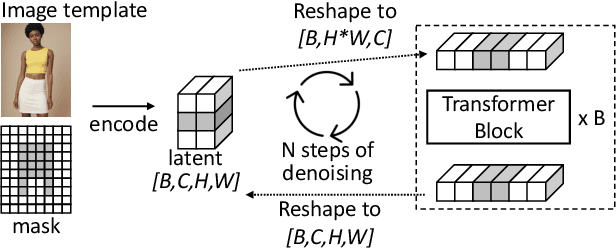
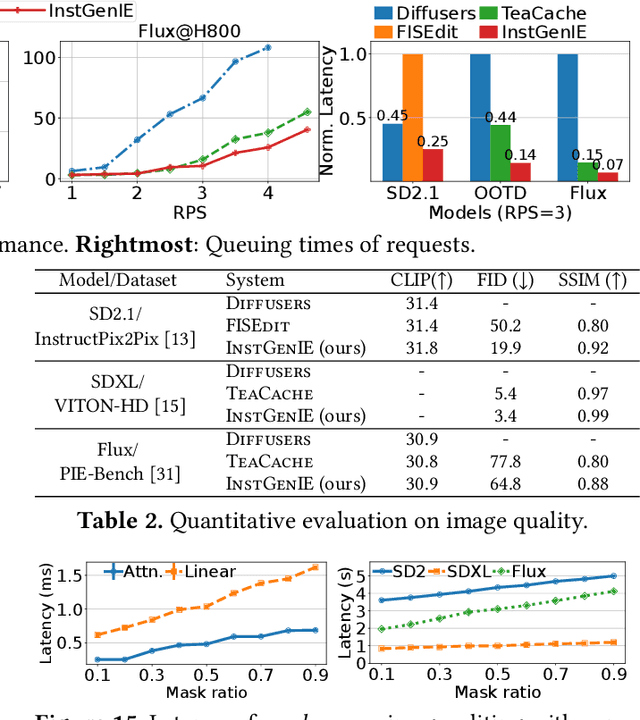
Generative image editing using diffusion models has become a prevalent application in today's AI cloud services. In production environments, image editing typically involves a mask that specifies the regions of an image template to be edited. The use of masks provides direct control over the editing process and introduces sparsity in the model inference. In this paper, we present InstGenIE, a system that efficiently serves image editing requests. The key insight behind InstGenIE is that image editing only modifies the masked regions of image templates while preserving the original content in the unmasked areas. Driven by this insight, InstGenIE judiciously skips redundant computations associated with the unmasked areas by reusing cached intermediate activations from previous inferences. To mitigate the high cache loading overhead, InstGenIE employs a bubble-free pipeline scheme that overlaps computation with cache loading. Additionally, to reduce queuing latency in online serving while improving the GPU utilization, InstGenIE proposes a novel continuous batching strategy for diffusion model serving, allowing newly arrived requests to join the running batch in just one step of denoising computation, without waiting for the entire batch to complete. As heterogeneous masks induce imbalanced loads, InstGenIE also develops a load balancing strategy that takes into account the loads of both computation and cache loading. Collectively, InstGenIE outperforms state-of-the-art diffusion serving systems for image editing, achieving up to 3x higher throughput and reducing average request latency by up to 14.7x while ensuring image quality.
MoEDiff-SR: Mixture of Experts-Guided Diffusion Model for Region-Adaptive MRI Super-Resolution
Apr 09, 2025



