 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Knowledge Distillation for Surgical Phase Recognition
Jun 15, 2023
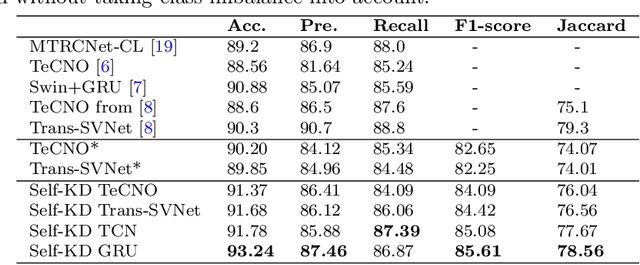


Purpose: Advances in surgical phase recognition are generally led by training deeper networks. Rather than going further with a more complex solution, we believe that current models can be exploited better. We propose a self-knowledge distillation framework that can be integrated into current state-of-the-art (SOTA) models without requiring any extra complexity to the models or annotations. Methods: Knowledge distillation is a framework for network regularization where knowledge is distilled from a teacher network to a student network. In self-knowledge distillation, the student model becomes the teacher such that the network learns from itself. Most phase recognition models follow an encoder-decoder framework. Our framework utilizes self-knowledge distillation in both stages. The teacher model guides the training process of the student model to extract enhanced feature representations from the encoder and build a more robust temporal decoder to tackle the over-segmentation problem. Results: We validate our proposed framework on the public dataset Cholec80. Our framework is embedded on top of four popular SOTA approaches and consistently improves their performance. Specifically, our best GRU model boosts performance by +3.33% accuracy and +3.95% F1-score over the same baseline model. Conclusion: We embed a self-knowledge distillation framework for the first time in the surgical phase recognition training pipeline. Experimental results demonstrate that our simple yet powerful framework can improve performance of existing phase recognition models. Moreover, our extensive experiments show that even with 75% of the training set we still achieve performance on par with the same baseline model trained on the full set.
Surgical Instruction Generation with Transformers
Jul 16, 2021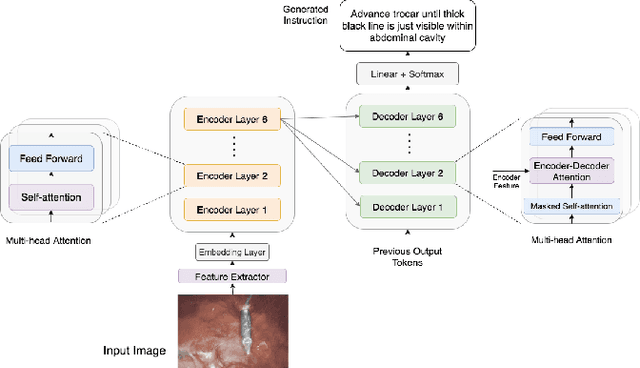
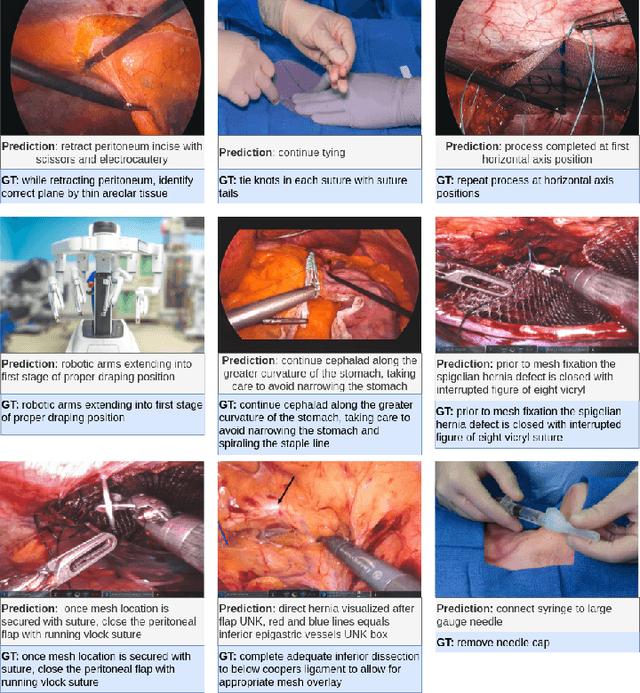
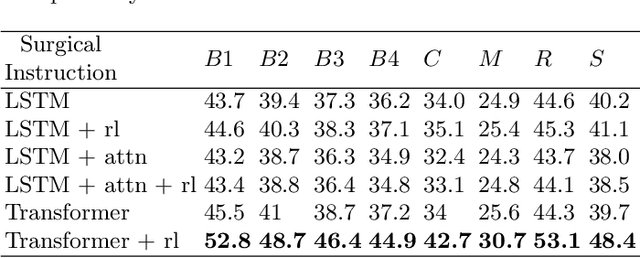
Automatic surgical instruction generation is a prerequisite towards intra-operative context-aware surgical assistance. However, generating instructions from surgical scenes is challenging, as it requires jointly understanding the surgical activity of current view and modelling relationships between visual information and textual description. Inspired by the neural machine translation and imaging captioning tasks in open domain, we introduce a transformer-backboned encoder-decoder network with self-critical reinforcement learning to generate instructions from surgical images. We evaluate the effectiveness of our method on DAISI dataset, which includes 290 procedures from various medical disciplines. Our approach outperforms the existing baseline over all caption evaluation metrics. The results demonstrate the benefits of the encoder-decoder structure backboned by transformer in handling multimodal context.
