 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised domain adaptation for clinician pose estimation and instance segmentation in the OR
Aug 26, 2021


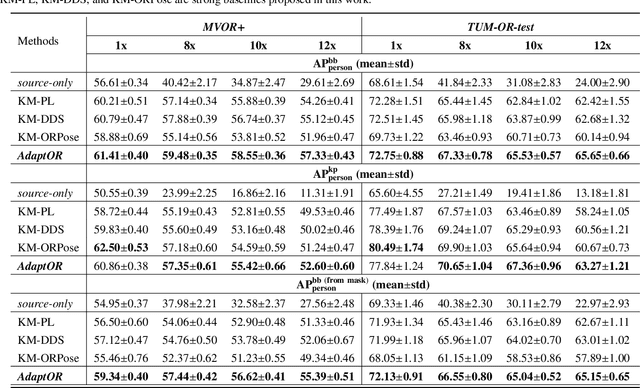
The fine-grained localization of clinicians in the operating room (OR) is a key component to design the new generation of OR support systems. Computer vision models for person pixel-based segmentation and body-keypoints detection are needed to better understand the clinical activities and the spatial layout of the OR. This is challenging, not only because OR images are very different from traditional vision datasets, but also because data and annotations are hard to collect and generate in the OR due to privacy concerns. To address these concerns, we first study how joint person pose estimation and instance segmentation can be performed on low resolutions images from 1x to 12x. Second, to address the domain shift and the lack of annotations, we propose a novel unsupervised domain adaptation method, called \emph{AdaptOR}, to adapt a model from an \emph{in-the-wild} labeled source domain to a statistically different unlabeled target domain. We propose to exploit explicit geometric constraints on the different augmentations of the unlabeled target domain image to generate accurate pseudo labels, and using these pseudo labels to train the model on high- and low-resolution OR images in a \emph{self-training} framework. Furthermore, we propose \emph{disentangled feature normalization} to handle the statistically different source and target domain data. Extensive experimental results with detailed ablation studies on the two OR datasets \emph{MVOR+} and \emph{TUM-OR-test} show the effectiveness of our approach against strongly constructed baselines, especially on the low-resolution privacy-preserving OR images. Finally, we show the generality of our method as a semi-supervised learning (SSL) method on the large-scale \emph{COCO} dataset, where we achieve comparable results with as few as \textbf{1\%} of labeled supervision against a model trained with 100\% labeled supervision.
Self-supervision on Unlabelled OR Data for Multi-person 2D/3D Human Pose Estimation
Jul 16, 2020



2D/3D human pose estimation is needed to develop novel intelligent tools for the operating room that can analyze and support the clinical activities. The lack of annotated data and the complexity of state-of-the-art pose estimation approaches limit, however, the deployment of such techniques inside the OR. In this work, we propose to use knowledge distillation in a teacher/student framework to harness the knowledge present in a large-scale non-annotated dataset and in an accurate but complex multi-stage teacher network to train a lightweight network for joint 2D/3D pose estimation. The teacher network also exploits the unlabeled data to generate both hard and soft labels useful in improving the student predictions. The easily deployable network trained using this effective self-supervision strategy performs on par with the teacher network on \emph{MVOR+}, an extension of the public MVOR dataset where all persons have been fully annotated, thus providing a viable solution for real-time 2D/3D human pose estimation in the OR.
Human Pose Estimation on Privacy-Preserving Low-Resolution Depth Images
Jul 16, 2020
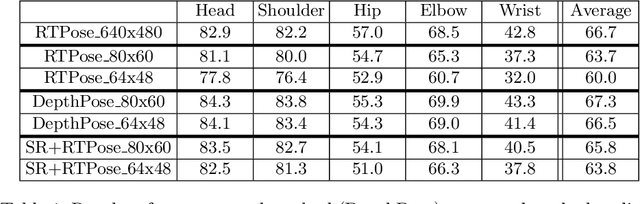
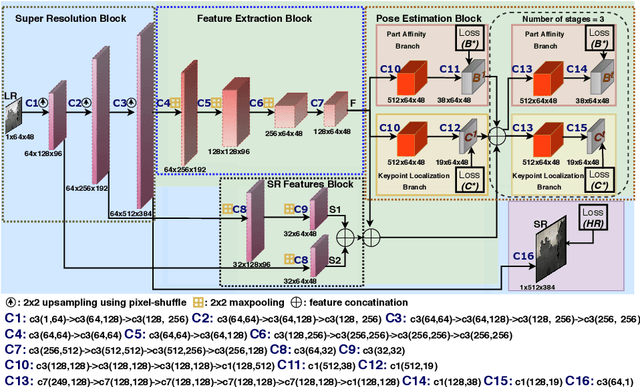

