 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Consistency Models with Generator-Induced Coupling
Jun 13, 2024



Consistency models are promising generative models as they distill the multi-step sampling of score-based diffusion in a single forward pass of a neural network. Without access to sampling trajectories of a pre-trained diffusion model, consistency training relies on proxy trajectories built on an independent coupling between the noise and data distributions. Refining this coupling is a key area of improvement to make it more adapted to the task and reduce the resulting randomness in the training process. In this work, we introduce a novel coupling associating the input noisy data with their generated output from the consistency model itself, as a proxy to the inaccessible diffusion flow output. Our affordable approach exploits the inherent capacity of consistency models to compute the transport map in a single step. We provide intuition and empirical evidence of the relevance of our generator-induced coupling (GC), which brings consistency training closer to score distillation. Consequently, our method not only accelerates consistency training convergence by significant amounts but also enhances the resulting performance. The code is available at: https://github.com/thibautissenhuth/consistency_GC.
Unifying GANs and Score-Based Diffusion as Generative Particle Models
May 25, 2023Particle-based deep generative models, such as gradient flows and score-based diffusion models, have recently gained traction thanks to their striking performance. Their principle of displacing particle distributions by differential equations is conventionally seen as opposed to the previously widespread generative adversarial networks (GANs), which involve training a pushforward generator network. In this paper, we challenge this interpretation and propose a novel framework that unifies particle and adversarial generative models by framing generator training as a generalization of particle models. This suggests that a generator is an optional addition to any such generative model. Consequently, integrating a generator into a score-based diffusion model and training a GAN without a generator naturally emerge from our framework. We empirically test the viability of these original models as proofs of concepts of potential applications of our framework.
Optimal precision for GANs
Jul 21, 2022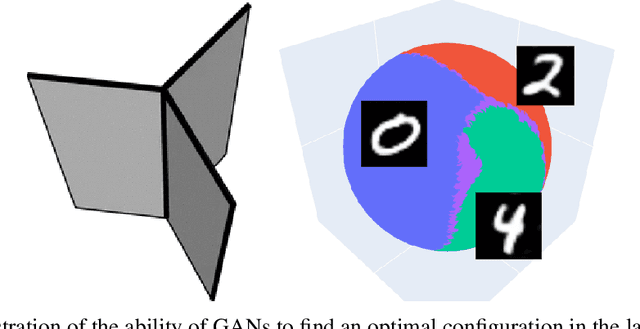


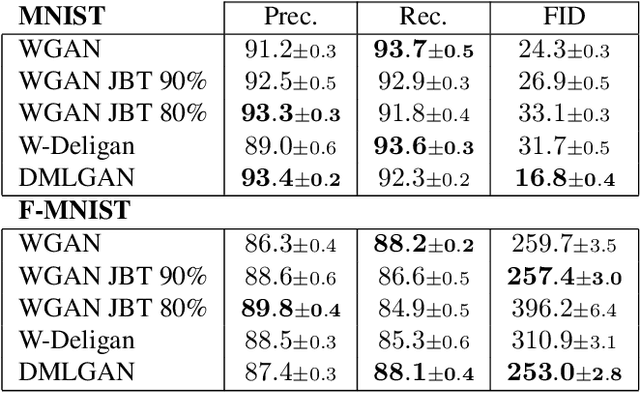
When learning disconnected distributions, Generative adversarial networks (GANs) are known to face model misspecification. Indeed, a continuous mapping from a unimodal latent distribution to a disconnected one is impossible, so GANs necessarily generate samples outside of the support of the target distribution. This raises a fundamental question: what is the latent space partition that minimizes the measure of these areas? Building on a recent result of geometric measure theory, we prove that an optimal GANs must structure its latent space as a 'simplicial cluster' - a Voronoi partition where cells are convex cones - when the dimension of the latent space is larger than the number of modes. In this configuration, each Voronoi cell maps to a distinct mode of the data. We derive both an upper and a lower bound on the optimal precision of GANs learning disconnected manifolds. Interestingly, these two bounds have the same order of decrease: $\sqrt{\log m}$, $m$ being the number of modes. Finally, we perform several experiments to exhibit the geometry of the latent space and experimentally show that GANs have a geometry with similar properties to the theoretical one.
