 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributionally Robust Reinforcement Learning
Paper and Code

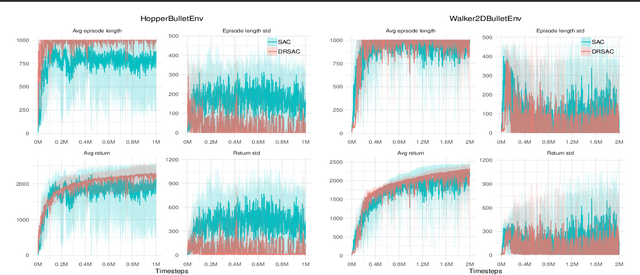
Generalization to unknown/uncertain environments of reinforcement learning algorithms is crucial for real-world applications. In this work, we explicitly consider uncertainty associated with the test environment through an uncertainty set. We formulate the Distributionally Robust Reinforcement Learning (DR-RL) objective that consists in maximizing performance against a worst-case policy in uncertainty set centered at the reference policy. Based on this objective, we derive computationally efficient policy improvement algorithm that benefits from Distributionally Robust Optimization (DRO) guarantees. Further, we propose an iterative procedure that increases stability of learning, called Distributionally Robust Policy Iteration. Combined with maximum entropy framework, we derive a distributionally robust variant of Soft Q-learning that enjoys efficient practical implementation and produces policies with robust behaviour at test time. Our formulation provides a unified view on a number of safe RL algorithms and recent empirical successes.