 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Latent Residual Video Prediction
Feb 21, 2020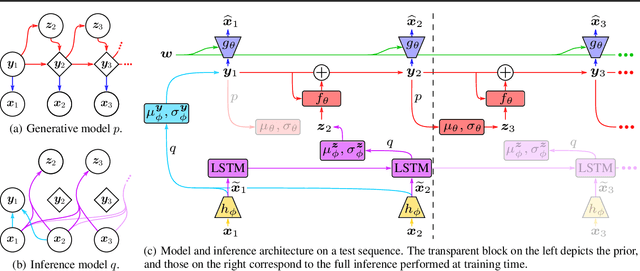

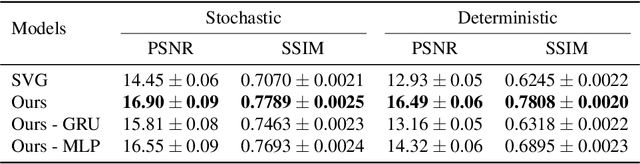
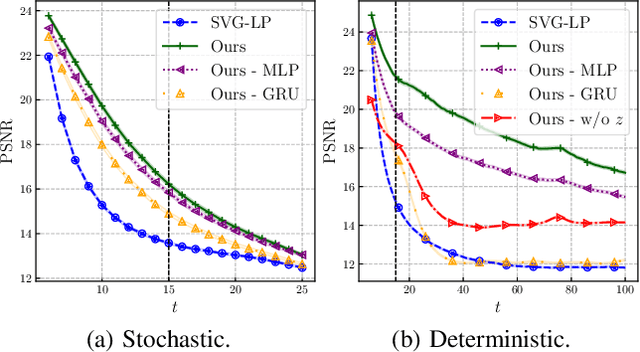
Designing video prediction models that account for the inherent uncertainty of the future is challenging. Most works in the literature are based on stochastic image-autoregressive recurrent networks, which raises several performance and applicability issues. An alternative is to use fully latent temporal models which untie frame synthesis and temporal dynamics. However, no such model for stochastic video prediction has been proposed in the literature yet, due to design and training difficulties. In this paper, we overcome these difficulties by introducing a novel stochastic temporal model whose dynamics are governed in a latent space by a residual update rule. This first-order scheme is motivated by discretization schemes of differential equations. It naturally models video dynamics as it allows our simpler, more interpretable, latent model to outperform prior state-of-the-art methods on challenging datasets.
Learning Dynamic Author Representations with Temporal Language Models
Sep 11, 2019
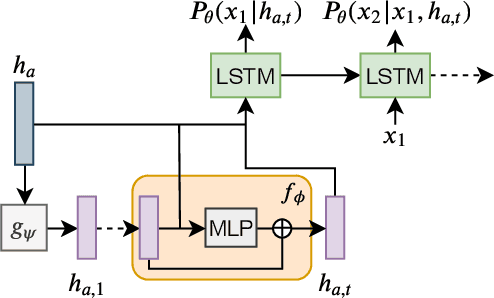

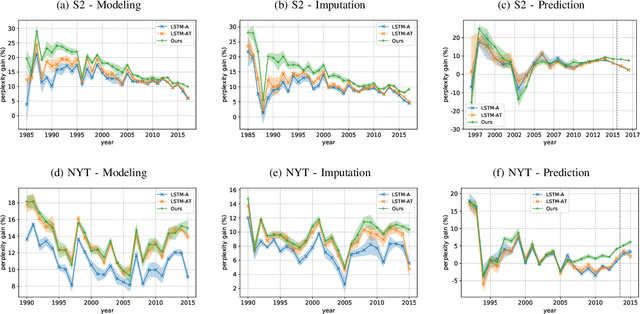
Language models are at the heart of numerous works, notably in the text mining and information retrieval communities. These statistical models aim at extracting word distributions, from simple unigram models to recurrent approaches with latent variables that capture subtle dependencies in texts. However, those models are learned from word sequences only, and authors' identities, as well as publication dates, are seldom considered. We propose a neural model, based on recurrent language modeling, which aims at capturing language diffusion tendencies in author communities through time. By conditioning language models with author and temporal vector states, we are able to leverage the latent dependencies between the text contexts. This allows us to beat several temporal and non-temporal language baselines on two real-world corpora, and to learn meaningful author representations that vary through time.
Spatio-Temporal Neural Networks for Space-Time Series Forecasting and Relations Discovery
Apr 23, 2018

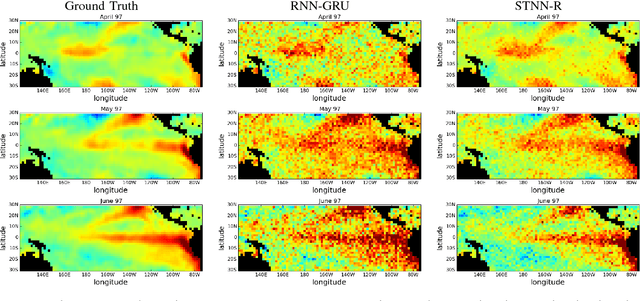
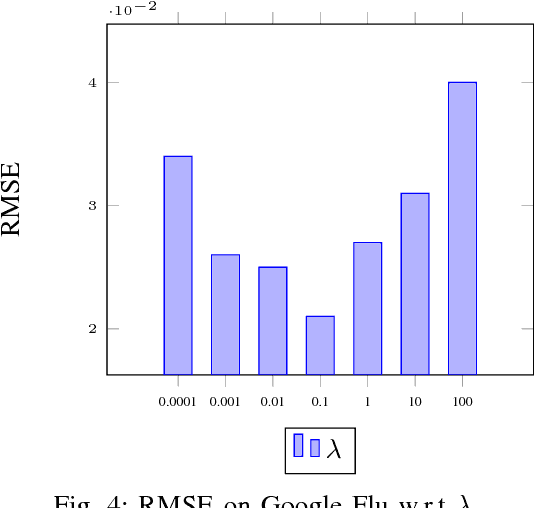
We introduce a dynamical spatio-temporal model formalized as a recurrent neural network for forecasting time series of spatial processes, i.e. series of observations sharing temporal and spatial dependencies. The model learns these dependencies through a structured latent dynamical component, while a decoder predicts the observations from the latent representations. We consider several variants of this model, corresponding to different prior hypothesis about the spatial relations between the series. The model is evaluated and compared to state-of-the-art baselines, on a variety of forecasting problems representative of different application areas: epidemiology, geo-spatial statistics and car-traffic prediction. Besides these evaluations, we also describe experiments showing the ability of this approach to extract relevant spatial relations.
* accepted by: ICDM 2018 - IEEE International Conference on Data Mining series (ICDM)