 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnnealed Winner-Takes-All for Motion Forecasting
Sep 18, 2024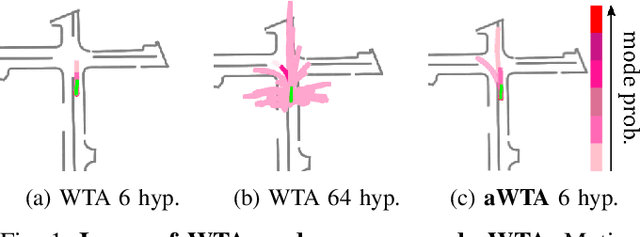
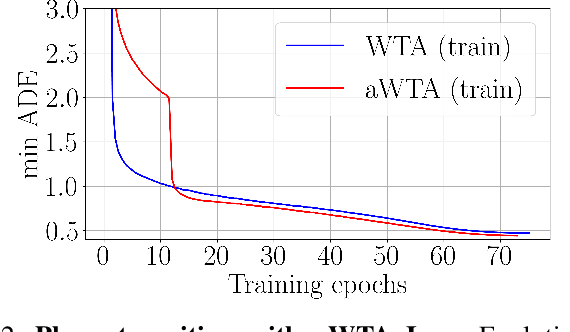
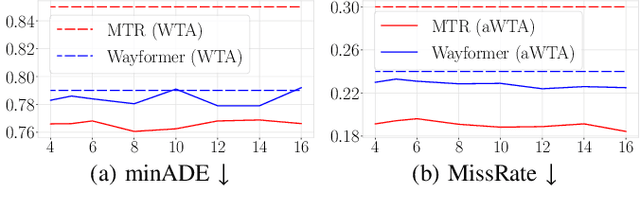
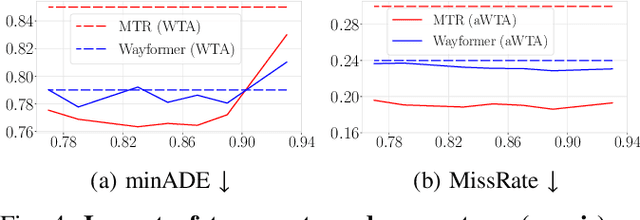
In autonomous driving, motion prediction aims at forecasting the future trajectories of nearby agents, helping the ego vehicle to anticipate behaviors and drive safely. A key challenge is generating a diverse set of future predictions, commonly addressed using data-driven models with Multiple Choice Learning (MCL) architectures and Winner-Takes-All (WTA) training objectives. However, these methods face initialization sensitivity and training instabilities. Additionally, to compensate for limited performance, some approaches rely on training with a large set of hypotheses, requiring a post-selection step during inference to significantly reduce the number of predictions. To tackle these issues, we take inspiration from annealed MCL, a recently introduced technique that improves the convergence properties of MCL methods through an annealed Winner-Takes-All loss (aWTA). In this paper, we demonstrate how the aWTA loss can be integrated with state-of-the-art motion forecasting models to enhance their performance using only a minimal set of hypotheses, eliminating the need for the cumbersome post-selection step. Our approach can be easily incorporated into any trajectory prediction model normally trained using WTA and yields significant improvements. To facilitate the application of our approach to future motion forecasting models, the code will be made publicly available upon acceptance: https://github.com/valeoai/MF_aWTA.
Resilient Multiple Choice Learning: A learned scoring scheme with application to audio scene analysis
Nov 16, 2023We introduce Resilient Multiple Choice Learning (rMCL), an extension of the MCL approach for conditional distribution estimation in regression settings where multiple targets may be sampled for each training input. Multiple Choice Learning is a simple framework to tackle multimodal density estimation, using the Winner-Takes-All (WTA) loss for a set of hypotheses. In regression settings, the existing MCL variants focus on merging the hypotheses, thereby eventually sacrificing the diversity of the predictions. In contrast, our method relies on a novel learned scoring scheme underpinned by a mathematical framework based on Voronoi tessellations of the output space, from which we can derive a probabilistic interpretation. After empirically validating rMCL with experiments on synthetic data, we further assess its merits on the sound source localization problem, demonstrating its practical usefulness and the relevance of its interpretation.