Human pose estimation (HPE) is a key building block for developing AI-based context-aware systems inside the operating room (OR). The 24/7 use of images coming from cameras mounted on the OR ceiling can however raise concerns for privacy, even in the case of depth images captured by RGB-D sensors. Being able to solely use low-resolution privacy-preserving images would address these concerns and help scale up the computer-assisted approaches that rely on such data to a larger number of ORs. In this paper, we introduce the problem of HPE on low-resolution depth images and propose an end-to-end solution that integrates a multi-scale super-resolution network with a 2D human pose estimation network. By exploiting intermediate feature-maps generated at different super-resolution, our approach achieves body pose results on low-resolution images (of size 64x48) that are on par with those of an approach trained and tested on full resolution images (of size 640x480).
* Published at MICCAI-2019
Face Detection in the Operating Room: Comparison of State-of-the-art Methods and a Self-supervised Approach
Dec 03, 2018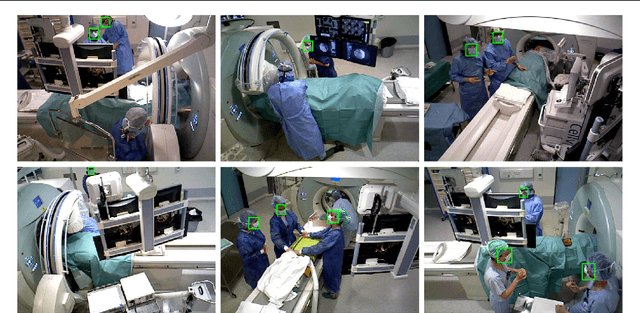
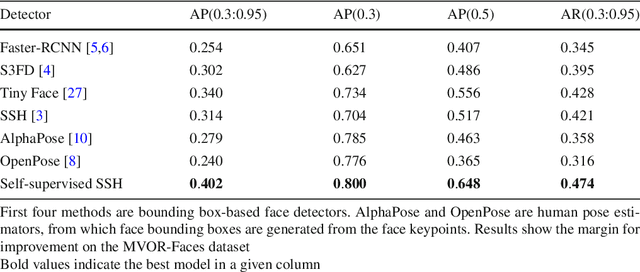

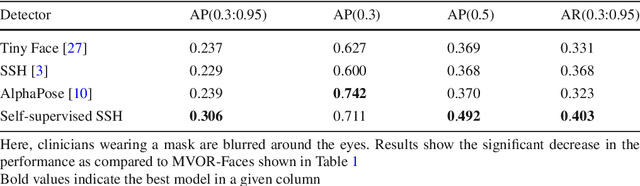
Purpose: Face detection is a needed component for the automatic analysis and assistance of human activities during surgical procedures. Efficient face detection algorithms can indeed help to detect and identify the persons present in the room, and also be used to automatically anonymize the data. However, current algorithms trained on natural images do not generalize well to the operating room (OR) images. In this work, we provide a comparison of state-of-the-art face detectors on OR data and also present an approach to train a face detector for the OR by exploiting non-annotated OR images. Methods: We propose a comparison of 6 state-of-the-art face detectors on clinical data using Multi-View Operating Room Faces (MVOR-Faces), a dataset of operating room images capturing real surgical activities. We then propose to use self-supervision, a domain adaptation method, for the task of face detection in the OR. The approach makes use of non-annotated images to fine-tune a state-of-the-art detector for the OR without using any human supervision. Results: The results show that the best model, namely the tiny face detector, yields an average precision of 0.536 at Intersection over Union (IoU) of 0.5. Our self-supervised model using non-annotated clinical data outperforms this result by 9.2%. Conclusion: We present the first comparison of state-of-the-art face detectors on operating room images and show that results can be significantly improved by using self-supervision on non-annotated data.
MVOR: A Multi-view RGB-D Operating Room Dataset for 2D and 3D Human Pose Estimation
Aug 24, 2018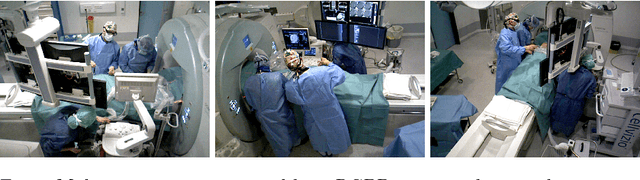
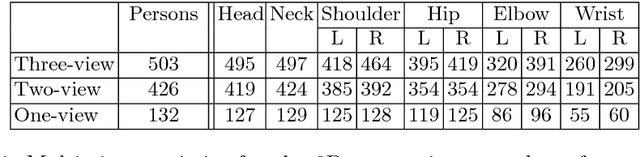
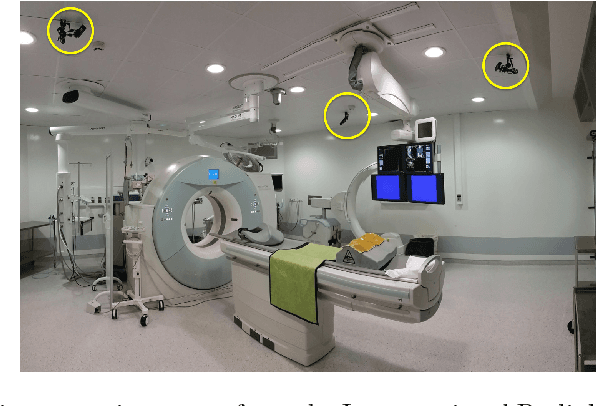
Person detection and pose estimation is a key requirement to develop intelligent context-aware assistance systems. To foster the development of human pose estimation methods and their applications in the Operating Room (OR), we release the Multi-View Operating Room (MVOR) dataset, the first public dataset recorded during real clinical interventions. It consists of 732 synchronized multi-view frames recorded by three RGB-D cameras in a hybrid OR. It also includes the visual challenges present in such environments, such as occlusions and clutter. We provide camera calibration parameters, color and depth frames, human bounding boxes, and 2D/3D pose annotations. In this paper, we present the dataset, its annotations, as well as baseline results from several recent person detection and 2D/3D pose estimation methods. Since we need to blur some parts of the images to hide identity and nudity in the released dataset, we also present a comparative study of how the baselines have been impacted by the blurring. Results show a large margin for improvement and suggest that the MVOR dataset can be useful to compare the performance of the different methods.
A Multi-view RGB-D Approach for Human Pose Estimation in Operating Rooms
Jan 25, 2017