Magnetic Resonance Imaging (MRI) at lower field strengths (e.g., 3T) suffers from limited spatial resolution, making it challenging to capture fine anatomical details essential for clinical diagnosis and neuroimaging research. To overcome this limitation, we propose MoEDiff-SR, a Mixture of Experts (MoE)-guided diffusion model for region-adaptive MRI Super-Resolution (SR). Unlike conventional diffusion-based SR models that apply a uniform denoising process across the entire image, MoEDiff-SR dynamically selects specialized denoising experts at a fine-grained token level, ensuring region-specific adaptation and enhanced SR performance. Specifically, our approach first employs a Transformer-based feature extractor to compute multi-scale patch embeddings, capturing both global structural information and local texture details. The extracted feature embeddings are then fed into an MoE gating network, which assigns adaptive weights to multiple diffusion-based denoisers, each specializing in different brain MRI characteristics, such as centrum semiovale, sulcal and gyral cortex, and grey-white matter junction. The final output is produced by aggregating the denoised results from these specialized experts according to dynamically assigned gating probabilities. Experimental results demonstrate that MoEDiff-SR outperforms existing state-of-the-art methods in terms of quantitative image quality metrics, perceptual fidelity, and computational efficiency. Difference maps from each expert further highlight their distinct specializations, confirming the effective region-specific denoising capability and the interpretability of expert contributions. Additionally, clinical evaluation validates its superior diagnostic capability in identifying subtle pathological features, emphasizing its practical relevance in clinical neuroimaging. Our code is available at https://github.com/ZWang78/MoEDiff-SR.
Distillation-Driven Diffusion Model for Multi-Scale MRI Super-Resolution: Make 1.5T MRI Great Again
Jan 30, 2025



Magnetic Resonance Imaging (MRI) offers critical insights into microstructural details, however, the spatial resolution of standard 1.5T imaging systems is often limited. In contrast, 7T MRI provides significantly enhanced spatial resolution, enabling finer visualization of anatomical structures. Though this, the high cost and limited availability of 7T MRI hinder its widespread use in clinical settings. To address this challenge, a novel Super-Resolution (SR) model is proposed to generate 7T-like MRI from standard 1.5T MRI scans. Our approach leverages a diffusion-based architecture, incorporating gradient nonlinearity correction and bias field correction data from 7T imaging as guidance. Moreover, to improve deployability, a progressive distillation strategy is introduced. Specifically, the student model refines the 7T SR task with steps, leveraging feature maps from the inference phase of the teacher model as guidance, aiming to allow the student model to achieve progressively 7T SR performance with a smaller, deployable model size. Experimental results demonstrate that our baseline teacher model achieves state-of-the-art SR performance. The student model, while lightweight, sacrifices minimal performance. Furthermore, the student model is capable of accepting MRI inputs at varying resolutions without the need for retraining, significantly further enhancing deployment flexibility. The clinical relevance of our proposed method is validated using clinical data from Massachusetts General Hospital. Our code is available at https://github.com/ZWang78/SR.
Predictive Lagrangian Optimization for Constrained Reinforcement Learning
Jan 25, 2025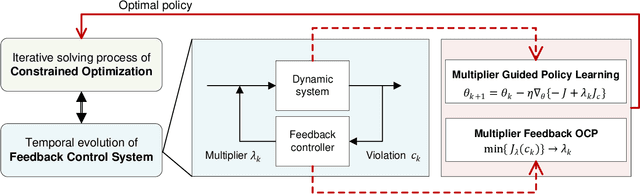
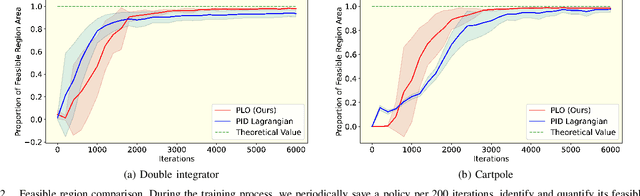
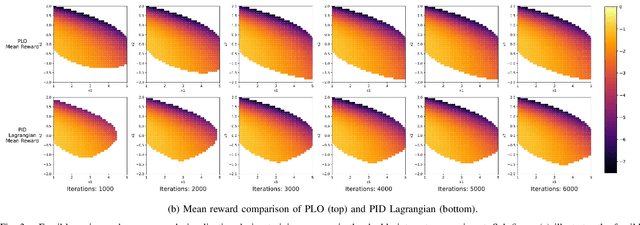

