 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdiBERT, a generative model for image editing
Paper and Code

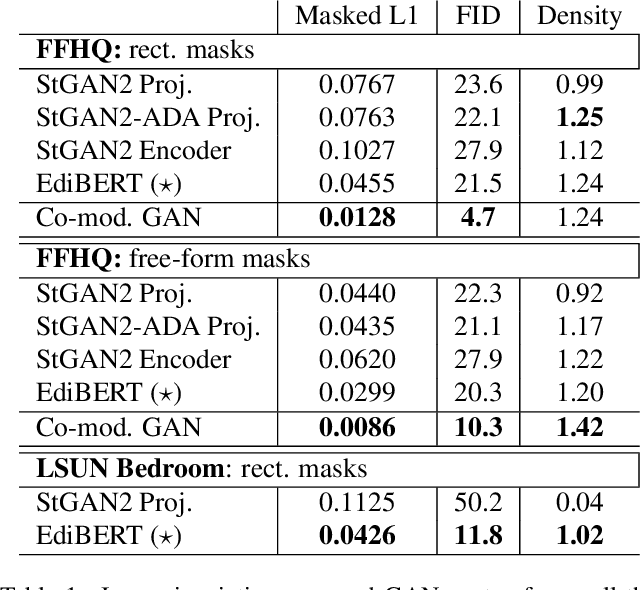

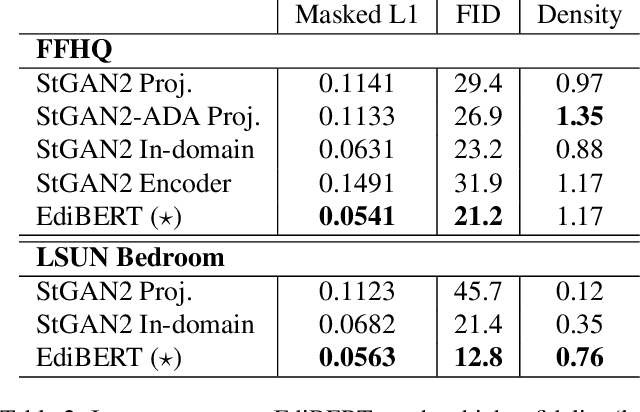
Advances in computer vision are pushing the limits of im-age manipulation, with generative models sampling detailed images on various tasks. However, a specialized model is often developed and trained for each specific task, even though many image edition tasks share similarities. In denoising, inpainting, or image compositing, one always aims at generating a realistic image from a low-quality one. In this paper, we aim at making a step towards a unified approach for image editing. To do so, we propose EdiBERT, a bi-directional transformer trained in the discrete latent space built by a vector-quantized auto-encoder. We argue that such a bidirectional model is suited for image manipulation since any patch can be re-sampled conditionally to the whole image. Using this unique and straightforward training objective, we show that the resulting model matches state-of-the-art performances on a wide variety of tasks: image denoising, image completion, and image composition.