Many approaches have been proposed for human pose estimation in single and multi-view RGB images. However, some environments, such as the operating room, are still very challenging for state-of-the-art RGB methods. In this paper, we propose an approach for multi-view 3D human pose estimation from RGB-D images and demonstrate the benefits of using the additional depth channel for pose refinement beyond its use for the generation of improved features. The proposed method permits the joint detection and estimation of the poses without knowing a priori the number of persons present in the scene. We evaluate this approach on a novel multi-view RGB-D dataset acquired during live surgeries and annotated with ground truth 3D poses.
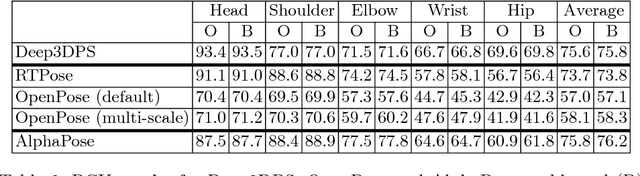
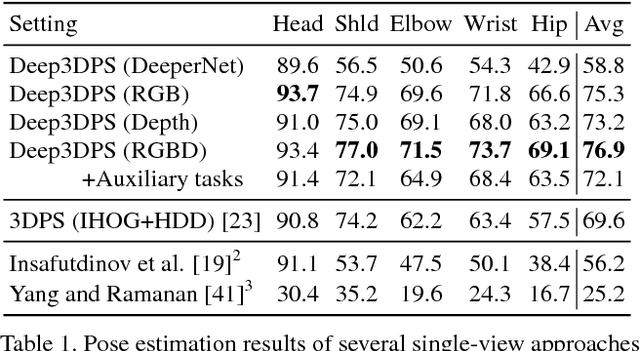
Articulated Clinician Detection Using 3D Pictorial Structures on RGB-D Data
Jul 06, 2016



Reliable human pose estimation (HPE) is essential to many clinical applications, such as surgical workflow analysis, radiation safety monitoring and human-robot cooperation. Proposed methods for the operating room (OR) rely either on foreground estimation using a multi-camera system, which is a challenge in real ORs due to color similarities and frequent illumination changes, or on wearable sensors or markers, which are invasive and therefore difficult to introduce in the room. Instead, we propose a novel approach based on Pictorial Structures (PS) and on RGB-D data, which can be easily deployed in real ORs. We extend the PS framework in two ways. First, we build robust and discriminative part detectors using both color and depth images. We also present a novel descriptor for depth images, called histogram of depth differences (HDD). Second, we extend PS to 3D by proposing 3D pairwise constraints and a new method that makes exact inference tractable. Our approach is evaluated for pose estimation and clinician detection on a challenging RGB-D dataset recorded in a busy operating room during live surgeries. We conduct series of experiments to study the different part detectors in conjunction with the various 2D or 3D pairwise constraints. Our comparisons demonstrate that 3D PS with RGB-D part detectors significantly improves the results in a visually challenging operating environment.