 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundationPose-Initialized 3D-2D Liver Registration for Surgical Augmented Reality
Feb 19, 2026Augmented reality can improve tumor localization in laparoscopic liver surgery. Existing registration pipelines typically depend on organ contours; deformable (non-rigid) alignment is often handled with finite-element (FE) models coupled to dimensionality-reduction or machine-learning components. We integrate laparoscopic depth maps with a foundation pose estimator for camera-liver pose estimation and replace FE-based deformation with non-rigid iterative closest point (NICP) to lower engineering/modeling complexity and expertise requirements. On real patient data, the depth-augmented foundation pose approach achieved 9.91 mm mean registration error in 3 cases. Combined rigid-NICP registration outperformed rigid-only registration, demonstrating NICP as an efficient substitute for finite-element deformable models. This pipeline achieves clinically relevant accuracy while offering a lightweight, engineering-friendly alternative to FE-based deformation.
Self-Knowledge Distillation for Surgical Phase Recognition
Jun 15, 2023
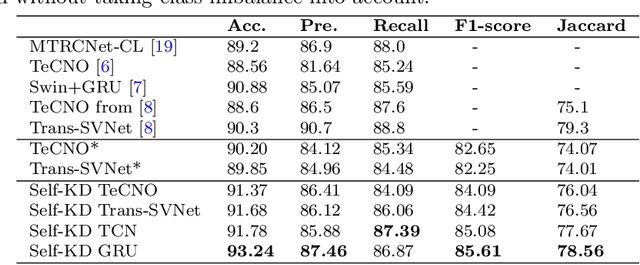


Purpose: Advances in surgical phase recognition are generally led by training deeper networks. Rather than going further with a more complex solution, we believe that current models can be exploited better. We propose a self-knowledge distillation framework that can be integrated into current state-of-the-art (SOTA) models without requiring any extra complexity to the models or annotations. Methods: Knowledge distillation is a framework for network regularization where knowledge is distilled from a teacher network to a student network. In self-knowledge distillation, the student model becomes the teacher such that the network learns from itself. Most phase recognition models follow an encoder-decoder framework. Our framework utilizes self-knowledge distillation in both stages. The teacher model guides the training process of the student model to extract enhanced feature representations from the encoder and build a more robust temporal decoder to tackle the over-segmentation problem. Results: We validate our proposed framework on the public dataset Cholec80. Our framework is embedded on top of four popular SOTA approaches and consistently improves their performance. Specifically, our best GRU model boosts performance by +3.33% accuracy and +3.95% F1-score over the same baseline model. Conclusion: We embed a self-knowledge distillation framework for the first time in the surgical phase recognition training pipeline. Experimental results demonstrate that our simple yet powerful framework can improve performance of existing phase recognition models. Moreover, our extensive experiments show that even with 75% of the training set we still achieve performance on par with the same baseline model trained on the full set.
Why is the winner the best?
Mar 30, 2023



International benchmarking competitions have become fundamental for the comparative performance assessment of image analysis methods. However, little attention has been given to investigating what can be learnt from these competitions. Do they really generate scientific progress? What are common and successful participation strategies? What makes a solution superior to a competing method? To address this gap in the literature, we performed a multi-center study with all 80 competitions that were conducted in the scope of IEEE ISBI 2021 and MICCAI 2021. Statistical analyses performed based on comprehensive descriptions of the submitted algorithms linked to their rank as well as the underlying participation strategies revealed common characteristics of winning solutions. These typically include the use of multi-task learning (63%) and/or multi-stage pipelines (61%), and a focus on augmentation (100%), image preprocessing (97%), data curation (79%), and postprocessing (66%). The "typical" lead of a winning team is a computer scientist with a doctoral degree, five years of experience in biomedical image analysis, and four years of experience in deep learning. Two core general development strategies stood out for highly-ranked teams: the reflection of the metrics in the method design and the focus on analyzing and handling failure cases. According to the organizers, 43% of the winning algorithms exceeded the state of the art but only 11% completely solved the respective domain problem. The insights of our study could help researchers (1) improve algorithm development strategies when approaching new problems, and (2) focus on open research questions revealed by this work.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
CaDIS: Cataract Dataset for Image Segmentation
Jul 19, 2019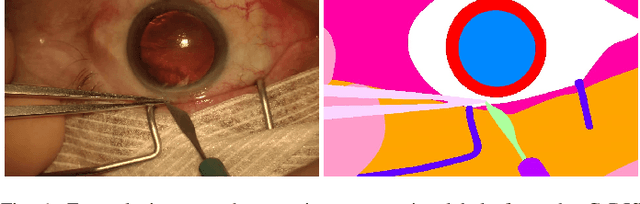
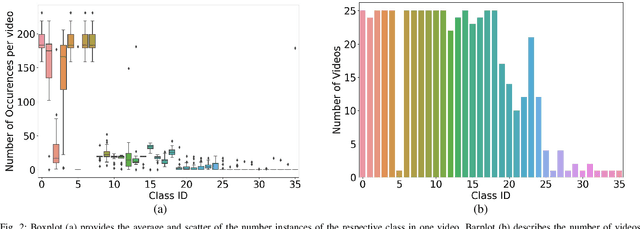
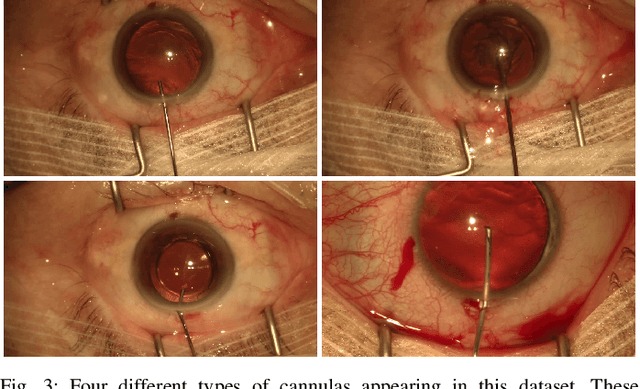

