 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJump-Start Reinforcement Learning with Self-Evolving Priors for Extreme Monopedal Locomotion
Jul 01, 2025Reinforcement learning (RL) has shown great potential in enabling quadruped robots to perform agile locomotion. However, directly training policies to simultaneously handle dual extreme challenges, i.e., extreme underactuation and extreme terrains, as in monopedal hopping tasks, remains highly challenging due to unstable early-stage interactions and unreliable reward feedback. To address this, we propose JumpER (jump-start reinforcement learning via self-evolving priors), an RL training framework that structures policy learning into multiple stages of increasing complexity. By dynamically generating self-evolving priors through iterative bootstrapping of previously learned policies, JumpER progressively refines and enhances guidance, thereby stabilizing exploration and policy optimization without relying on external expert priors or handcrafted reward shaping. Specifically, when integrated with a structured three-stage curriculum that incrementally evolves action modality, observation space, and task objective, JumpER enables quadruped robots to achieve robust monopedal hopping on unpredictable terrains for the first time. Remarkably, the resulting policy effectively handles challenging scenarios that traditional methods struggle to conquer, including wide gaps up to 60 cm, irregularly spaced stairs, and stepping stones with distances varying from 15 cm to 35 cm. JumpER thus provides a principled and scalable approach for addressing locomotion tasks under the dual challenges of extreme underactuation and extreme terrains.
Conversational Agents for Older Adults' Health: A Systematic Literature Review
Mar 29, 2025There has been vast literature that studies Conversational Agents (CAs) in facilitating older adults' health. The vast and diverse studies warrants a comprehensive review that concludes the main findings and proposes research directions for future studies, while few literature review did it from human-computer interaction (HCI) perspective. In this study, we present a survey of existing studies on CAs for older adults' health. Through a systematic review of 72 papers, this work reviewed previously studied older adults' characteristics and analyzed participants' experiences and expectations of CAs for health. We found that (1) Past research has an increasing interest on chatbots and voice assistants and applied CA as multiple roles in older adults' health. (2) Older adults mainly showed low acceptance CAs for health due to various reasons, such as unstable effects, harm to independence, and privacy concerns. (3) Older adults expect CAs to be able to support multiple functions, to communicate using natural language, to be personalized, and to allow users full control. We also discuss the implications based on the findings.
Predictive Lagrangian Optimization for Constrained Reinforcement Learning
Jan 25, 2025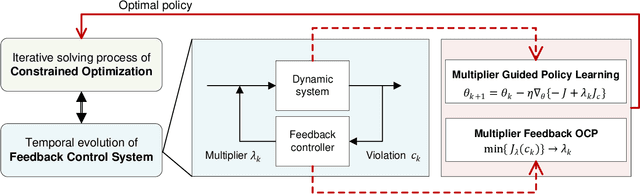
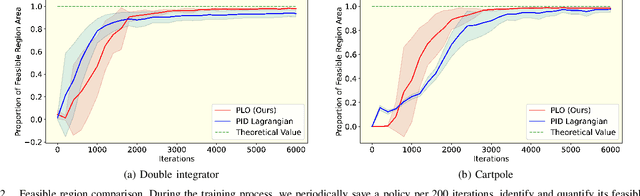
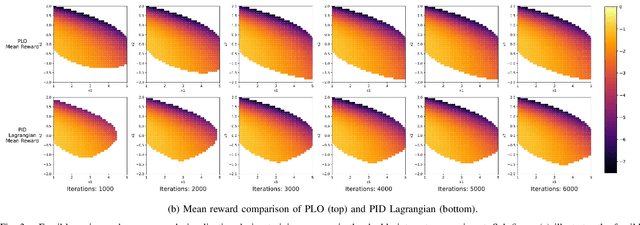

Constrained optimization is popularly seen in reinforcement learning for addressing complex control tasks. From the perspective of dynamic system, iteratively solving a constrained optimization problem can be framed as the temporal evolution of a feedback control system. Classical constrained optimization methods, such as penalty and Lagrangian approaches, inherently use proportional and integral feedback controllers. In this paper, we propose a more generic equivalence framework to build the connection between constrained optimization and feedback control system, for the purpose of developing more effective constrained RL algorithms. Firstly, we define that each step of the system evolution determines the Lagrange multiplier by solving a multiplier feedback optimal control problem (MFOCP). In this problem, the control input is multiplier, the state is policy parameters, the dynamics is described by policy gradient descent, and the objective is to minimize constraint violations. Then, we introduce a multiplier guided policy learning (MGPL) module to perform policy parameters updating. And we prove that the resulting optimal policy, achieved through alternating MFOCP and MGPL, aligns with the solution of the primal constrained RL problem, thereby establishing our equivalence framework. Furthermore, we point out that the existing PID Lagrangian is merely one special case within our framework that utilizes a PID controller. We also accommodate the integration of other various feedback controllers, thereby facilitating the development of new algorithms. As a representative, we employ model predictive control (MPC) as the feedback controller and consequently propose a new algorithm called predictive Lagrangian optimization (PLO). Numerical experiments demonstrate its superiority over the PID Lagrangian method, achieving a larger feasible region up to 7.2% and a comparable average reward.
