 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Structural Constraints for Diffusion-based Neural TSP Solvers
Jun 08, 2026Neural combinatorial optimization has recently achieved strong results on the Euclidean Traveling Salesman Problem (TSP) using generative models such as diffusion and consistency models. State-ofthe-art approaches like FT2T combine fast consistency-based prediction with gradient-based inference time refinement. However, gradient search often incurs significant computational overhead and may not align with the discrete structure of feasible solutions. We introduce Projected Consistency Inference (PCI), a plug-and-play, retraining-free alternative that replaces gradient refinement with structure-aware projections: PCI decodes valid Hamiltonian tours from the consistency model output and applies a lightweight local search (e.g., 2-opt). PCI achieves an average optimality gap (OG) of 0.17% on TSP with 500 cities, and 0.31% on TSP with 1000 cities, outperforming FT2T best settings (OG 0.22% and 0.36%, respectively) while reducing the inference time up to 30 to 40%. PCI also exhibits lower variance and memory usage, and can surpass classical heuristics such as LKH3 in rapid solution generation. Our results demonstrate that structure-aware inference time operations provide a practical and principled path for neural TSP solvers, complementing training time objectives.
Bandits attack function optimization
May 05, 2026We consider function optimization as a sequential decision making problem under budget constraint. This constraint limits the number of objective function evaluations allowed during the optimization. We consider an algorithm inspired by a continuous version of a multi-armed bandit problem which attacks this optimization problem by solving the tradeoff between exploration (initial quasi-uniform search of the domain) and exploitation (local optimization around the potentially global maxima). We introduce the so-called Simultaneous Optimistic Optimization (SOO), a deterministic algorithm that works by domain partitioning. The benefit of such approach are the guarantees on the returned solution and the numerical efficiency of the algorithm. We present this machine learning approach to optimization, and provide the empirical assessment of SOO on the CEC'2014 competition on single objective real-parameter numerical optimization test-suite.
* IEEE CEC 2014; 8 pages
Evaluating Interpretable Reinforcement Learning by Distilling Policies into Programs
Mar 11, 2025



There exist applications of reinforcement learning like medicine where policies need to be ''interpretable'' by humans. User studies have shown that some policy classes might be more interpretable than others. However, it is costly to conduct human studies of policy interpretability. Furthermore, there is no clear definition of policy interpretabiliy, i.e., no clear metrics for interpretability and thus claims depend on the chosen definition. We tackle the problem of empirically evaluating policies interpretability without humans. Despite this lack of clear definition, researchers agree on the notions of ''simulatability'': policy interpretability should relate to how humans understand policy actions given states. To advance research in interpretable reinforcement learning, we contribute a new methodology to evaluate policy interpretability. This new methodology relies on proxies for simulatability that we use to conduct a large-scale empirical evaluation of policy interpretability. We use imitation learning to compute baseline policies by distilling expert neural networks into small programs. We then show that using our methodology to evaluate the baselines interpretability leads to similar conclusions as user studies. We show that increasing interpretability does not necessarily reduce performances and can sometimes increase them. We also show that there is no policy class that better trades off interpretability and performance across tasks making it necessary for researcher to have methodologies for comparing policies interpretability.
IDEQ: an improved diffusion model for the TSP
Dec 18, 2024



We investigate diffusion models to solve the Traveling Salesman Problem. Building on the recent DIFUSCO and T2TCO approaches, we propose IDEQ. IDEQ improves the quality of the solutions by leveraging the constrained structure of the state space of the TSP. Another key component of IDEQ consists in replacing the last stages of DIFUSCO curriculum learning by considering a uniform distribution over the Hamiltonian tours whose orbits by the 2-opt operator converge to the optimal solution as the training objective. Our experiments show that IDEQ improves the state of the art for such neural network based techniques on synthetic instances. More importantly, our experiments show that IDEQ performs very well on the instances of the TSPlib, a reference benchmark in the TSP community: it closely matches the performance of the best heuristics, LKH3, being even able to obtain better solutions than LKH3 on 2 instances of the TSPlib defined on 1577 and 3795 cities. IDEQ obtains 0.3% optimality gap on TSP instances made of 500 cities, and 0.5% on TSP instances with 1000 cities. This sets a new SOTA for neural based methods solving the TSP. Moreover, IDEQ exhibits a lower variance and better scales-up with the number of cities with regards to DIFUSCO and T2TCO.
Interpretable and Editable Programmatic Tree Policies for Reinforcement Learning
May 23, 2024