Video signals provide a wealth of information about surgical procedures and are the main sensory cue for surgeons. Video processing and understanding can be used to empower computer assisted interventions (CAI) as well as the development of detailed post-operative analysis of the surgical intervention. A fundamental building block to such capabilities is the ability to understand and segment video into semantic labels that differentiate and localize tissue types and different instruments. Deep learning has advanced semantic segmentation techniques dramatically in recent years but is fundamentally reliant on the availability of labelled datasets used to train models. In this paper, we introduce a high quality dataset for semantic segmentation in Cataract surgery. We generated this dataset from the CATARACTS challenge dataset, which is publicly available. To the best of our knowledge, this dataset has the highest quality annotation in surgical data to date. We introduce the dataset and then show the automatic segmentation performance of state-of-the-art models on that dataset as a benchmark.
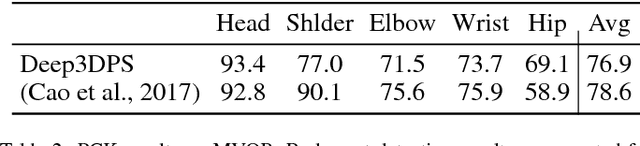
MVOR: A Multi-view RGB-D Operating Room Dataset for 2D and 3D Human Pose Estimation
Aug 24, 2018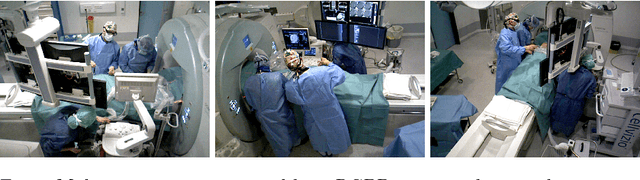
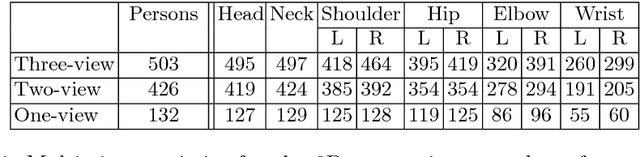
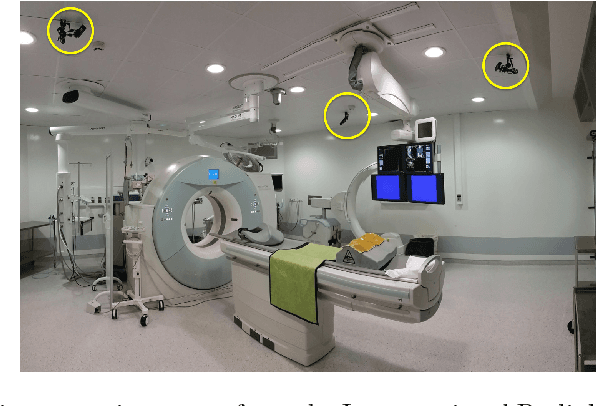
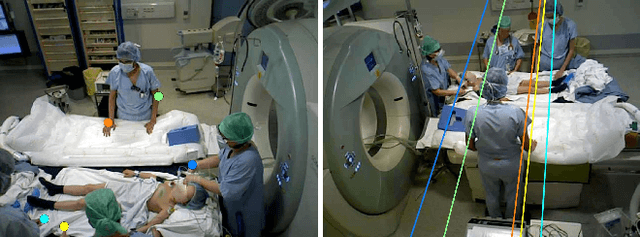
Person detection and pose estimation is a key requirement to develop intelligent context-aware assistance systems. To foster the development of human pose estimation methods and their applications in the Operating Room (OR), we release the Multi-View Operating Room (MVOR) dataset, the first public dataset recorded during real clinical interventions. It consists of 732 synchronized multi-view frames recorded by three RGB-D cameras in a hybrid OR. It also includes the visual challenges present in such environments, such as occlusions and clutter. We provide camera calibration parameters, color and depth frames, human bounding boxes, and 2D/3D pose annotations. In this paper, we present the dataset, its annotations, as well as baseline results from several recent person detection and 2D/3D pose estimation methods. Since we need to blur some parts of the images to hide identity and nudity in the released dataset, we also present a comparative study of how the baselines have been impacted by the blurring. Results show a large margin for improvement and suggest that the MVOR dataset can be useful to compare the performance of the different methods.
A generalizable approach for multi-view 3D human pose regression
Apr 27, 2018

