 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriving on Registers
Jan 08, 2026We present DrivoR, a simple and efficient transformer-based architecture for end-to-end autonomous driving. Our approach builds on pretrained Vision Transformers (ViTs) and introduces camera-aware register tokens that compress multi-camera features into a compact scene representation, significantly reducing downstream computation without sacrificing accuracy. These tokens drive two lightweight transformer decoders that generate and then score candidate trajectories. The scoring decoder learns to mimic an oracle and predicts interpretable sub-scores representing aspects such as safety, comfort, and efficiency, enabling behavior-conditioned driving at inference. Despite its minimal design, DrivoR outperforms or matches strong contemporary baselines across NAVSIM-v1, NAVSIM-v2, and the photorealistic closed-loop HUGSIM benchmark. Our results show that a pure-transformer architecture, combined with targeted token compression, is sufficient for accurate, efficient, and adaptive end-to-end driving. Code and checkpoints will be made available via the project page.
VaViM and VaVAM: Autonomous Driving through Video Generative Modeling
Feb 21, 2025We explore the potential of large-scale generative video models for autonomous driving, introducing an open-source auto-regressive video model (VaViM) and its companion video-action model (VaVAM) to investigate how video pre-training transfers to real-world driving. VaViM is a simple auto-regressive video model that predicts frames using spatio-temporal token sequences. We show that it captures the semantics and dynamics of driving scenes. VaVAM, the video-action model, leverages the learned representations of VaViM to generate driving trajectories through imitation learning. Together, the models form a complete perception-to-action pipeline. We evaluate our models in open- and closed-loop driving scenarios, revealing that video-based pre-training holds promise for autonomous driving. Key insights include the semantic richness of the learned representations, the benefits of scaling for video synthesis, and the complex relationship between model size, data, and safety metrics in closed-loop evaluations. We release code and model weights at https://github.com/valeoai/VideoActionModel
PPT: Pre-Training with Pseudo-Labeled Trajectories for Motion Forecasting
Dec 09, 2024Motion forecasting (MF) for autonomous driving aims at anticipating trajectories of surrounding agents in complex urban scenarios. In this work, we investigate a mixed strategy in MF training that first pre-train motion forecasters on pseudo-labeled data, then fine-tune them on annotated data. To obtain pseudo-labeled trajectories, we propose a simple pipeline that leverages off-the-shelf single-frame 3D object detectors and non-learning trackers. The whole pre-training strategy including pseudo-labeling is coined as PPT. Our extensive experiments demonstrate that: (1) combining PPT with supervised fine-tuning on annotated data achieves superior performance on diverse testbeds, especially under annotation-efficient regimes, (2) scaling up to multiple datasets improves the previous state-of-the-art and (3) PPT helps enhance cross-dataset generalization. Our findings showcase PPT as a promising pre-training solution for robust motion forecasting in diverse autonomous driving contexts.
GIFT: A Framework for Global Interpretable Faithful Textual Explanations of Vision Classifiers
Nov 23, 2024



Understanding deep models is crucial for deploying them in safety-critical applications. We introduce GIFT, a framework for deriving post-hoc, global, interpretable, and faithful textual explanations for vision classifiers. GIFT starts from local faithful visual counterfactual explanations and employs (vision) language models to translate those into global textual explanations. Crucially, GIFT provides a verification stage measuring the causal effect of the proposed explanations on the classifier decision. Through experiments across diverse datasets, including CLEVR, CelebA, and BDD, we demonstrate that GIFT effectively reveals meaningful insights, uncovering tasks, concepts, and biases used by deep vision classifiers. Our code, data, and models are released at https://github.com/valeoai/GIFT.
