 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly-Supervised Conditional Embedding for Referred Visual Search
Jun 05, 2023This paper presents a new approach to image similarity search in the context of fashion, a domain with inherent ambiguity due to the multiple ways in which images can be considered similar. We introduce the concept of Referred Visual Search (RVS), where users provide additional information to define the desired similarity. We present a new dataset, LAION-RVS-Fashion, consisting of 272K fashion products with 842K images extracted from LAION, designed explicitly for this task. We then propose an innovative method for learning conditional embeddings using weakly-supervised training, achieving a 6% increase in Recall at one (R@1) against a gallery with 2M distractors, compared to classical approaches based on explicit attention and filtering. The proposed method demonstrates robustness, maintaining similar R@1 when dealing with 2.5 times as many distractors as the baseline methods. We believe this is a step forward in the emerging field of Referred Visual Search both in terms of accessible data and approach. Code, data and models are available at https://www.github.com/Simon-Lepage/CondViT-LRVSF .
Optimal precision for GANs
Jul 21, 2022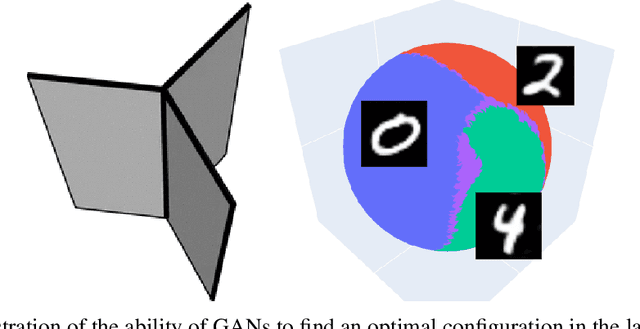


When learning disconnected distributions, Generative adversarial networks (GANs) are known to face model misspecification. Indeed, a continuous mapping from a unimodal latent distribution to a disconnected one is impossible, so GANs necessarily generate samples outside of the support of the target distribution. This raises a fundamental question: what is the latent space partition that minimizes the measure of these areas? Building on a recent result of geometric measure theory, we prove that an optimal GANs must structure its latent space as a 'simplicial cluster' - a Voronoi partition where cells are convex cones - when the dimension of the latent space is larger than the number of modes. In this configuration, each Voronoi cell maps to a distinct mode of the data. We derive both an upper and a lower bound on the optimal precision of GANs learning disconnected manifolds. Interestingly, these two bounds have the same order of decrease: $\sqrt{\log m}$, $m$ being the number of modes. Finally, we perform several experiments to exhibit the geometry of the latent space and experimentally show that GANs have a geometry with similar properties to the theoretical one.
Lessons from the AdKDD'21 Privacy-Preserving ML Challenge