Despite the significant improvement in the performance of monocular pose estimation approaches and their ability to generalize to unseen environments, multi-view (MV) approaches are often lagging behind in terms of accuracy and are specific to certain datasets. This is mainly due to the fact that (1) contrary to real world single-view (SV) datasets, MV datasets are often captured in controlled environments to collect precise 3D annotations, which do not cover all real world challenges, and (2) the model parameters are learned for specific camera setups. To alleviate these problems, we propose a two-stage approach to detect and estimate 3D human poses, which separates SV pose detection from MV 3D pose estimation. This separation enables us to utilize each dataset for the right task, i.e. SV datasets for constructing robust pose detection models and MV datasets for constructing precise MV 3D regression models. In addition, our 3D regression approach only requires 3D pose data and its projections to the views for building the model, hence removing the need for collecting annotated data from the test setup. Our approach can therefore be easily generalized to a new environment by simply projecting 3D poses into 2D during training according to the camera setup used at test time. As 2D poses are collected at test time using a SV pose detector, which might generate inaccurate detections, we model its characteristics and incorporate this information during training. We demonstrate that incorporating the detector's characteristics is important to build a robust 3D regression model and that the resulting regression model generalizes well to new MV environments. Our evaluation results show that our approach achieves competitive results on the Human3.6M dataset and significantly improves results on a MV clinical dataset that is the first MV dataset generated from live surgery recordings.
A Multi-view RGB-D Approach for Human Pose Estimation in Operating Rooms
Jan 25, 2017
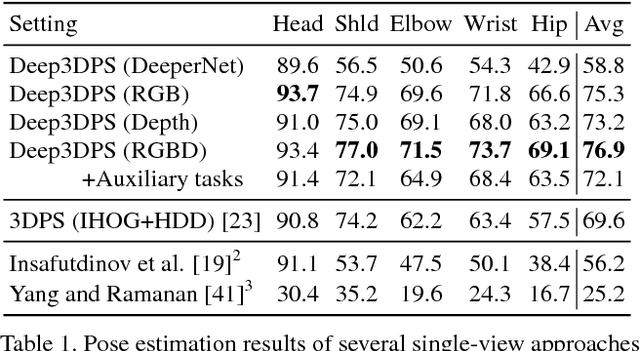


Many approaches have been proposed for human pose estimation in single and multi-view RGB images. However, some environments, such as the operating room, are still very challenging for state-of-the-art RGB methods. In this paper, we propose an approach for multi-view 3D human pose estimation from RGB-D images and demonstrate the benefits of using the additional depth channel for pose refinement beyond its use for the generation of improved features. The proposed method permits the joint detection and estimation of the poses without knowing a priori the number of persons present in the scene. We evaluate this approach on a novel multi-view RGB-D dataset acquired during live surgeries and annotated with ground truth 3D poses.
Articulated Clinician Detection Using 3D Pictorial Structures on RGB-D Data
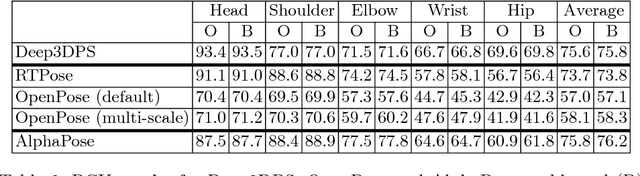
Jul 06, 2016



Reliable human pose estimation (HPE) is essential to many clinical applications, such as surgical workflow analysis, radiation safety monitoring and human-robot cooperation. Proposed methods for the operating room (OR) rely either on foreground estimation using a multi-camera system, which is a challenge in real ORs due to color similarities and frequent illumination changes, or on wearable sensors or markers, which are invasive and therefore difficult to introduce in the room. Instead, we propose a novel approach based on Pictorial Structures (PS) and on RGB-D data, which can be easily deployed in real ORs. We extend the PS framework in two ways. First, we build robust and discriminative part detectors using both color and depth images. We also present a novel descriptor for depth images, called histogram of depth differences (HDD). Second, we extend PS to 3D by proposing 3D pairwise constraints and a new method that makes exact inference tractable. Our approach is evaluated for pose estimation and clinician detection on a challenging RGB-D dataset recorded in a busy operating room during live surgeries. We conduct series of experiments to study the different part detectors in conjunction with the various 2D or 3D pairwise constraints. Our comparisons demonstrate that 3D PS with RGB-D part detectors significantly improves the results in a visually challenging operating environment.