Conformal Symplectic Optimization for Stable Reinforcement Learning
Dec 03, 2024



Training deep reinforcement learning (RL) agents necessitates overcoming the highly unstable nonconvex stochastic optimization inherent in the trial-and-error mechanism. To tackle this challenge, we propose a physics-inspired optimization algorithm called relativistic adaptive gradient descent (RAD), which enhances long-term training stability. By conceptualizing neural network (NN) training as the evolution of a conformal Hamiltonian system, we present a universal framework for transferring long-term stability from conformal symplectic integrators to iterative NN updating rules, where the choice of kinetic energy governs the dynamical properties of resulting optimization algorithms. By utilizing relativistic kinetic energy, RAD incorporates principles from special relativity and limits parameter updates below a finite speed, effectively mitigating abnormal gradient influences. Additionally, RAD models NN optimization as the evolution of a multi-particle system where each trainable parameter acts as an independent particle with an individual adaptive learning rate. We prove RAD's sublinear convergence under general nonconvex settings, where smaller gradient variance and larger batch sizes contribute to tighter convergence. Notably, RAD degrades to the well-known adaptive moment estimation (ADAM) algorithm when its speed coefficient is chosen as one and symplectic factor as a small positive value. Experimental results show RAD outperforming nine baseline optimizers with five RL algorithms across twelve environments, including standard benchmarks and challenging scenarios. Notably, RAD achieves up to a 155.1% performance improvement over ADAM in Atari games, showcasing its efficacy in stabilizing and accelerating RL training.
Using Large Language Models to Assist Video Content Analysis: An Exploratory Study of Short Videos on Depression
Jun 27, 2024


Despite the growing interest in leveraging Large Language Models (LLMs) for content analysis, current studies have primarily focused on text-based content. In the present work, we explored the potential of LLMs in assisting video content analysis by conducting a case study that followed a new workflow of LLM-assisted multimodal content analysis. The workflow encompasses codebook design, prompt engineering, LLM processing, and human evaluation. We strategically crafted annotation prompts to get LLM Annotations in structured form and explanation prompts to generate LLM Explanations for a better understanding of LLM reasoning and transparency. To test LLM's video annotation capabilities, we analyzed 203 keyframes extracted from 25 YouTube short videos about depression. We compared the LLM Annotations with those of two human coders and found that LLM has higher accuracy in object and activity Annotations than emotion and genre Annotations. Moreover, we identified the potential and limitations of LLM's capabilities in annotating videos. Based on the findings, we explore opportunities and challenges for future research and improvements to the workflow. We also discuss ethical concerns surrounding future studies based on LLM-assisted video analysis.