Jan 31, 2022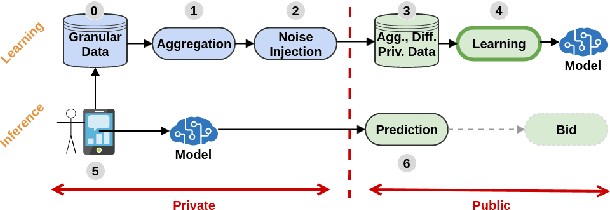
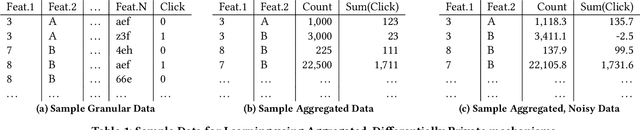
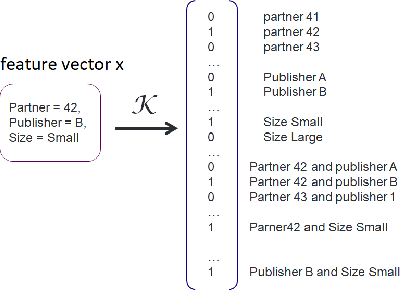
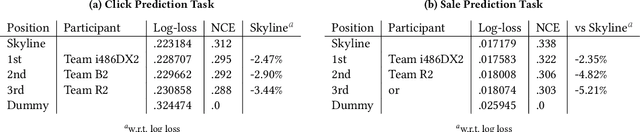
Designing data sharing mechanisms providing performance and strong privacy guarantees is a hot topic for the Online Advertising industry. Namely, a prominent proposal discussed under the Improving Web Advertising Business Group at W3C only allows sharing advertising signals through aggregated, differentially private reports of past displays. To study this proposal extensively, an open Privacy-Preserving Machine Learning Challenge took place at AdKDD'21, a premier workshop on Advertising Science with data provided by advertising company Criteo. In this paper, we describe the challenge tasks, the structure of the available datasets, report the challenge results, and enable its full reproducibility. A key finding is that learning models on large, aggregated data in the presence of a small set of unaggregated data points can be surprisingly efficient and cheap. We also run additional experiments to observe the sensitivity of winning methods to different parameters such as privacy budget or quantity of available privileged side information. We conclude that the industry needs either alternate designs for private data sharing or a breakthrough in learning with aggregated data only to keep ad relevance at a reasonable level.
EdiBERT, a generative model for image editing
Nov 30, 2021
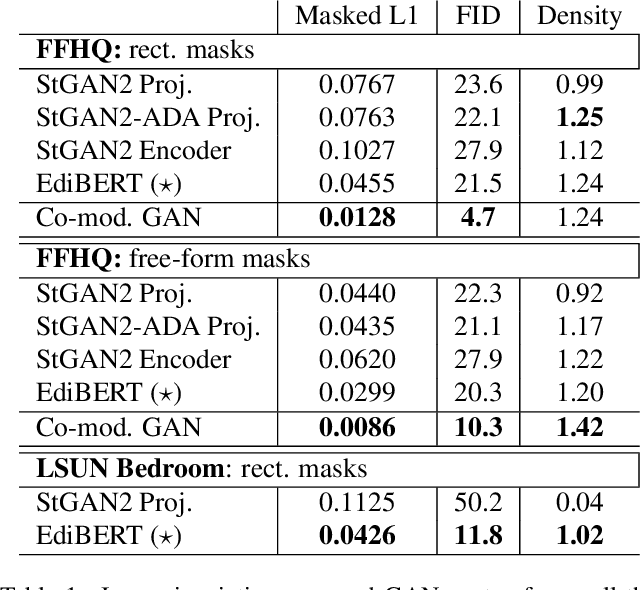

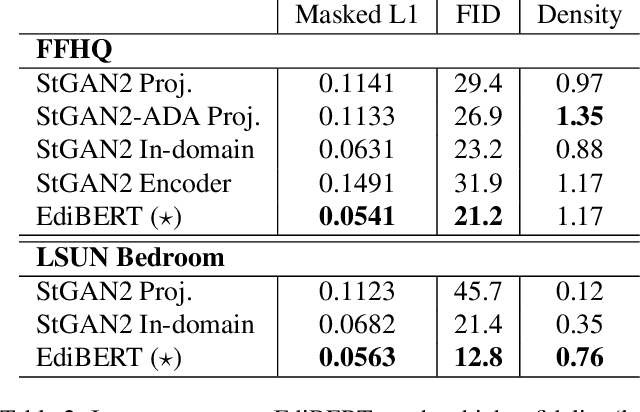
Advances in computer vision are pushing the limits of im-age manipulation, with generative models sampling detailed images on various tasks. However, a specialized model is often developed and trained for each specific task, even though many image edition tasks share similarities. In denoising, inpainting, or image compositing, one always aims at generating a realistic image from a low-quality one. In this paper, we aim at making a step towards a unified approach for image editing. To do so, we propose EdiBERT, a bi-directional transformer trained in the discrete latent space built by a vector-quantized auto-encoder. We argue that such a bidirectional model is suited for image manipulation since any patch can be re-sampled conditionally to the whole image. Using this unique and straightforward training objective, we show that the resulting model matches state-of-the-art performances on a wide variety of tasks: image denoising, image completion, and image composition.
