 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOCTET: Object-aware Counterfactual Explanations
Nov 22, 2022



Nowadays, deep vision models are being widely deployed in safety-critical applications, e.g., autonomous driving, and explainability of such models is becoming a pressing concern. Among explanation methods, counterfactual explanations aim to find minimal and interpretable changes to the input image that would also change the output of the model to be explained. Such explanations point end-users at the main factors that impact the decision of the model. However, previous methods struggle to explain decision models trained on images with many objects, e.g., urban scenes, which are more difficult to work with but also arguably more critical to explain. In this work, we propose to tackle this issue with an object-centric framework for counterfactual explanation generation. Our method, inspired by recent generative modeling works, encodes the query image into a latent space that is structured in a way to ease object-level manipulations. Doing so, it provides the end-user with control over which search directions (e.g., spatial displacement of objects, style modification, etc.) are to be explored during the counterfactual generation. We conduct a set of experiments on counterfactual explanation benchmarks for driving scenes, and we show that our method can be adapted beyond classification, e.g., to explain semantic segmentation models. To complete our analysis, we design and run a user study that measures the usefulness of counterfactual explanations in understanding a decision model. Code is available at https://github.com/valeoai/OCTET.
STEEX: Steering Counterfactual Explanations with Semantics
Nov 26, 2021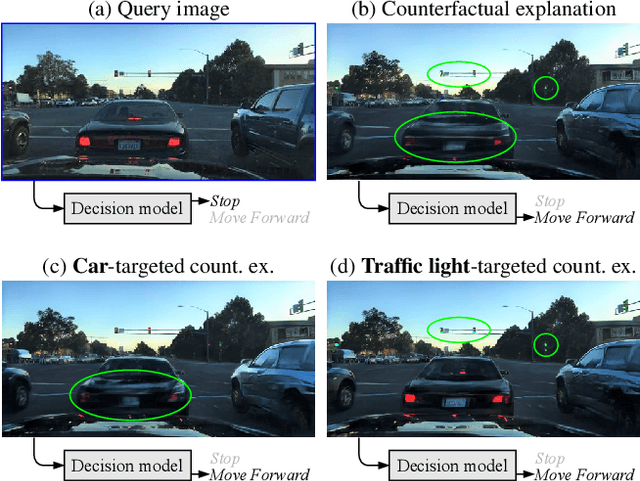
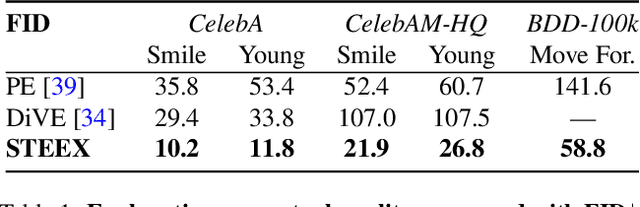
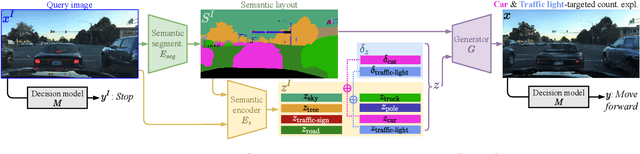
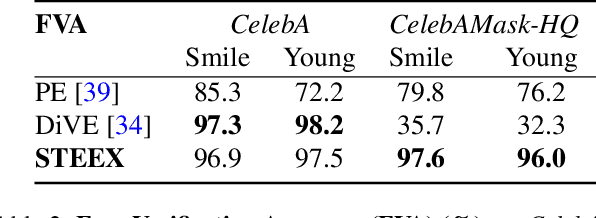
As deep learning models are increasingly used in safety-critical applications, explainability and trustworthiness become major concerns. For simple images, such as low-resolution face portraits, synthesizing visual counterfactual explanations has recently been proposed as a way to uncover the decision mechanisms of a trained classification model. In this work, we address the problem of producing counterfactual explanations for high-quality images and complex scenes. Leveraging recent semantic-to-image models, we propose a new generative counterfactual explanation framework that produces plausible and sparse modifications which preserve the overall scene structure. Furthermore, we introduce the concept of "region-targeted counterfactual explanations", and a corresponding framework, where users can guide the generation of counterfactuals by specifying a set of semantic regions of the query image the explanation must be about. Extensive experiments are conducted on challenging datasets including high-quality portraits (CelebAMask-HQ) and driving scenes (BDD100k).