Deep reinforcement learning agents are prone to goal misalignments. The black-box nature of their policies hinders the detection and correction of such misalignments, and the trust necessary for real-world deployment. So far, solutions learning interpretable policies are inefficient or require many human priors. We propose INTERPRETER, a fast distillation method producing INTerpretable Editable tRee Programs for ReinforcEmenT lEaRning. We empirically demonstrate that INTERPRETER compact tree programs match oracles across a diverse set of sequential decision tasks and evaluate the impact of our design choices on interpretability and performances. We show that our policies can be interpreted and edited to correct misalignments on Atari games and to explain real farming strategies.
Towards a Research Community in Interpretable Reinforcement Learning: the InterpPol Workshop
Apr 16, 2024
Embracing the pursuit of intrinsically explainable reinforcement learning raises crucial questions: what distinguishes explainability from interpretability? Should explainable and interpretable agents be developed outside of domains where transparency is imperative? What advantages do interpretable policies offer over neural networks? How can we rigorously define and measure interpretability in policies, without user studies? What reinforcement learning paradigms,are the most suited to develop interpretable agents? Can Markov Decision Processes integrate interpretable state representations? In addition to motivate an Interpretable RL community centered around the aforementioned questions, we propose the first venue dedicated to Interpretable RL: the InterpPol Workshop.
PAQA: Toward ProActive Open-Retrieval Question Answering
Feb 26, 2024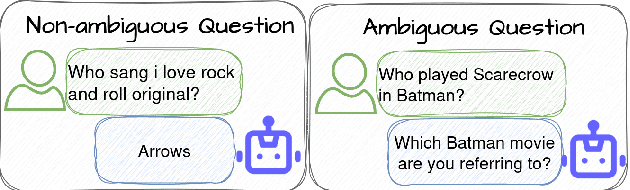