Do Not Mask What You Do Not Need to Mask: a Parser-Free Virtual Try-On
Jul 03, 2020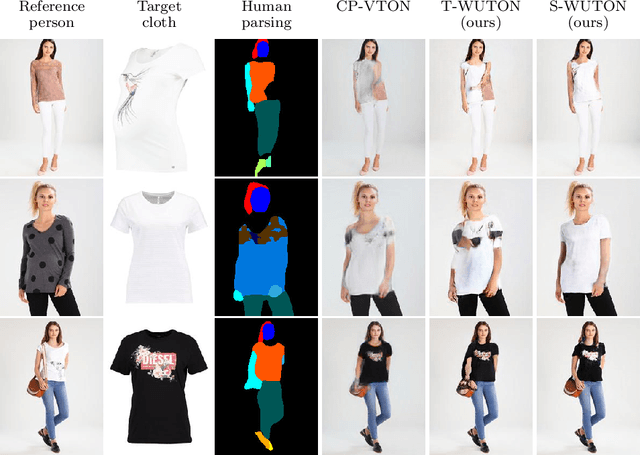
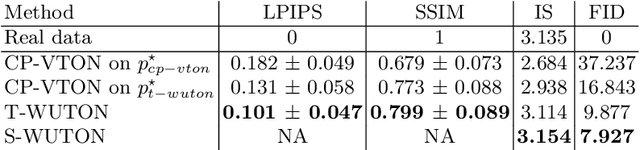

The 2D virtual try-on task has recently attracted a great interest from the research community, for its direct potential applications in online shopping as well as for its inherent and non-addressed scientific challenges. This task requires fitting an in-shop cloth image on the image of a person, which is highly challenging because it involves cloth warping, image compositing, and synthesizing. Casting virtual try-on into a supervised task faces a difficulty: available datasets are composed of pairs of pictures (cloth, person wearing the cloth). Thus, we have no access to ground-truth when the cloth on the person changes. State-of-the-art models solve this by masking the cloth information on the person with both a human parser and a pose estimator. Then, image synthesis modules are trained to reconstruct the person image from the masked person image and the cloth image. This procedure has several caveats: firstly, human parsers are prone to errors; secondly, it is a costly pre-processing step, which also has to be applied at inference time; finally, it makes the task harder than it is since the mask covers information that should be kept such as hands or accessories. In this paper, we propose a novel student-teacher paradigm where the teacher is trained in the standard way (reconstruction) before guiding the student to focus on the initial task (changing the cloth). The student additionally learns from an adversarial loss, which pushes it to follow the distribution of the real images. Consequently, the student exploits information that is masked to the teacher. A student trained without the adversarial loss would not use this information. Also, getting rid of both human parser and pose estimator at inference time allows obtaining a real-time virtual try-on.