Raising context awareness in motion forecasting
Sep 16, 2021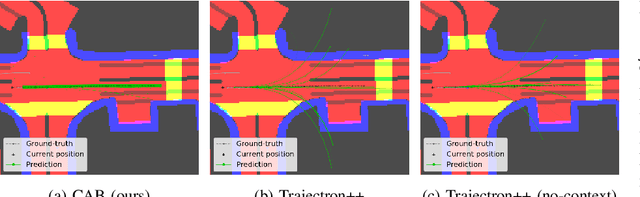
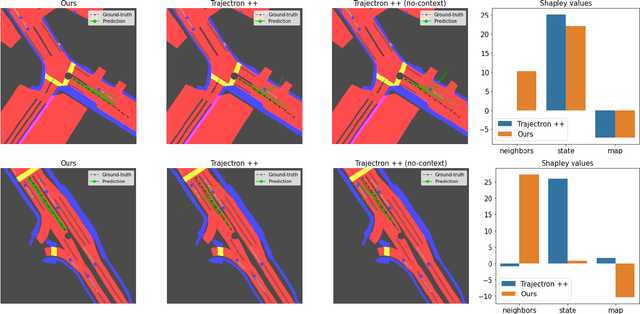
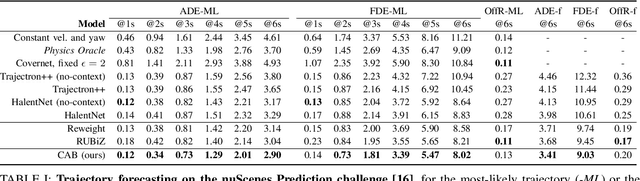
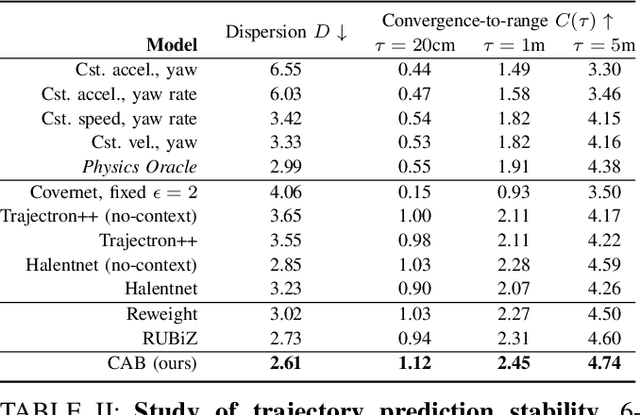
Learning-based trajectory prediction models have encountered great success, with the promise of leveraging contextual information in addition to motion history. Yet, we find that state-of-the-art forecasting methods tend to overly rely on the agent's dynamics, failing to exploit the semantic cues provided at its input. To alleviate this issue, we introduce CAB, a motion forecasting model equipped with a training procedure designed to promote the use of semantic contextual information. We also introduce two novel metrics -- dispersion and convergence-to-range -- to measure the temporal consistency of successive forecasts, which we found missing in standard metrics. Our method is evaluated on the widely adopted nuScenes Prediction benchmark.