EdiBERT, a generative model for image editing
Nov 30, 2021
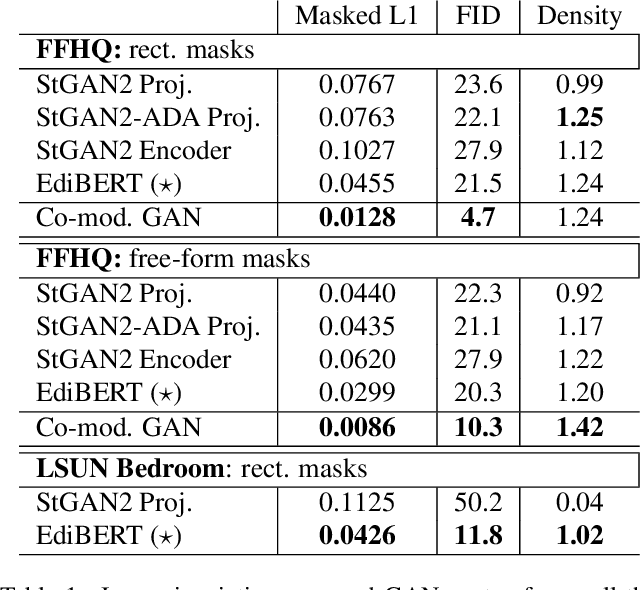

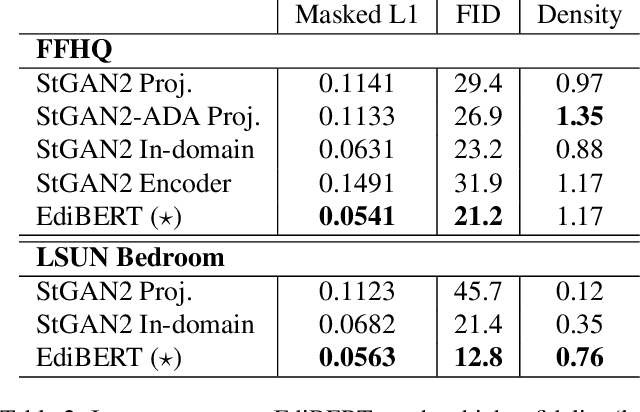
Advances in computer vision are pushing the limits of im-age manipulation, with generative models sampling detailed images on various tasks. However, a specialized model is often developed and trained for each specific task, even though many image edition tasks share similarities. In denoising, inpainting, or image compositing, one always aims at generating a realistic image from a low-quality one. In this paper, we aim at making a step towards a unified approach for image editing. To do so, we propose EdiBERT, a bi-directional transformer trained in the discrete latent space built by a vector-quantized auto-encoder. We argue that such a bidirectional model is suited for image manipulation since any patch can be re-sampled conditionally to the whole image. Using this unique and straightforward training objective, we show that the resulting model matches state-of-the-art performances on a wide variety of tasks: image denoising, image completion, and image composition.