End-to-End Learning of Geometric Deformations of Feature Maps for Virtual Try-On
Jun 10, 2019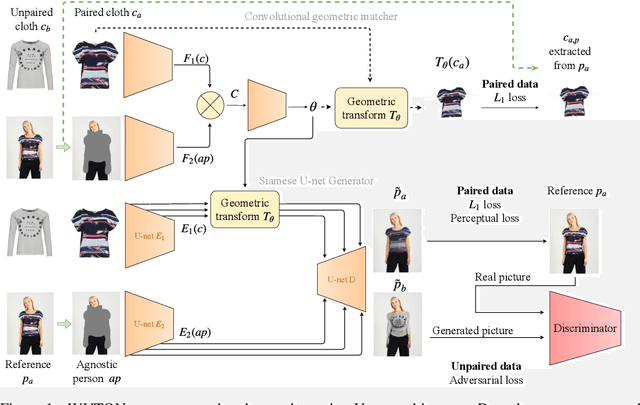



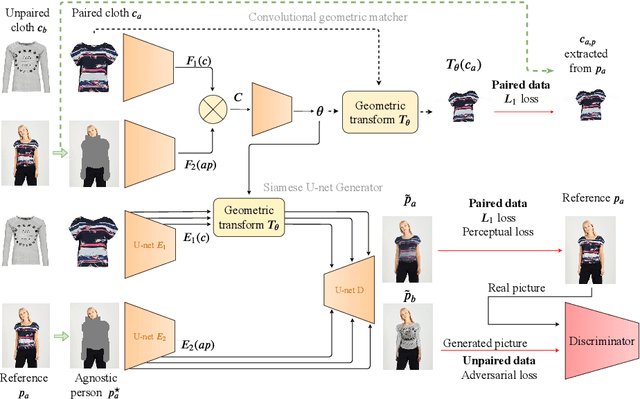
The 2D virtual try-on task has recently attracted a lot of interest from the research community, for its direct potential applications in online shopping as well as for its inherent and non-addressed scientific challenges. This task requires to fit an in-shop cloth image on the image of a person. It is highly challenging because it requires to warp the cloth on the target person while preserving its patterns and characteristics, and to compose the item with the person in a realistic manner. Current state-of-the-art models generate images with visible artifacts, due either to a pixel-level composition step or to the geometric transformation. In this paper, we propose WUTON: a Warping U-net for a Virtual Try-On system. It is a siamese U-net generator whose skip connections are geometrically transformed by a convolutional geometric matcher. The whole architecture is trained end-to-end with a multi-task loss including an adversarial one. This enables our network to generate and use realistic spatial transformations of the cloth to synthesize images of high visual quality. The proposed architecture can be trained end-to-end and allows us to advance towards a detail-preserving and photo-realistic 2D virtual try-on system. Our method outperforms the current state-of-the-art with visual results as well as with the Learned Perceptual Image Similarity (LPIPS) metric.
Distributionally Robust Reinforcement Learning
Feb 23, 2019
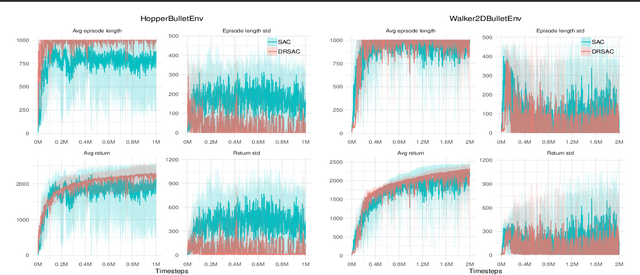
Generalization to unknown/uncertain environments of reinforcement learning algorithms is crucial for real-world applications. In this work, we explicitly consider uncertainty associated with the test environment through an uncertainty set. We formulate the Distributionally Robust Reinforcement Learning (DR-RL) objective that consists in maximizing performance against a worst-case policy in uncertainty set centered at the reference policy. Based on this objective, we derive computationally efficient policy improvement algorithm that benefits from Distributionally Robust Optimization (DRO) guarantees. Further, we propose an iterative procedure that increases stability of learning, called Distributionally Robust Policy Iteration. Combined with maximum entropy framework, we derive a distributionally robust variant of Soft Q-learning that enjoys efficient practical implementation and produces policies with robust behaviour at test time. Our formulation provides a unified view on a number of safe RL algorithms and recent empirical successes.