Constrained optimization is popularly seen in reinforcement learning for addressing complex control tasks. From the perspective of dynamic system, iteratively solving a constrained optimization problem can be framed as the temporal evolution of a feedback control system. Classical constrained optimization methods, such as penalty and Lagrangian approaches, inherently use proportional and integral feedback controllers. In this paper, we propose a more generic equivalence framework to build the connection between constrained optimization and feedback control system, for the purpose of developing more effective constrained RL algorithms. Firstly, we define that each step of the system evolution determines the Lagrange multiplier by solving a multiplier feedback optimal control problem (MFOCP). In this problem, the control input is multiplier, the state is policy parameters, the dynamics is described by policy gradient descent, and the objective is to minimize constraint violations. Then, we introduce a multiplier guided policy learning (MGPL) module to perform policy parameters updating. And we prove that the resulting optimal policy, achieved through alternating MFOCP and MGPL, aligns with the solution of the primal constrained RL problem, thereby establishing our equivalence framework. Furthermore, we point out that the existing PID Lagrangian is merely one special case within our framework that utilizes a PID controller. We also accommodate the integration of other various feedback controllers, thereby facilitating the development of new algorithms. As a representative, we employ model predictive control (MPC) as the feedback controller and consequently propose a new algorithm called predictive Lagrangian optimization (PLO). Numerical experiments demonstrate its superiority over the PID Lagrangian method, achieving a larger feasible region up to 7.2% and a comparable average reward.
Domain-conditioned and Temporal-guided Diffusion Modeling for Accelerated Dynamic MRI Reconstruction
Jan 16, 2025



Purpose: To propose a domain-conditioned and temporal-guided diffusion modeling method, termed dynamic Diffusion Modeling (dDiMo), for accelerated dynamic MRI reconstruction, enabling diffusion process to characterize spatiotemporal information for time-resolved multi-coil Cartesian and non-Cartesian data. Methods: The dDiMo framework integrates temporal information from time-resolved dimensions, allowing for the concurrent capture of intra-frame spatial features and inter-frame temporal dynamics in diffusion modeling. It employs additional spatiotemporal ($x$-$t$) and self-consistent frequency-temporal ($k$-$t$) priors to guide the diffusion process. This approach ensures precise temporal alignment and enhances the recovery of fine image details. To facilitate a smooth diffusion process, the nonlinear conjugate gradient algorithm is utilized during the reverse diffusion steps. The proposed model was tested on two types of MRI data: Cartesian-acquired multi-coil cardiac MRI and Golden-Angle-Radial-acquired multi-coil free-breathing lung MRI, across various undersampling rates. Results: dDiMo achieved high-quality reconstructions at various acceleration factors, demonstrating improved temporal alignment and structural recovery compared to other competitive reconstruction methods, both qualitatively and quantitatively. This proposed diffusion framework exhibited robust performance in handling both Cartesian and non-Cartesian acquisitions, effectively reconstructing dynamic datasets in cardiac and lung MRI under different imaging conditions. Conclusion: This study introduces a novel diffusion modeling method for dynamic MRI reconstruction.
SwiftDiffusion: Efficient Diffusion Model Serving with Add-on Modules
Jul 02, 2024



This paper documents our characterization study and practices for serving text-to-image requests with stable diffusion models in production. We first comprehensively analyze inference request traces for commercial text-to-image applications. It commences with our observation that add-on modules, i.e., ControlNets and LoRAs, that augment the base stable diffusion models, are ubiquitous in generating images for commercial applications. Despite their efficacy, these add-on modules incur high loading overhead, prolong the serving latency, and swallow up expensive GPU resources. Driven by our characterization study, we present SwiftDiffusion, a system that efficiently generates high-quality images using stable diffusion models and add-on modules. To achieve this, SwiftDiffusion reconstructs the existing text-to-image serving workflow by identifying the opportunities for parallel computation and distributing ControlNet computations across multiple GPUs. Further, SwiftDiffusion thoroughly analyzes the dynamics of image generation and develops techniques to eliminate the overhead associated with LoRA loading and patching while preserving the image quality. Last, SwiftDiffusion proposes specialized optimizations in the backbone architecture of the stable diffusion models, which are also compatible with the efficient serving of add-on modules. Compared to state-of-the-art text-to-image serving systems, SwiftDiffusion reduces serving latency by up to 5x and improves serving throughput by up to 2x without compromising image quality.