Latent reweighting, an almost free improvement for GANs
Oct 19, 2021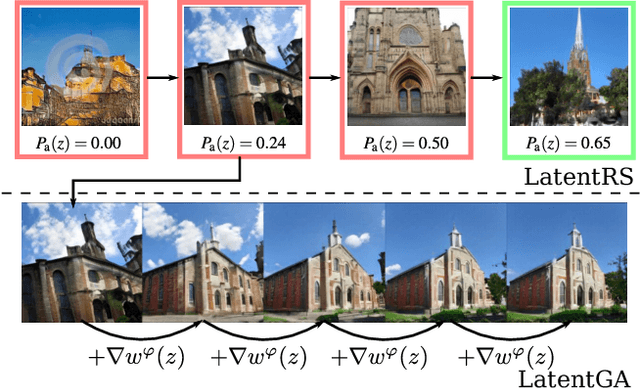
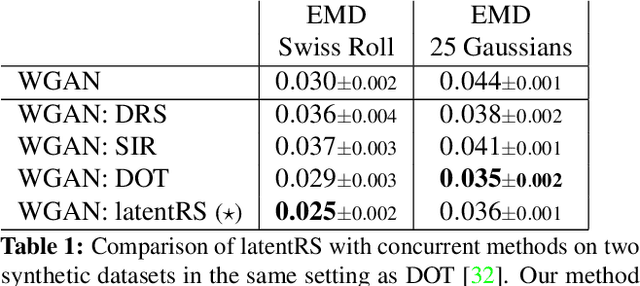
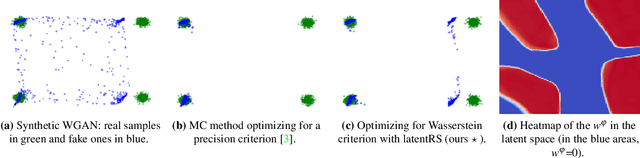
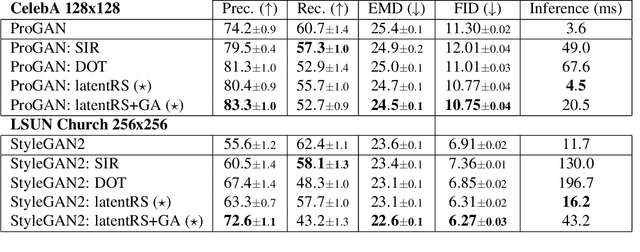
Standard formulations of GANs, where a continuous function deforms a connected latent space, have been shown to be misspecified when fitting different classes of images. In particular, the generator will necessarily sample some low-quality images in between the classes. Rather than modifying the architecture, a line of works aims at improving the sampling quality from pre-trained generators at the expense of increased computational cost. Building on this, we introduce an additional network to predict latent importance weights and two associated sampling methods to avoid the poorest samples. This idea has several advantages: 1) it provides a way to inject disconnectedness into any GAN architecture, 2) since the rejection happens in the latent space, it avoids going through both the generator and the discriminator, saving computation time, 3) this importance weights formulation provides a principled way to reduce the Wasserstein's distance to the target distribution. We demonstrate the effectiveness of our method on several datasets, both synthetic and high-dimensional.
Do Not Mask What You Do Not Need to Mask: a Parser-Free Virtual Try-On
Jul 03, 2020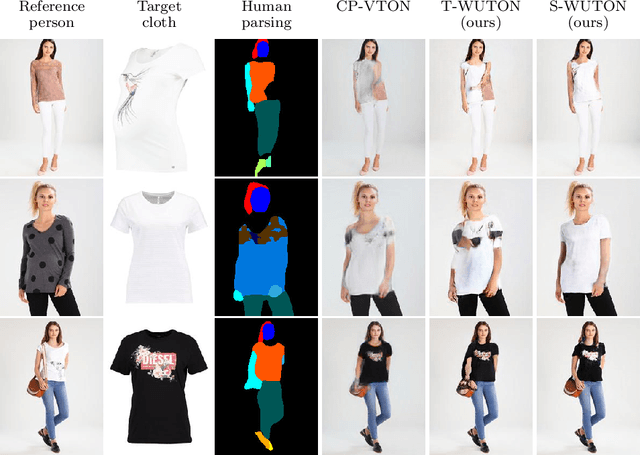
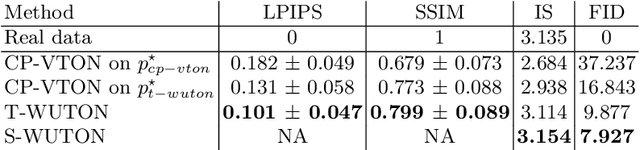

The 2D virtual try-on task has recently attracted a great interest from the research community, for its direct potential applications in online shopping as well as for its inherent and non-addressed scientific challenges. This task requires fitting an in-shop cloth image on the image of a person, which is highly challenging because it involves cloth warping, image compositing, and synthesizing. Casting virtual try-on into a supervised task faces a difficulty: available datasets are composed of pairs of pictures (cloth, person wearing the cloth). Thus, we have no access to ground-truth when the cloth on the person changes. State-of-the-art models solve this by masking the cloth information on the person with both a human parser and a pose estimator. Then, image synthesis modules are trained to reconstruct the person image from the masked person image and the cloth image. This procedure has several caveats: firstly, human parsers are prone to errors; secondly, it is a costly pre-processing step, which also has to be applied at inference time; finally, it makes the task harder than it is since the mask covers information that should be kept such as hands or accessories. In this paper, we propose a novel student-teacher paradigm where the teacher is trained in the standard way (reconstruction) before guiding the student to focus on the initial task (changing the cloth). The student additionally learns from an adversarial loss, which pushes it to follow the distribution of the real images. Consequently, the student exploits information that is masked to the teacher. A student trained without the adversarial loss would not use this information. Also, getting rid of both human parser and pose estimator at inference time allows obtaining a real-time virtual try-on.