Visual Reasoning with Multi-hop Feature Modulation
Oct 12, 2018
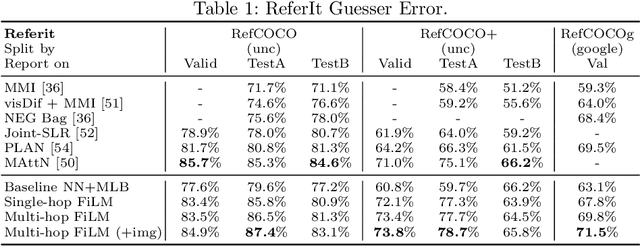
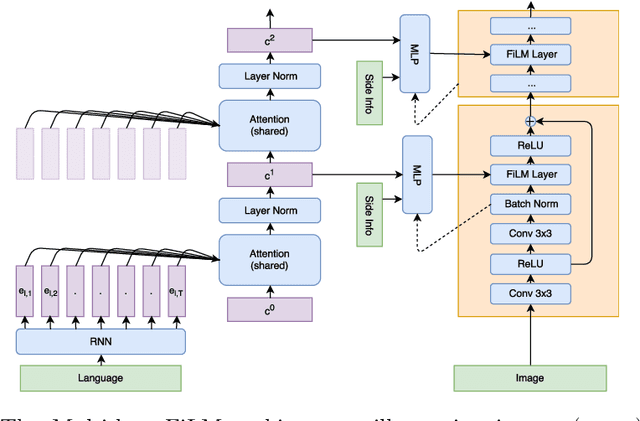
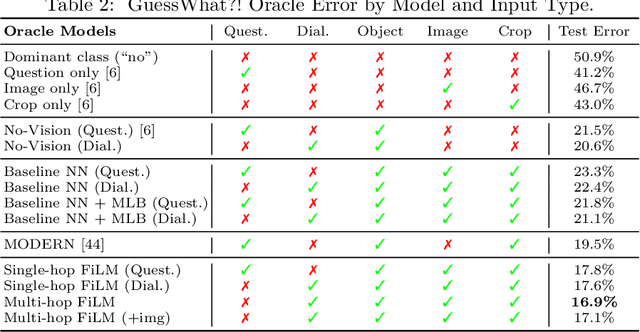
Recent breakthroughs in computer vision and natural language processing have spurred interest in challenging multi-modal tasks such as visual question-answering and visual dialogue. For such tasks, one successful approach is to condition image-based convolutional network computation on language via Feature-wise Linear Modulation (FiLM) layers, i.e., per-channel scaling and shifting. We propose to generate the parameters of FiLM layers going up the hierarchy of a convolutional network in a multi-hop fashion rather than all at once, as in prior work. By alternating between attending to the language input and generating FiLM layer parameters, this approach is better able to scale to settings with longer input sequences such as dialogue. We demonstrate that multi-hop FiLM generation achieves state-of-the-art for the short input sequence task ReferIt --- on-par with single-hop FiLM generation --- while also significantly outperforming prior state-of-the-art and single-hop FiLM generation on the GuessWhat?! visual dialogue task.