Policy Bifurcation in Safe Reinforcement Learning
Mar 28, 2024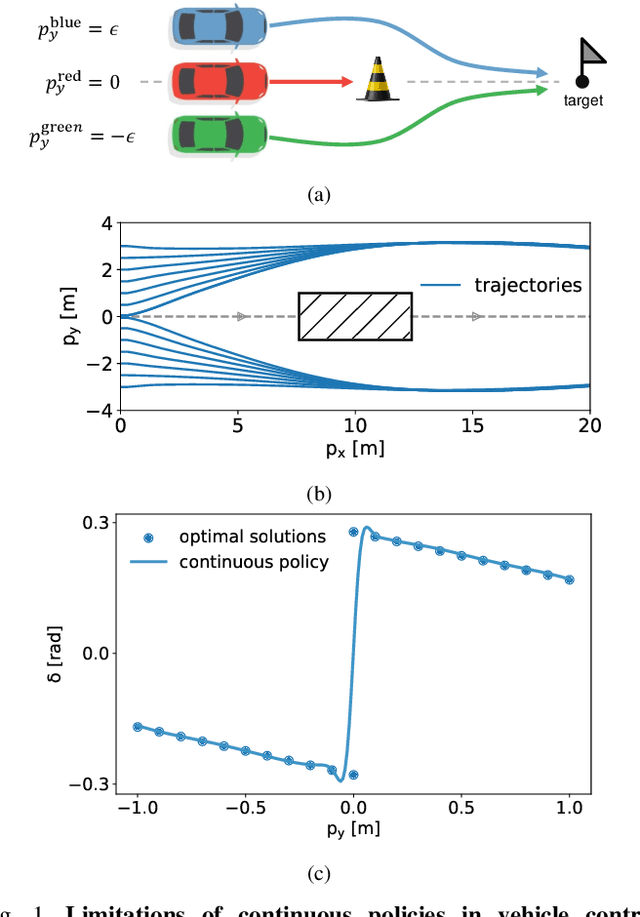
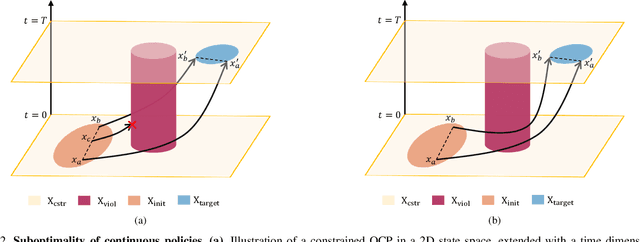
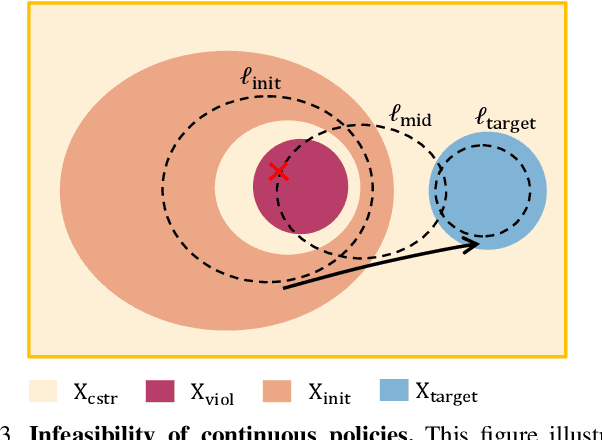
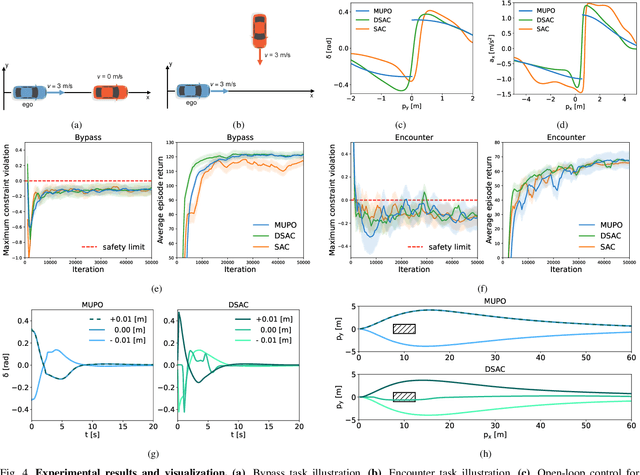
Safe reinforcement learning (RL) offers advanced solutions to constrained optimal control problems. Existing studies in safe RL implicitly assume continuity in policy functions, where policies map states to actions in a smooth, uninterrupted manner; however, our research finds that in some scenarios, the feasible policy should be discontinuous or multi-valued, interpolating between discontinuous local optima can inevitably lead to constraint violations. We are the first to identify the generating mechanism of such a phenomenon, and employ topological analysis to rigorously prove the existence of policy bifurcation in safe RL, which corresponds to the contractibility of the reachable tuple. Our theorem reveals that in scenarios where the obstacle-free state space is non-simply connected, a feasible policy is required to be bifurcated, meaning its output action needs to change abruptly in response to the varying state. To train such a bifurcated policy, we propose a safe RL algorithm called multimodal policy optimization (MUPO), which utilizes a Gaussian mixture distribution as the policy output. The bifurcated behavior can be achieved by selecting the Gaussian component with the highest mixing coefficient. Besides, MUPO also integrates spectral normalization and forward KL divergence to enhance the policy's capability of exploring different modes. Experiments with vehicle control tasks show that our algorithm successfully learns the bifurcated policy and ensures satisfying safety, while a continuous policy suffers from inevitable constraint violations.
A Preliminary Exploration of YouTubers' Use of Generative-AI in Content Creation
Mar 09, 2024



Content creators increasingly utilize generative artificial intelligence (Gen-AI) on platforms such as YouTube, TikTok, Instagram, and various blogging sites to produce imaginative images, AI-generated videos, and articles using Large Language Models (LLMs). Despite its growing popularity, there remains an underexplored area concerning the specific domains where AI-generated content is being applied, and the methodologies content creators employ with Gen-AI tools during the creation process. This study initially explores this emerging area through a qualitative analysis of 68 YouTube videos demonstrating Gen-AI usage. Our research focuses on identifying the content domains, the variety of tools used, the activities performed, and the nature of the final products generated by Gen-AI in the context of user-generated content.