Learning disconnected manifolds: a no GANs land
Jun 22, 2020
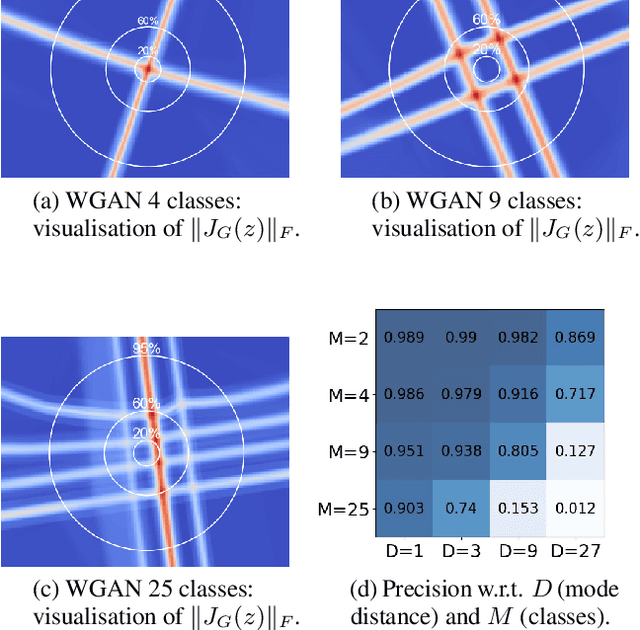
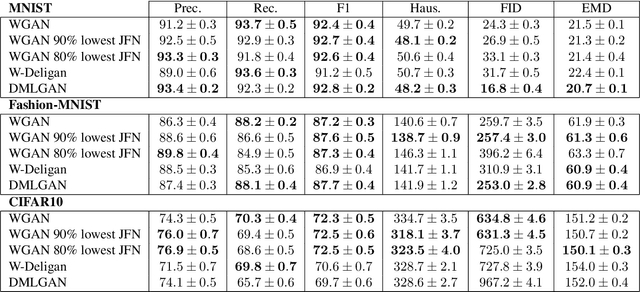
Typical architectures of Generative AdversarialNetworks make use of a unimodal latent distribution transformed by a continuous generator. Consequently, the modeled distribution always has connected support which is cumbersome when learning a disconnected set of manifolds. We formalize this problem by establishing a no free lunch theorem for the disconnected manifold learning stating an upper bound on the precision of the targeted distribution. This is done by building on the necessary existence of a low-quality region where the generator continuously samples data between two disconnected modes. Finally, we derive a rejection sampling method based on the norm of generators Jacobian and show its efficiency on several generators including BigGAN.