Recurrent Neural Networks for Long and Short-Term Sequential Recommendation
Jul 23, 2018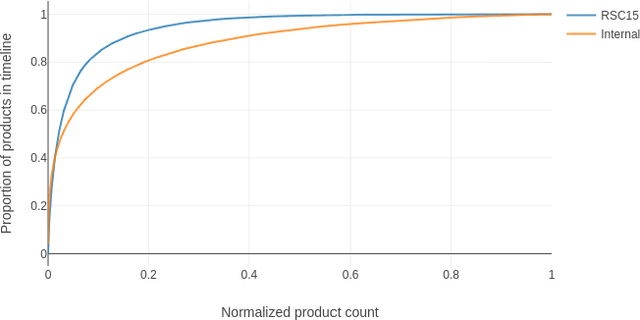
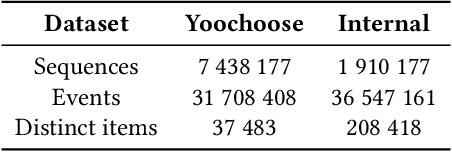
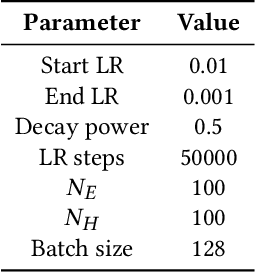
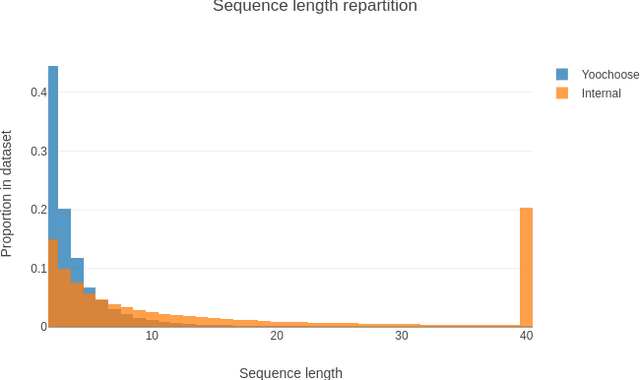
Recommender systems objectives can be broadly characterized as modeling user preferences over short-or long-term time horizon. A large body of previous research studied long-term recommendation through dimensionality reduction techniques applied to the historical user-item interactions. A recently introduced session-based recommendation setting highlighted the importance of modeling short-term user preferences. In this task, Recurrent Neural Networks (RNN) have shown to be successful at capturing the nuances of user's interactions within a short time window. In this paper, we evaluate RNN-based models on both short-term and long-term recommendation tasks. Our experimental results suggest that RNNs are capable of predicting immediate as well as distant user interactions. We also find the best performing configuration to be a stacked RNN with layer normalization and tied item embeddings.
Basket Completion with Multi-task Determinantal Point Processes
May 24, 2018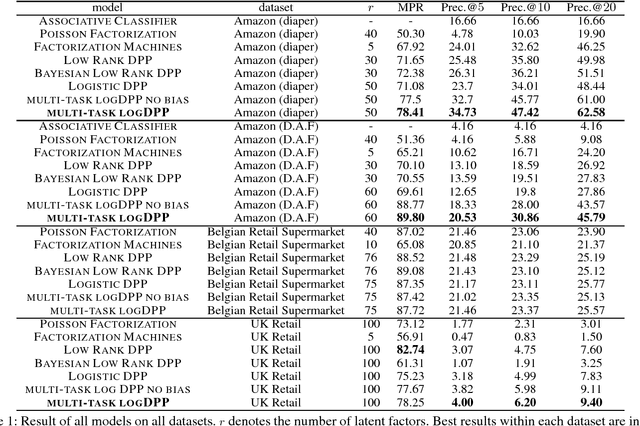
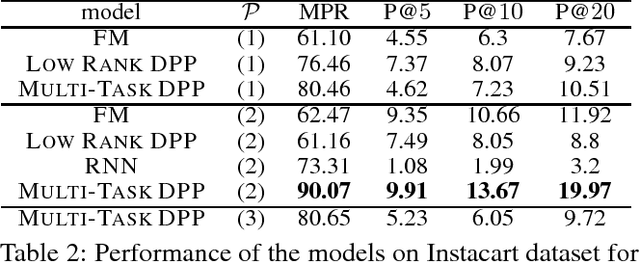
Determinantal point processes (DPPs) have received significant attention in the recent years as an elegant model for a variety of machine learning tasks, due to their ability to elegantly model set diversity and item quality or popularity. Recent work has shown that DPPs can be effective models for product recommendation and basket completion tasks. We present an enhanced DPP model that is specialized for the task of basket completion, the multi-task DPP. We view the basket completion problem as a multi-class classification problem, and leverage ideas from tensor factorization and multi-class classification to design the multi-task DPP model. We evaluate our model on several real-world datasets, and find that the multi-task DPP provides significantly better predictive quality than a number of state-of-the-art models.