Explainability of vision-based autonomous driving systems: Review and challenges
Jan 13, 2021

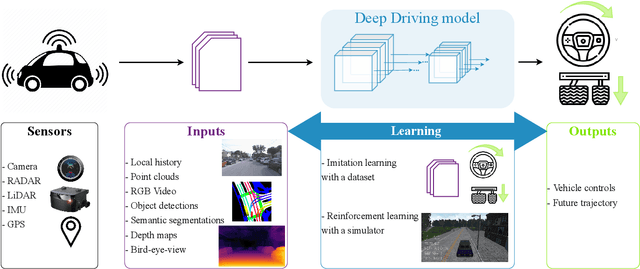
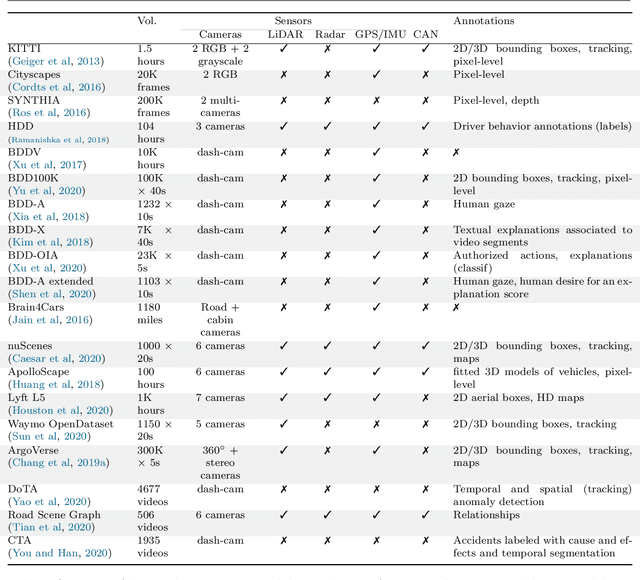
This survey reviews explainability methods for vision-based self-driving systems. The concept of explainability has several facets and the need for explainability is strong in driving, a safety-critical application. Gathering contributions from several research fields, namely computer vision, deep learning, autonomous driving, explainable AI (X-AI), this survey tackles several points. First, it discusses definitions, context, and motivation for gaining more interpretability and explainability from self-driving systems. Second, major recent state-of-the-art approaches to develop self-driving systems are quickly presented. Third, methods providing explanations to a black-box self-driving system in a post-hoc fashion are comprehensively organized and detailed. Fourth, approaches from the literature that aim at building more interpretable self-driving systems by design are presented and discussed in detail. Finally, remaining open-challenges and potential future research directions are identified and examined.
Driving Behavior Explanation with Multi-level Fusion
Dec 09, 2020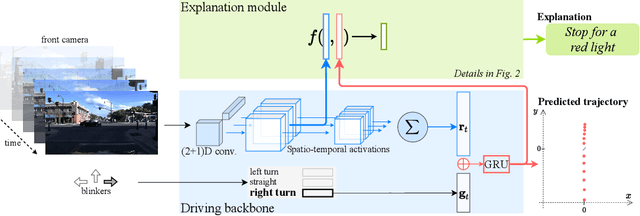
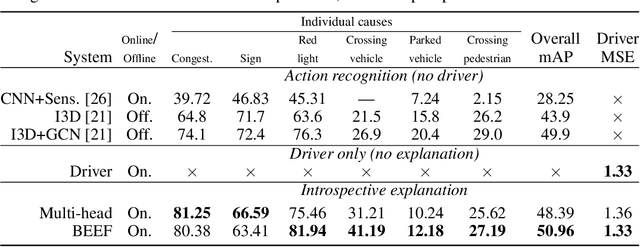
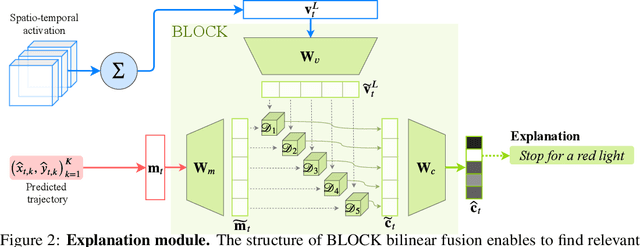
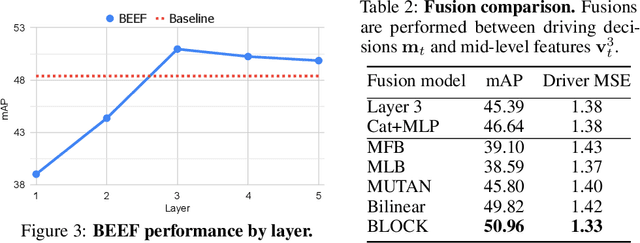
In this era of active development of autonomous vehicles, it becomes crucial to provide driving systems with the capacity to explain their decisions. In this work, we focus on generating high-level driving explanations as the vehicle drives. We present BEEF, for BEhavior Explanation with Fusion, a deep architecture which explains the behavior of a trajectory prediction model. Supervised by annotations of human driving decisions justifications, BEEF learns to fuse features from multiple levels. Leveraging recent advances in the multi-modal fusion literature, BEEF is carefully designed to model the correlations between high-level decisions features and mid-level perceptual features. The flexibility and efficiency of our approach are validated with extensive experiments on the HDD and BDD-X datasets.