Smoothing Policy Iteration for Zero-sum Markov Games
Dec 03, 2022



Zero-sum Markov Games (MGs) has been an efficient framework for multi-agent systems and robust control, wherein a minimax problem is constructed to solve the equilibrium policies. At present, this formulation is well studied under tabular settings wherein the maximum operator is primarily and exactly solved to calculate the worst-case value function. However, it is non-trivial to extend such methods to handle complex tasks, as finding the maximum over large-scale action spaces is usually cumbersome. In this paper, we propose the smoothing policy iteration (SPI) algorithm to solve the zero-sum MGs approximately, where the maximum operator is replaced by the weighted LogSumExp (WLSE) function to obtain the nearly optimal equilibrium policies. Specially, the adversarial policy is served as the weight function to enable an efficient sampling over action spaces.We also prove the convergence of SPI and analyze its approximation error in $\infty -$norm based on the contraction mapping theorem. Besides, we propose a model-based algorithm called Smooth adversarial Actor-critic (SaAC) by extending SPI with the function approximations. The target value related to WLSE function is evaluated by the sampled trajectories and then mean square error is constructed to optimize the value function, and the gradient-ascent-descent methods are adopted to optimize the protagonist and adversarial policies jointly. In addition, we incorporate the reparameterization technique in model-based gradient back-propagation to prevent the gradient vanishing due to sampling from the stochastic policies. We verify our algorithm in both tabular and function approximation settings. Results show that SPI can approximate the worst-case value function with a high accuracy and SaAC can stabilize the training process and improve the adversarial robustness in a large margin.
Symmetric Dilated Convolution for Surgical Gesture Recognition
Jul 14, 2020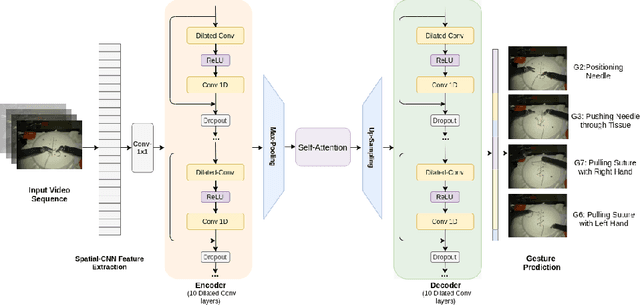
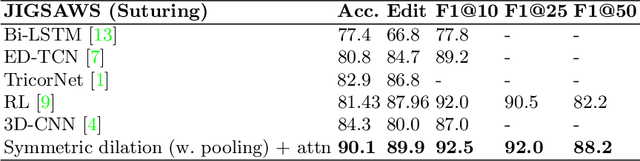
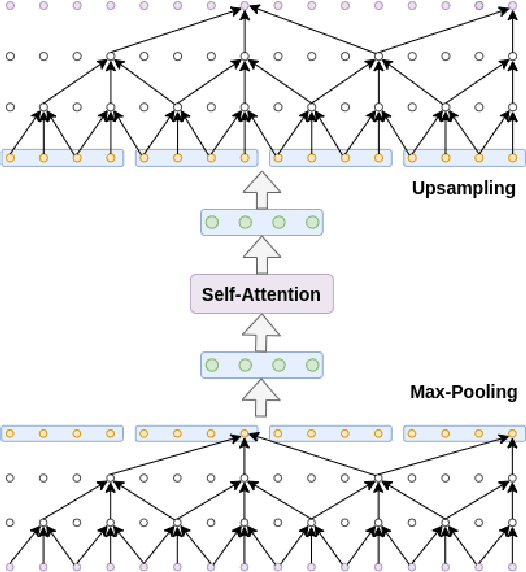
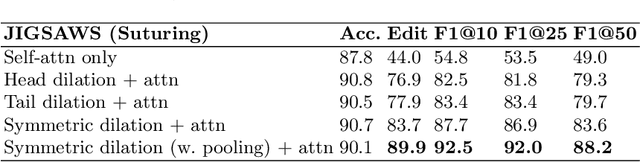
Automatic surgical gesture recognition is a prerequisite of intra-operative computer assistance and objective surgical skill assessment. Prior works either require additional sensors to collect kinematics data or have limitations on capturing temporal information from long and untrimmed surgical videos. To tackle these challenges, we propose a novel temporal convolutional architecture to automatically detect and segment surgical gestures with corresponding boundaries only using RGB videos. We devise our method with a symmetric dilation structure bridged by a self-attention module to encode and decode the long-term temporal patterns and establish the frame-to-frame relationship accordingly. We validate the effectiveness of our approach on a fundamental robotic suturing task from the JIGSAWS dataset. The experiment results demonstrate the ability of our method on capturing long-term frame dependencies, which largely outperform the state-of-the-art methods on the frame-wise accuracy up to ~6 points and the F1@50 score ~6 points.