DiffHPE: Robust, Coherent 3D Human Pose Lifting with Diffusion
Sep 04, 2023



We present an innovative approach to 3D Human Pose Estimation (3D-HPE) by integrating cutting-edge diffusion models, which have revolutionized diverse fields, but are relatively unexplored in 3D-HPE. We show that diffusion models enhance the accuracy, robustness, and coherence of human pose estimations. We introduce DiffHPE, a novel strategy for harnessing diffusion models in 3D-HPE, and demonstrate its ability to refine standard supervised 3D-HPE. We also show how diffusion models lead to more robust estimations in the face of occlusions, and improve the time-coherence and the sagittal symmetry of predictions. Using the Human\,3.6M dataset, we illustrate the effectiveness of our approach and its superiority over existing models, even under adverse situations where the occlusion patterns in training do not match those in inference. Our findings indicate that while standalone diffusion models provide commendable performance, their accuracy is even better in combination with supervised models, opening exciting new avenues for 3D-HPE research.
Challenges of Using Real-World Sensory Inputs for Motion Forecasting in Autonomous Driving
Jun 15, 2023Motion forecasting plays a critical role in enabling robots to anticipate future trajectories of surrounding agents and plan accordingly. However, existing forecasting methods often rely on curated datasets that are not faithful to what real-world perception pipelines can provide. In reality, upstream modules that are responsible for detecting and tracking agents, and those that gather road information to build the map, can introduce various errors, including misdetections, tracking errors, and difficulties in being accurate for distant agents and road elements. This paper aims to uncover the challenges of bringing motion forecasting models to this more realistic setting where inputs are provided by perception modules. In particular, we quantify the impacts of the domain gap through extensive evaluation. Furthermore, we design synthetic perturbations to better characterize their consequences, thus providing insights into areas that require improvement in upstream perception modules and guidance toward the development of more robust forecasting methods.
Unifying GANs and Score-Based Diffusion as Generative Particle Models
May 25, 2023Particle-based deep generative models, such as gradient flows and score-based diffusion models, have recently gained traction thanks to their striking performance. Their principle of displacing particle distributions by differential equations is conventionally seen as opposed to the previously widespread generative adversarial networks (GANs), which involve training a pushforward generator network. In this paper, we challenge this interpretation and propose a novel framework that unifies particle and adversarial generative models by framing generator training as a generalization of particle models. This suggests that a generator is an optional addition to any such generative model. Consequently, integrating a generator into a score-based diffusion model and training a GAN without a generator naturally emerge from our framework. We empirically test the viability of these original models as proofs of concepts of potential applications of our framework.
OCTET: Object-aware Counterfactual Explanations
Nov 22, 2022



Nowadays, deep vision models are being widely deployed in safety-critical applications, e.g., autonomous driving, and explainability of such models is becoming a pressing concern. Among explanation methods, counterfactual explanations aim to find minimal and interpretable changes to the input image that would also change the output of the model to be explained. Such explanations point end-users at the main factors that impact the decision of the model. However, previous methods struggle to explain decision models trained on images with many objects, e.g., urban scenes, which are more difficult to work with but also arguably more critical to explain. In this work, we propose to tackle this issue with an object-centric framework for counterfactual explanation generation. Our method, inspired by recent generative modeling works, encodes the query image into a latent space that is structured in a way to ease object-level manipulations. Doing so, it provides the end-user with control over which search directions (e.g., spatial displacement of objects, style modification, etc.) are to be explored during the counterfactual generation. We conduct a set of experiments on counterfactual explanation benchmarks for driving scenes, and we show that our method can be adapted beyond classification, e.g., to explain semantic segmentation models. To complete our analysis, we design and run a user study that measures the usefulness of counterfactual explanations in understanding a decision model. Code is available at https://github.com/valeoai/OCTET.
