 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Convergence of Approximate and Regularized Policy Iteration Schemes
Oct 14, 2019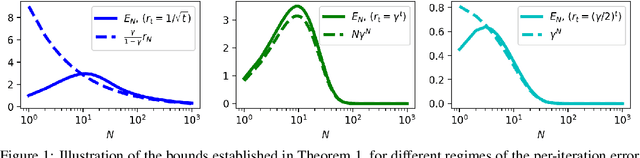
Entropy regularized algorithms such as Soft Q-learning and Soft Actor-Critic, recently showed state-of-the-art performance on a number of challenging reinforcement learning (RL) tasks. The regularized formulation modifies the standard RL objective and thus generally converges to a policy different from the optimal greedy policy of the original RL problem. Practically, it is important to control the sub-optimality of the regularized optimal policy. In this paper, we establish sufficient conditions for convergence of a large class of regularized dynamic programming algorithms, unified under regularized modified policy iteration (MPI) and conservative value iteration (VI) schemes. We provide explicit convergence rates to the optimality depending on the decrease rate of the regularization parameter. Our experiments show that the empirical error closely follows the established theoretical convergence rates. In addition to optimality, we demonstrate two desirable behaviours of the regularized algorithms even in the absence of approximations: robustness to stochasticity of environment and safety of trajectories induced by the policy iterates.
Distributionally Robust Counterfactual Risk Minimization
Jun 14, 2019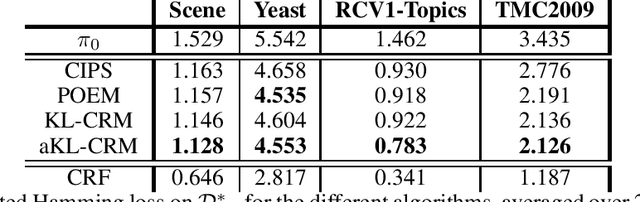
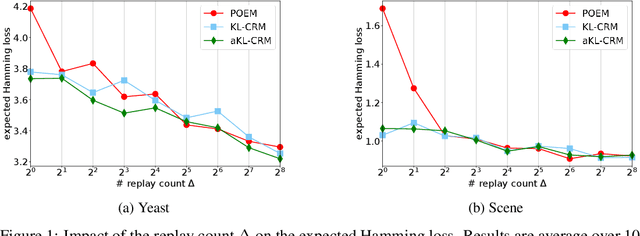
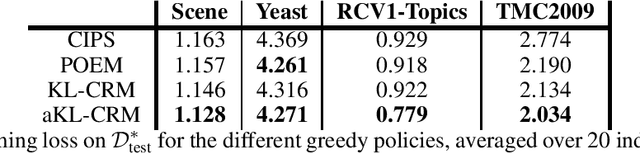
This manuscript introduces the idea of using Distributionally Robust Optimization (DRO) for the Counterfactual Risk Minimization (CRM) problem. Tapping into a rich existing literature, we show that DRO is a principled tool for counterfactual decision making. We also show that well-established solutions to the CRM problem like sample variance penalization schemes are special instances of a more general DRO problem. In this unifying framework, a variety of distributionally robust counterfactual risk estimators can be constructed using various probability distances and divergences as uncertainty measures. We propose the use of Kullback-Leibler divergence as an alternative way to model uncertainty in CRM and derive a new robust counterfactual objective. In our experiments, we show that this approach outperforms the state-of-the-art on four benchmark datasets, validating the relevance of using other uncertainty measures in practical applications.
Distributionally Robust Reinforcement Learning
Feb 23, 2019
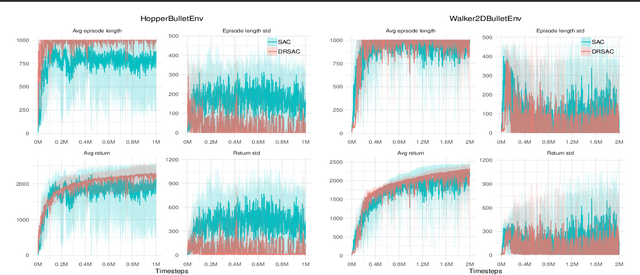
Generalization to unknown/uncertain environments of reinforcement learning algorithms is crucial for real-world applications. In this work, we explicitly consider uncertainty associated with the test environment through an uncertainty set. We formulate the Distributionally Robust Reinforcement Learning (DR-RL) objective that consists in maximizing performance against a worst-case policy in uncertainty set centered at the reference policy. Based on this objective, we derive computationally efficient policy improvement algorithm that benefits from Distributionally Robust Optimization (DRO) guarantees. Further, we propose an iterative procedure that increases stability of learning, called Distributionally Robust Policy Iteration. Combined with maximum entropy framework, we derive a distributionally robust variant of Soft Q-learning that enjoys efficient practical implementation and produces policies with robust behaviour at test time. Our formulation provides a unified view on a number of safe RL algorithms and recent empirical successes.