Annealed Winner-Takes-All for Motion Forecasting
Sep 18, 2024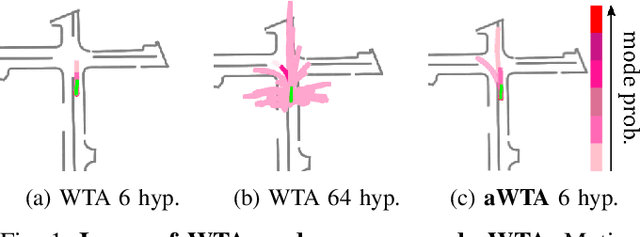
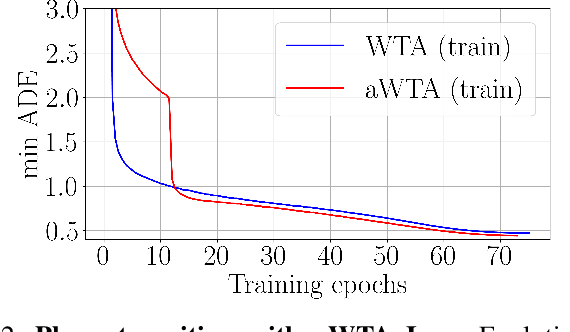
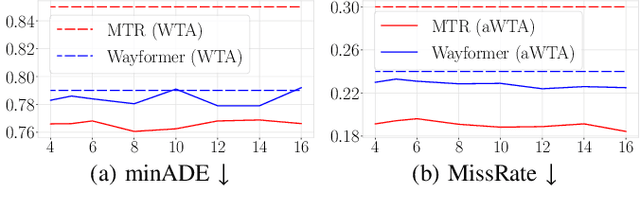
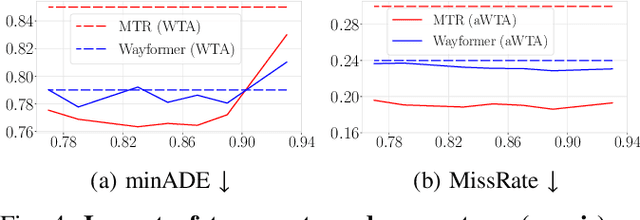
In autonomous driving, motion prediction aims at forecasting the future trajectories of nearby agents, helping the ego vehicle to anticipate behaviors and drive safely. A key challenge is generating a diverse set of future predictions, commonly addressed using data-driven models with Multiple Choice Learning (MCL) architectures and Winner-Takes-All (WTA) training objectives. However, these methods face initialization sensitivity and training instabilities. Additionally, to compensate for limited performance, some approaches rely on training with a large set of hypotheses, requiring a post-selection step during inference to significantly reduce the number of predictions. To tackle these issues, we take inspiration from annealed MCL, a recently introduced technique that improves the convergence properties of MCL methods through an annealed Winner-Takes-All loss (aWTA). In this paper, we demonstrate how the aWTA loss can be integrated with state-of-the-art motion forecasting models to enhance their performance using only a minimal set of hypotheses, eliminating the need for the cumbersome post-selection step. Our approach can be easily incorporated into any trajectory prediction model normally trained using WTA and yields significant improvements. To facilitate the application of our approach to future motion forecasting models, the code will be made publicly available upon acceptance: https://github.com/valeoai/MF_aWTA.
ReGentS: Real-World Safety-Critical Driving Scenario Generation Made Stable
Sep 12, 2024Machine learning based autonomous driving systems often face challenges with safety-critical scenarios that are rare in real-world data, hindering their large-scale deployment. While increasing real-world training data coverage could address this issue, it is costly and dangerous. This work explores generating safety-critical driving scenarios by modifying complex real-world regular scenarios through trajectory optimization. We propose ReGentS, which stabilizes generated trajectories and introduces heuristics to avoid obvious collisions and optimization problems. Our approach addresses unrealistic diverging trajectories and unavoidable collision scenarios that are not useful for training robust planner. We also extend the scenario generation framework to handle real-world data with up to 32 agents. Additionally, by using a differentiable simulator, our approach simplifies gradient descent-based optimization involving a simulator, paving the way for future advancements. The code is available at https://github.com/valeoai/ReGentS.