STEEX: Steering Counterfactual Explanations with Semantics
Nov 26, 2021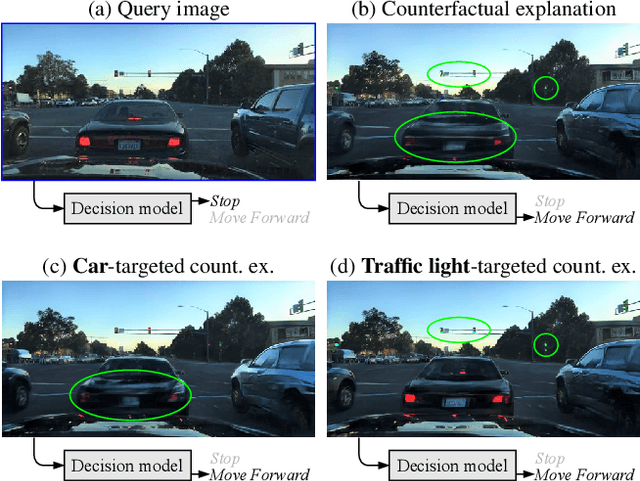
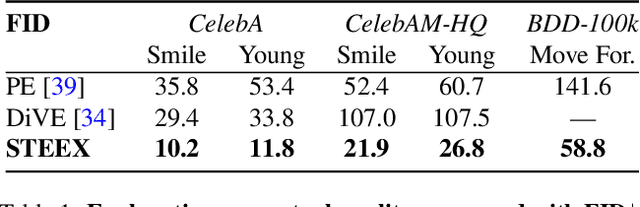
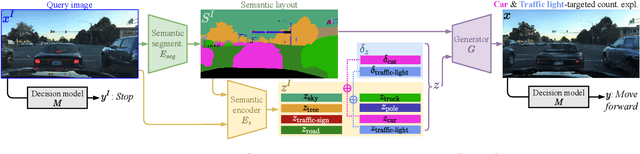
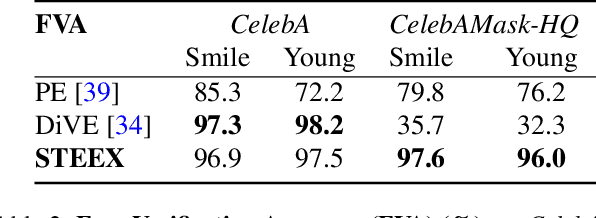
As deep learning models are increasingly used in safety-critical applications, explainability and trustworthiness become major concerns. For simple images, such as low-resolution face portraits, synthesizing visual counterfactual explanations has recently been proposed as a way to uncover the decision mechanisms of a trained classification model. In this work, we address the problem of producing counterfactual explanations for high-quality images and complex scenes. Leveraging recent semantic-to-image models, we propose a new generative counterfactual explanation framework that produces plausible and sparse modifications which preserve the overall scene structure. Furthermore, we introduce the concept of "region-targeted counterfactual explanations", and a corresponding framework, where users can guide the generation of counterfactuals by specifying a set of semantic regions of the query image the explanation must be about. Extensive experiments are conducted on challenging datasets including high-quality portraits (CelebAMask-HQ) and driving scenes (BDD100k).
Raising context awareness in motion forecasting
Sep 16, 2021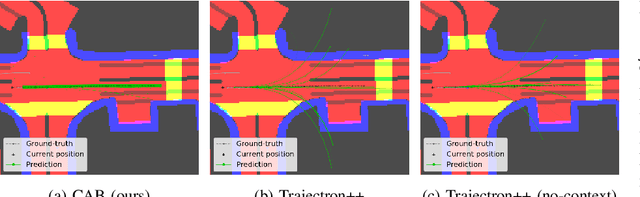
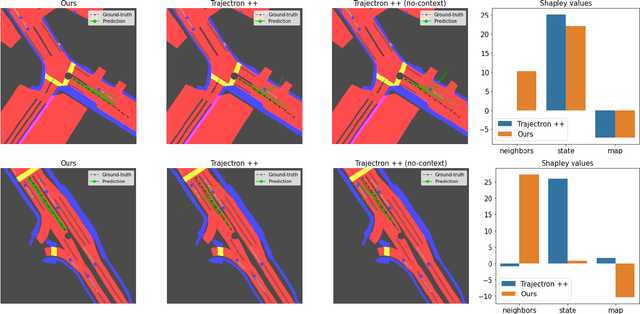
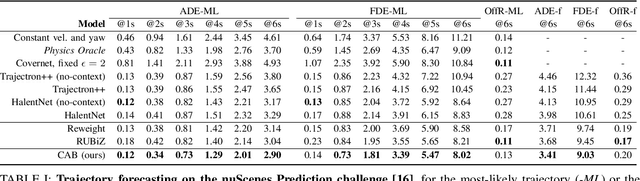
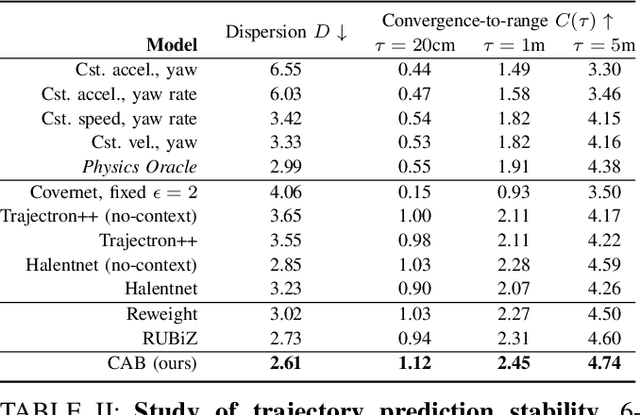
Learning-based trajectory prediction models have encountered great success, with the promise of leveraging contextual information in addition to motion history. Yet, we find that state-of-the-art forecasting methods tend to overly rely on the agent's dynamics, failing to exploit the semantic cues provided at its input. To alleviate this issue, we introduce CAB, a motion forecasting model equipped with a training procedure designed to promote the use of semantic contextual information. We also introduce two novel metrics -- dispersion and convergence-to-range -- to measure the temporal consistency of successive forecasts, which we found missing in standard metrics. Our method is evaluated on the widely adopted nuScenes Prediction benchmark.