End-to-End Learning of Geometric Deformations of Feature Maps for Virtual Try-On
Jun 10, 2019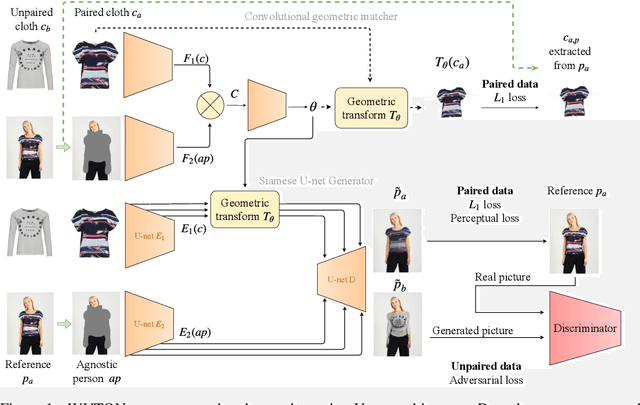



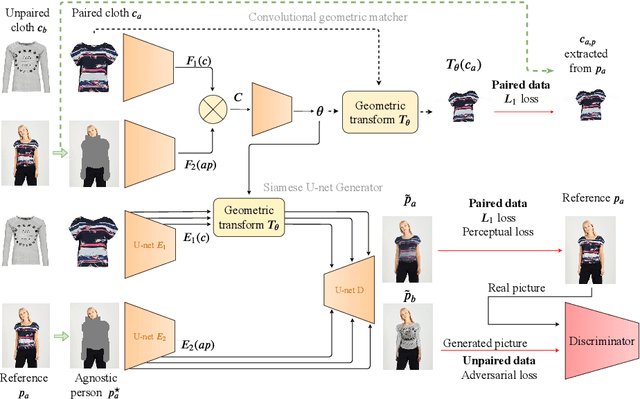
The 2D virtual try-on task has recently attracted a lot of interest from the research community, for its direct potential applications in online shopping as well as for its inherent and non-addressed scientific challenges. This task requires to fit an in-shop cloth image on the image of a person. It is highly challenging because it requires to warp the cloth on the target person while preserving its patterns and characteristics, and to compose the item with the person in a realistic manner. Current state-of-the-art models generate images with visible artifacts, due either to a pixel-level composition step or to the geometric transformation. In this paper, we propose WUTON: a Warping U-net for a Virtual Try-On system. It is a siamese U-net generator whose skip connections are geometrically transformed by a convolutional geometric matcher. The whole architecture is trained end-to-end with a multi-task loss including an adversarial one. This enables our network to generate and use realistic spatial transformations of the cloth to synthesize images of high visual quality. The proposed architecture can be trained end-to-end and allows us to advance towards a detail-preserving and photo-realistic 2D virtual try-on system. Our method outperforms the current state-of-the-art with visual results as well as with the Learned Perceptual Image Similarity (LPIPS) metric.
Face Detection in the Operating Room: Comparison of State-of-the-art Methods and a Self-supervised Approach
Dec 03, 2018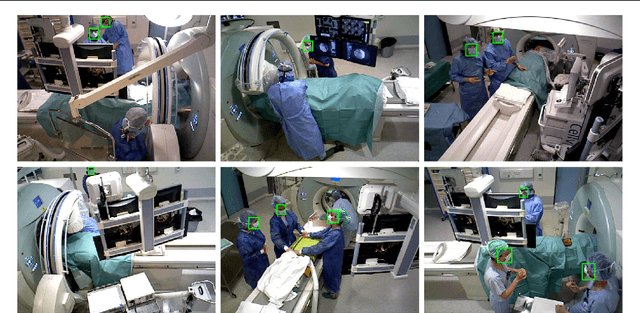
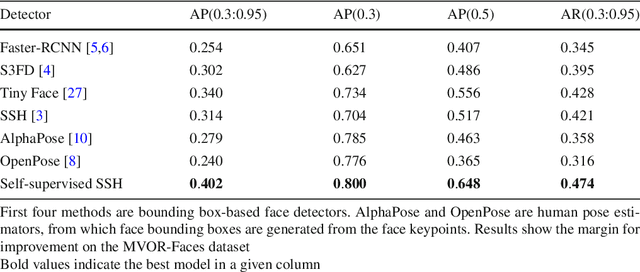

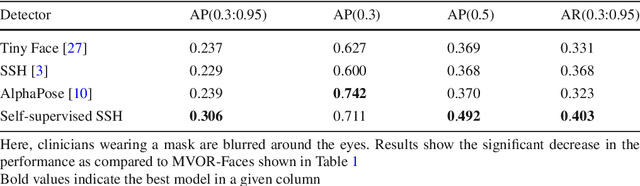
Purpose: Face detection is a needed component for the automatic analysis and assistance of human activities during surgical procedures. Efficient face detection algorithms can indeed help to detect and identify the persons present in the room, and also be used to automatically anonymize the data. However, current algorithms trained on natural images do not generalize well to the operating room (OR) images. In this work, we provide a comparison of state-of-the-art face detectors on OR data and also present an approach to train a face detector for the OR by exploiting non-annotated OR images. Methods: We propose a comparison of 6 state-of-the-art face detectors on clinical data using Multi-View Operating Room Faces (MVOR-Faces), a dataset of operating room images capturing real surgical activities. We then propose to use self-supervision, a domain adaptation method, for the task of face detection in the OR. The approach makes use of non-annotated images to fine-tune a state-of-the-art detector for the OR without using any human supervision. Results: The results show that the best model, namely the tiny face detector, yields an average precision of 0.536 at Intersection over Union (IoU) of 0.5. Our self-supervised model using non-annotated clinical data outperforms this result by 9.2%. Conclusion: We present the first comparison of state-of-the-art face detectors on operating room images and show that results can be significantly improved by using self-supervision on non-annotated data.