Symmetric Dilated Convolution for Surgical Gesture Recognition
Jul 14, 2020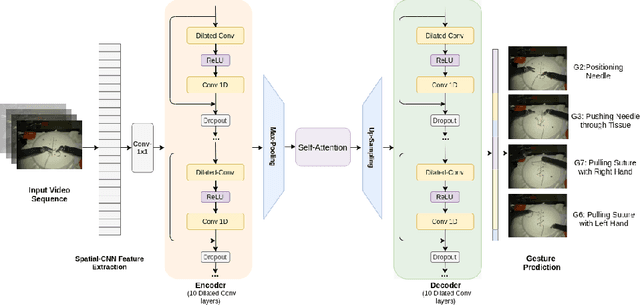
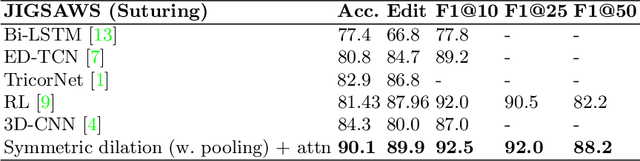
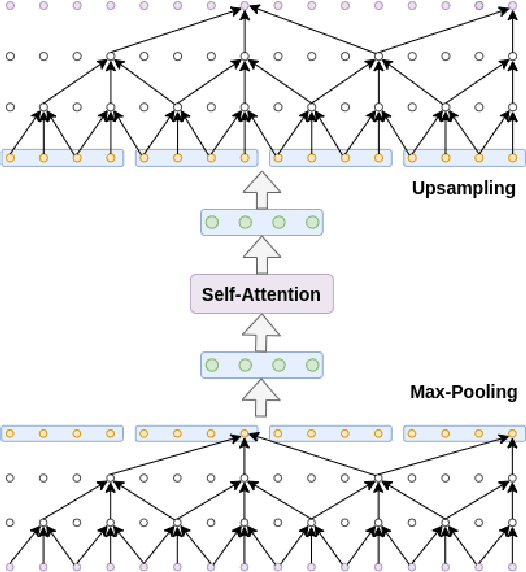
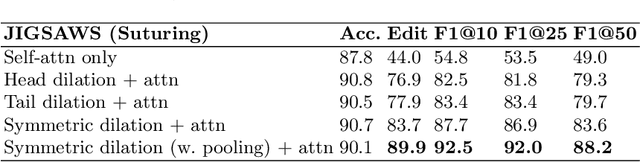
Automatic surgical gesture recognition is a prerequisite of intra-operative computer assistance and objective surgical skill assessment. Prior works either require additional sensors to collect kinematics data or have limitations on capturing temporal information from long and untrimmed surgical videos. To tackle these challenges, we propose a novel temporal convolutional architecture to automatically detect and segment surgical gestures with corresponding boundaries only using RGB videos. We devise our method with a symmetric dilation structure bridged by a self-attention module to encode and decode the long-term temporal patterns and establish the frame-to-frame relationship accordingly. We validate the effectiveness of our approach on a fundamental robotic suturing task from the JIGSAWS dataset. The experiment results demonstrate the ability of our method on capturing long-term frame dependencies, which largely outperform the state-of-the-art methods on the frame-wise accuracy up to ~6 points and the F1@50 score ~6 points.