A Neural Tangent Kernel Perspective of GANs
Jun 10, 2021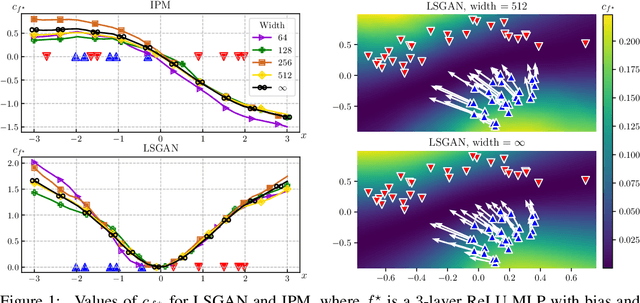

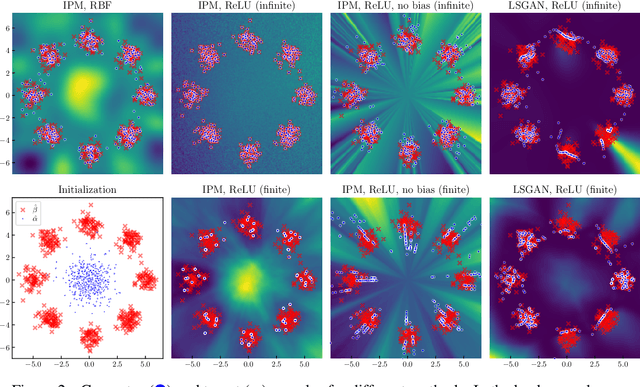

Theoretical analyses for Generative Adversarial Networks (GANs) generally assume an arbitrarily large family of discriminators and do not consider the characteristics of the architectures used in practice. We show that this framework of analysis is too simplistic to properly analyze GAN training. To tackle this issue, we leverage the theory of infinite-width neural networks to model neural discriminator training for a wide range of adversarial losses via its Neural Tangent Kernel (NTK). Our analytical results show that GAN trainability primarily depends on the discriminator's architecture. We further study the discriminator for specific architectures and losses, and highlight properties providing a new understanding of GAN training. For example, we find that GANs trained with the integral probability metric loss minimize the maximum mean discrepancy with the NTK as kernel. Our conclusions demonstrate the analysis opportunities provided by the proposed framework, which paves the way for better and more principled GAN models. We release a generic GAN analysis toolkit based on our framework that supports the empirical part of our study.
Stochastic Latent Residual Video Prediction
Feb 21, 2020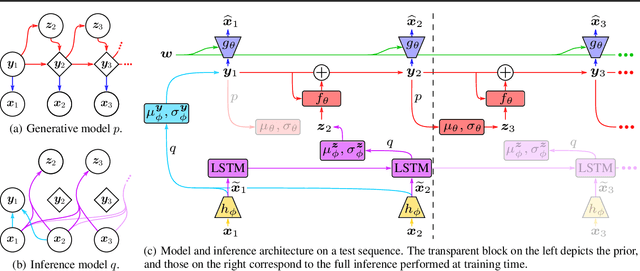

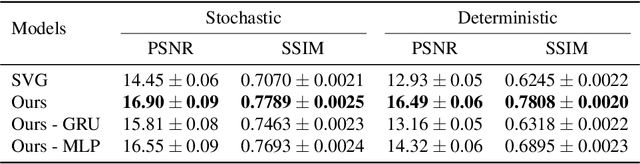
Designing video prediction models that account for the inherent uncertainty of the future is challenging. Most works in the literature are based on stochastic image-autoregressive recurrent networks, which raises several performance and applicability issues. An alternative is to use fully latent temporal models which untie frame synthesis and temporal dynamics. However, no such model for stochastic video prediction has been proposed in the literature yet, due to design and training difficulties. In this paper, we overcome these difficulties by introducing a novel stochastic temporal model whose dynamics are governed in a latent space by a residual update rule. This first-order scheme is motivated by discretization schemes of differential equations. It naturally models video dynamics as it allows our simpler, more interpretable, latent model to outperform prior state-of-the-art methods on challenging datasets.