Valeo4Cast: A Modular Approach to End-to-End Forecasting
Jun 12, 2024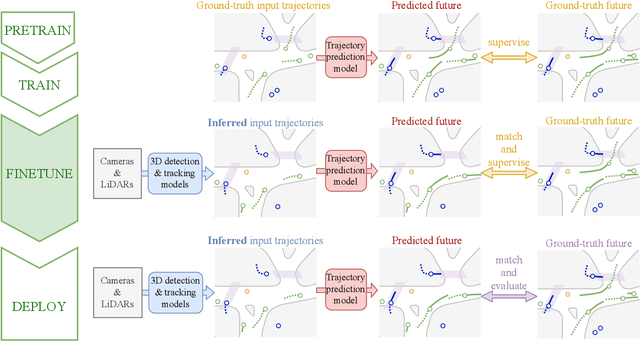
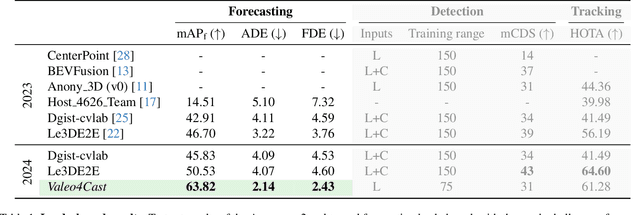
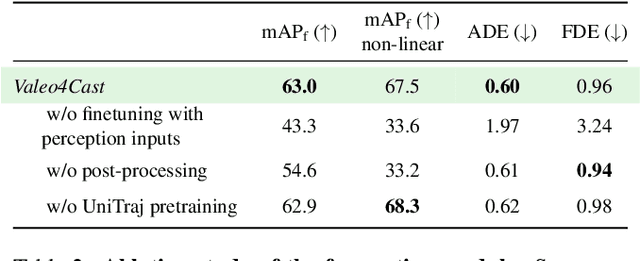
Motion forecasting is crucial in autonomous driving systems to anticipate the future trajectories of surrounding agents such as pedestrians, vehicles, and traffic signals. In end-to-end forecasting, the model must jointly detect from sensor data (cameras or LiDARs) the position and past trajectories of the different elements of the scene and predict their future location. We depart from the current trend of tackling this task via end-to-end training from perception to forecasting and we use a modular approach instead. Following a recent study, we individually build and train detection, tracking, and forecasting modules. We then only use consecutive finetuning steps to integrate the modules better and alleviate compounding errors. Our study reveals that this simple yet effective approach significantly improves performance on the end-to-end forecasting benchmark. Consequently, our solution ranks first in the Argoverse 2 end-to-end Forecasting Challenge held at CVPR 2024 Workshop on Autonomous Driving (WAD), with 63.82 mAPf. We surpass forecasting results by +17.1 points over last year's winner and by +13.3 points over this year's runner-up. This remarkable performance in forecasting can be explained by our modular paradigm, which integrates finetuning strategies and significantly outperforms the end-to-end-trained counterparts.
UniTraj: A Unified Framework for Scalable Vehicle Trajectory Prediction
Mar 27, 2024Vehicle trajectory prediction has increasingly relied on data-driven solutions, but their ability to scale to different data domains and the impact of larger dataset sizes on their generalization remain under-explored. While these questions can be studied by employing multiple datasets, it is challenging due to several discrepancies, e.g., in data formats, map resolution, and semantic annotation types. To address these challenges, we introduce UniTraj, a comprehensive framework that unifies various datasets, models, and evaluation criteria, presenting new opportunities for the vehicle trajectory prediction field. In particular, using UniTraj, we conduct extensive experiments and find that model performance significantly drops when transferred to other datasets. However, enlarging data size and diversity can substantially improve performance, leading to a new state-of-the-art result for the nuScenes dataset. We provide insights into dataset characteristics to explain these findings. The code can be found here: https://github.com/vita-epfl/UniTraj
Unsupervised Object Localization in the Era of Self-Supervised ViTs: A Survey
Oct 19, 2023The recent enthusiasm for open-world vision systems show the high interest of the community to perform perception tasks outside of the closed-vocabulary benchmark setups which have been so popular until now. Being able to discover objects in images/videos without knowing in advance what objects populate the dataset is an exciting prospect. But how to find objects without knowing anything about them? Recent works show that it is possible to perform class-agnostic unsupervised object localization by exploiting self-supervised pre-trained features. We propose here a survey of unsupervised object localization methods that discover objects in images without requiring any manual annotation in the era of self-supervised ViTs. We gather links of discussed methods in the repository https://github.com/valeoai/Awesome-Unsupervised-Object-Localization.
Challenges of Using Real-World Sensory Inputs for Motion Forecasting in Autonomous Driving
Jun 15, 2023Motion forecasting plays a critical role in enabling robots to anticipate future trajectories of surrounding agents and plan accordingly. However, existing forecasting methods often rely on curated datasets that are not faithful to what real-world perception pipelines can provide. In reality, upstream modules that are responsible for detecting and tracking agents, and those that gather road information to build the map, can introduce various errors, including misdetections, tracking errors, and difficulties in being accurate for distant agents and road elements. This paper aims to uncover the challenges of bringing motion forecasting models to this more realistic setting where inputs are provided by perception modules. In particular, we quantify the impacts of the domain gap through extensive evaluation. Furthermore, we design synthetic perturbations to better characterize their consequences, thus providing insights into areas that require improvement in upstream perception modules and guidance toward the development of more robust forecasting methods.