MVOR: A Multi-view RGB-D Operating Room Dataset for 2D and 3D Human Pose Estimation
Aug 24, 2018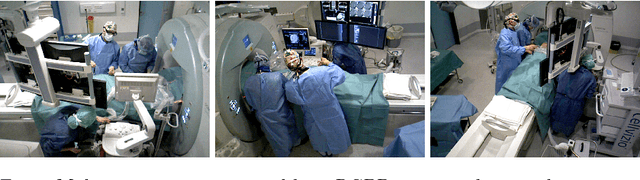
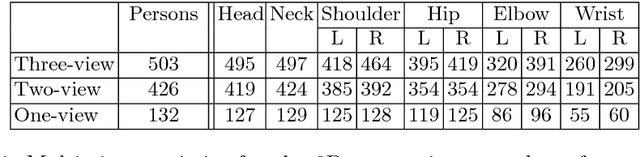
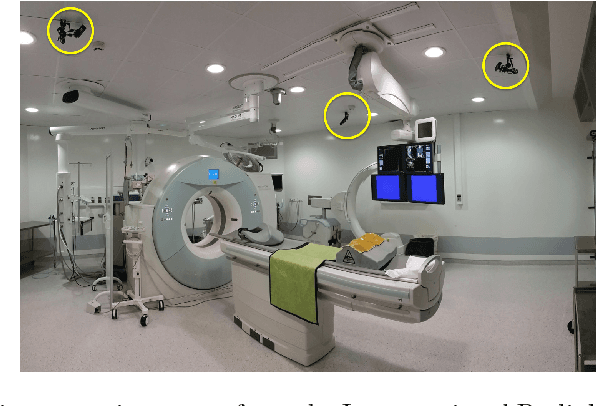
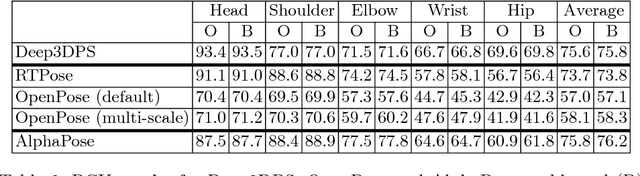
Person detection and pose estimation is a key requirement to develop intelligent context-aware assistance systems. To foster the development of human pose estimation methods and their applications in the Operating Room (OR), we release the Multi-View Operating Room (MVOR) dataset, the first public dataset recorded during real clinical interventions. It consists of 732 synchronized multi-view frames recorded by three RGB-D cameras in a hybrid OR. It also includes the visual challenges present in such environments, such as occlusions and clutter. We provide camera calibration parameters, color and depth frames, human bounding boxes, and 2D/3D pose annotations. In this paper, we present the dataset, its annotations, as well as baseline results from several recent person detection and 2D/3D pose estimation methods. Since we need to blur some parts of the images to hide identity and nudity in the released dataset, we also present a comparative study of how the baselines have been impacted by the blurring. Results show a large margin for improvement and suggest that the MVOR dataset can be useful to compare the performance of the different methods.