 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREMAC: Self-Reflective and Self-Evolving Multi-Agent Collaboration for Long-Horizon Robot Manipulation
Mar 28, 2025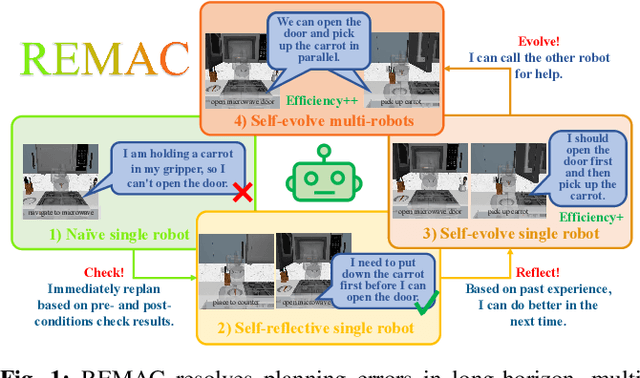
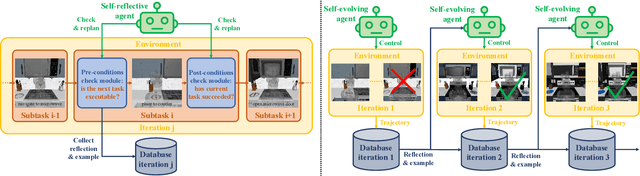
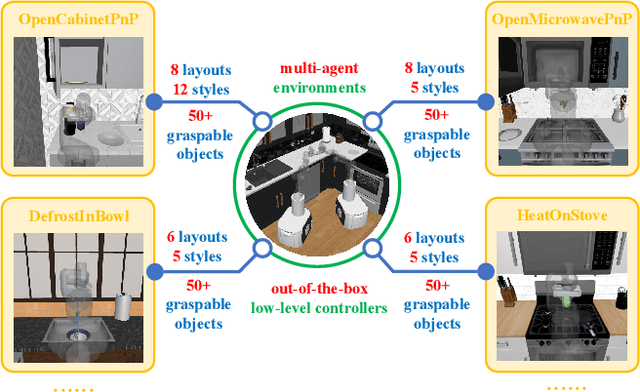
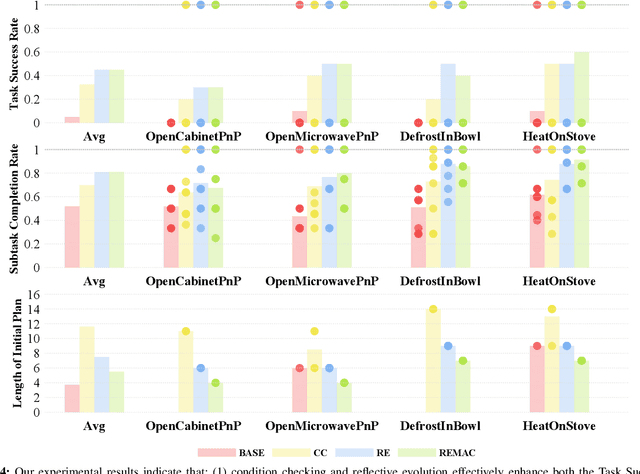
Vision-language models (VLMs) have demonstrated remarkable capabilities in robotic planning, particularly for long-horizon tasks that require a holistic understanding of the environment for task decomposition. Existing methods typically rely on prior environmental knowledge or carefully designed task-specific prompts, making them struggle with dynamic scene changes or unexpected task conditions, e.g., a robot attempting to put a carrot in the microwave but finds the door was closed. Such challenges underscore two critical issues: adaptability and efficiency. To address them, in this work, we propose an adaptive multi-agent planning framework, termed REMAC, that enables efficient, scene-agnostic multi-robot long-horizon task planning and execution through continuous reflection and self-evolution. REMAC incorporates two key modules: a self-reflection module performing pre-condition and post-condition checks in the loop to evaluate progress and refine plans, and a self-evolvement module dynamically adapting plans based on scene-specific reasoning. It offers several appealing benefits: 1) Robots can initially explore and reason about the environment without complex prompt design. 2) Robots can keep reflecting on potential planning errors and adapting the plan based on task-specific insights. 3) After iterations, a robot can call another one to coordinate tasks in parallel, maximizing the task execution efficiency. To validate REMAC's effectiveness, we build a multi-agent environment for long-horizon robot manipulation and navigation based on RoboCasa, featuring 4 task categories with 27 task styles and 50+ different objects. Based on it, we further benchmark state-of-the-art reasoning models, including DeepSeek-R1, o3-mini, QwQ, and Grok3, demonstrating REMAC's superiority by boosting average success rates by 40% and execution efficiency by 52.7% over the single robot baseline.
Predictive Lagrangian Optimization for Constrained Reinforcement Learning
Jan 25, 2025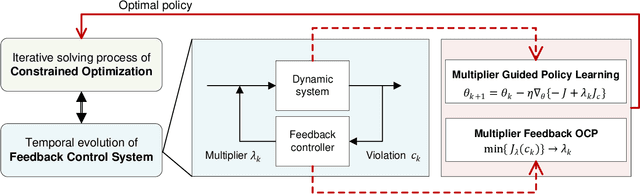
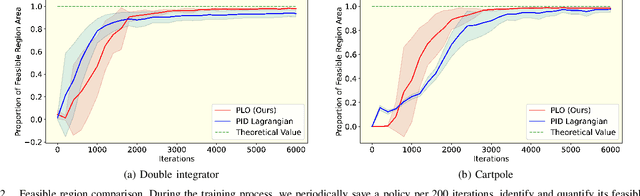
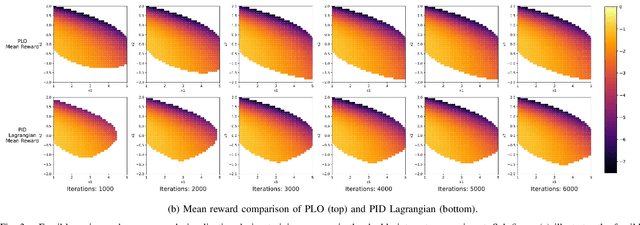

Constrained optimization is popularly seen in reinforcement learning for addressing complex control tasks. From the perspective of dynamic system, iteratively solving a constrained optimization problem can be framed as the temporal evolution of a feedback control system. Classical constrained optimization methods, such as penalty and Lagrangian approaches, inherently use proportional and integral feedback controllers. In this paper, we propose a more generic equivalence framework to build the connection between constrained optimization and feedback control system, for the purpose of developing more effective constrained RL algorithms. Firstly, we define that each step of the system evolution determines the Lagrange multiplier by solving a multiplier feedback optimal control problem (MFOCP). In this problem, the control input is multiplier, the state is policy parameters, the dynamics is described by policy gradient descent, and the objective is to minimize constraint violations. Then, we introduce a multiplier guided policy learning (MGPL) module to perform policy parameters updating. And we prove that the resulting optimal policy, achieved through alternating MFOCP and MGPL, aligns with the solution of the primal constrained RL problem, thereby establishing our equivalence framework. Furthermore, we point out that the existing PID Lagrangian is merely one special case within our framework that utilizes a PID controller. We also accommodate the integration of other various feedback controllers, thereby facilitating the development of new algorithms. As a representative, we employ model predictive control (MPC) as the feedback controller and consequently propose a new algorithm called predictive Lagrangian optimization (PLO). Numerical experiments demonstrate its superiority over the PID Lagrangian method, achieving a larger feasible region up to 7.2% and a comparable average reward.