Action-conditional Sequence Modeling for Recommendation
Sep 07, 2018
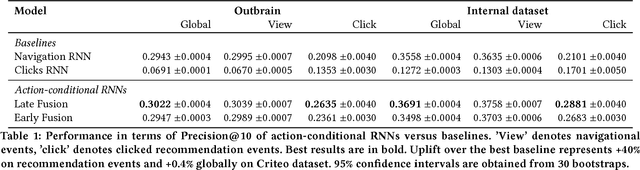
In many online applications interactions between a user and a web-service are organized in a sequential way, e.g., user browsing an e-commerce website. In this setting, recommendation system acts throughout user navigation by showing items. Previous works have addressed this recommendation setup through the task of predicting the next item user will interact with. In particular, Recurrent Neural Networks (RNNs) has been shown to achieve substantial improvements over collaborative filtering baselines. In this paper, we consider interactions triggered by the recommendations of deployed recommender system in addition to browsing behavior. Indeed, it is reported that in online services interactions with recommendations represent up to 30\% of total interactions. Moreover, in practice, recommender system can greatly influence user behavior by promoting specific items. In this paper, we extend the RNN modeling framework by taking into account user interaction with recommended items. We propose and evaluate RNN architectures that consist of the recommendation action module and the state-action fusion module. Using real-world large-scale datasets we demonstrate improved performance on the next item prediction task compared to the baselines.
Recurrent Neural Networks for Long and Short-Term Sequential Recommendation
Jul 23, 2018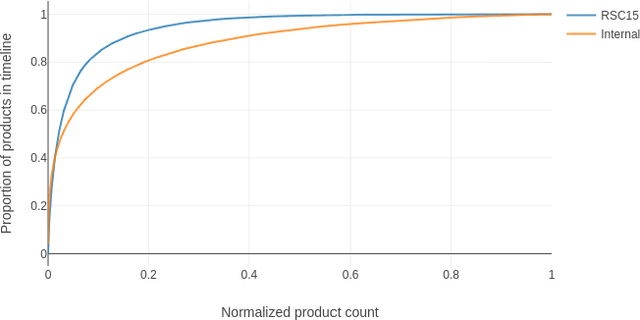
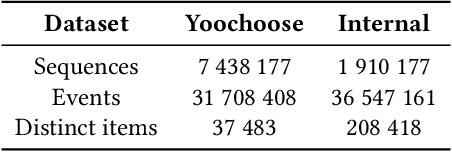
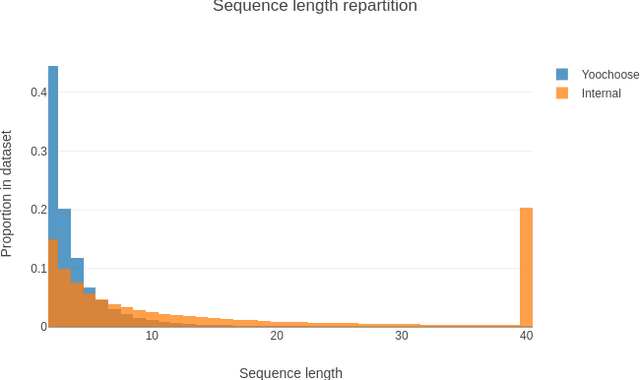
Recommender systems objectives can be broadly characterized as modeling user preferences over short-or long-term time horizon. A large body of previous research studied long-term recommendation through dimensionality reduction techniques applied to the historical user-item interactions. A recently introduced session-based recommendation setting highlighted the importance of modeling short-term user preferences. In this task, Recurrent Neural Networks (RNN) have shown to be successful at capturing the nuances of user's interactions within a short time window. In this paper, we evaluate RNN-based models on both short-term and long-term recommendation tasks. Our experimental results suggest that RNNs are capable of predicting immediate as well as distant user interactions. We also find the best performing configuration to be a stacked RNN with layer normalization and tied item embeddings.
Meta-Prod2Vec - Product Embeddings Using Side-Information for Recommendation
Jul 25, 2016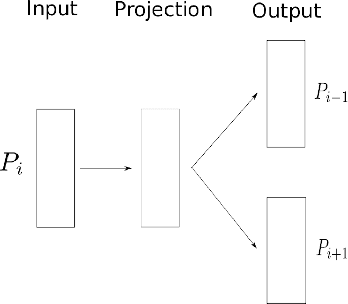

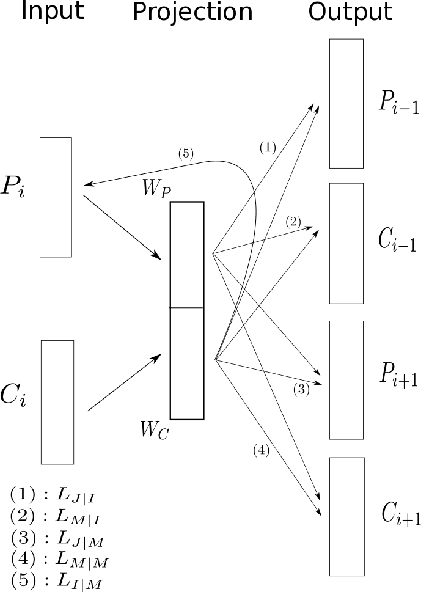

We propose Meta-Prod2vec, a novel method to compute item similarities for recommendation that leverages existing item metadata. Such scenarios are frequently encountered in applications such as content recommendation, ad targeting and web search. Our method leverages past user interactions with items and their attributes to compute low-dimensional embeddings of items. Specifically, the item metadata is in- jected into the model as side information to regularize the item embeddings. We show that the new item representa- tions lead to better performance on recommendation tasks on an open music dataset.