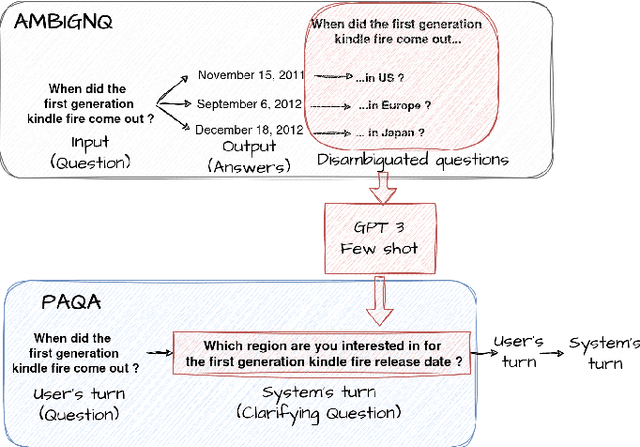
Conversational systems have made significant progress in generating natural language responses. However, their potential as conversational search systems is currently limited due to their passive role in the information-seeking process. One major limitation is the scarcity of datasets that provide labelled ambiguous questions along with a supporting corpus of documents and relevant clarifying questions. This work aims to tackle the challenge of generating relevant clarifying questions by taking into account the inherent ambiguities present in both user queries and documents. To achieve this, we propose PAQA, an extension to the existing AmbiNQ dataset, incorporating clarifying questions. We then evaluate various models and assess how passage retrieval impacts ambiguity detection and the generation of clarifying questions. By addressing this gap in conversational search systems, we aim to provide additional supervision to enhance their active participation in the information-seeking process and provide users with more accurate results.
Augmenting Ad-Hoc IR Dataset for Interactive Conversational Search
Nov 10, 2023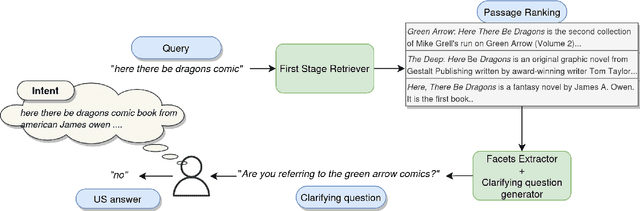
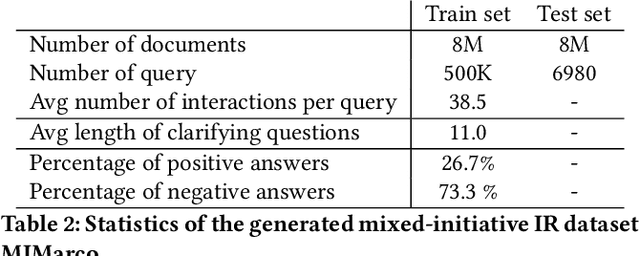
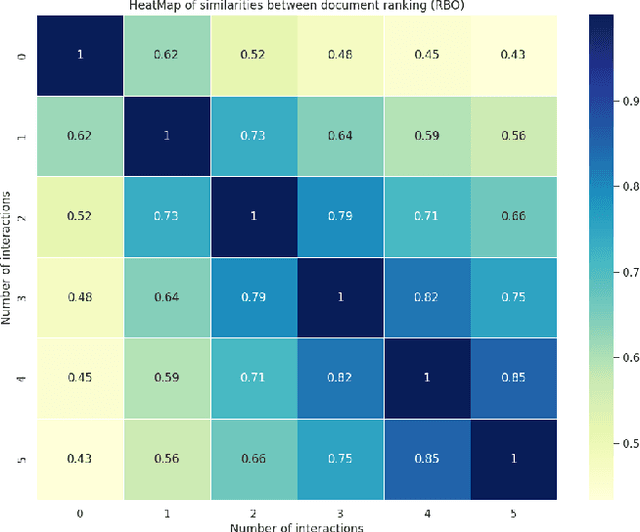
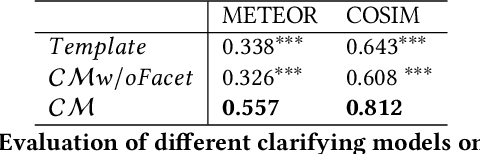
A peculiarity of conversational search systems is that they involve mixed-initiatives such as system-generated query clarifying questions. Evaluating those systems at a large scale on the end task of IR is very challenging, requiring adequate datasets containing such interactions. However, current datasets only focus on either traditional ad-hoc IR tasks or query clarification tasks, the latter being usually seen as a reformulation task from the initial query. The only two datasets known to us that contain both document relevance judgments and the associated clarification interactions are Qulac and ClariQ. Both are based on the TREC Web Track 2009-12 collection, but cover a very limited number of topics (237 topics), far from being enough for training and testing conversational IR models. To fill the gap, we propose a methodology to automatically build large-scale conversational IR datasets from ad-hoc IR datasets in order to facilitate explorations on conversational IR. Our methodology is based on two processes: 1) generating query clarification interactions through query clarification and answer generators, and 2) augmenting ad-hoc IR datasets with simulated interactions. In this paper, we focus on MsMarco and augment it with query clarification and answer simulations. We perform a thorough evaluation showing the quality and the relevance of the generated interactions for each initial query. This paper shows the feasibility and utility of augmenting ad-hoc IR datasets for conversational IR.
Limits of Actor-Critic Algorithms for Decision Tree Policies Learning in IBMDPs
Sep 23, 2023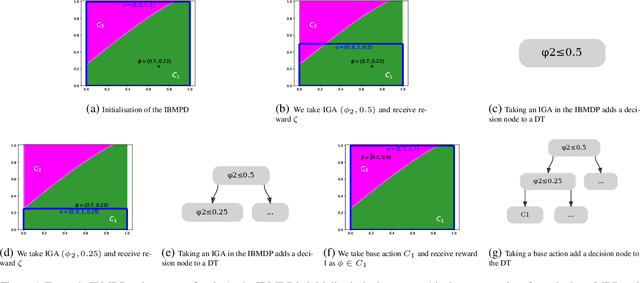
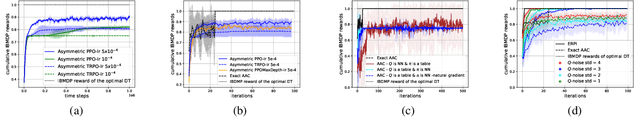
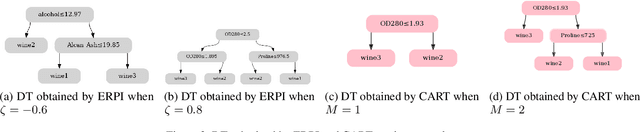
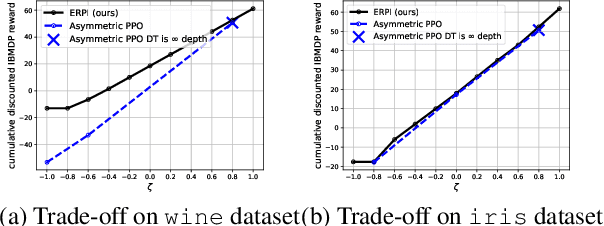
Interpretability of AI models allows for user safety checks to build trust in such AIs. In particular, Decision Trees (DTs) provide a global look at the learned model and transparently reveal which features of the input are critical for making a decision. However, interpretability is hindered if the DT is too large. To learn compact trees, a recent Reinforcement Learning (RL) framework has been proposed to explore the space of DTs using deep RL. This framework augments a decision problem (e.g. a supervised classification task) with additional actions that gather information about the features of an otherwise hidden input. By appropriately penalizing these actions, the agent learns to optimally trade-off size and performance of DTs. In practice, a reactive policy for a partially observable Markov decision process (MDP) needs to be learned, which is still an open problem. We show in this paper that deep RL can fail even on simple toy tasks of this class. However, when the underlying decision problem is a supervised classification task, we show that finding the optimal tree can be cast as a fully observable Markov decision problem and be solved efficiently, giving rise to a new family of algorithms for learning DTs that go beyond the classical greedy maximization ones.
Discovering the Interpretability-Performance Pareto Front of Decision Trees with Dynamic Programming
Sep 22, 2023



Decision trees are known to be intrinsically interpretable as they can be inspected and interpreted by humans. Furthermore, recent hardware advances have rekindled an interest for optimal decision tree algorithms, that produce more accurate trees than the usual greedy approaches. However, these optimal algorithms return a single tree optimizing a hand defined interpretability-performance trade-off, obtained by specifying a maximum number of decision nodes, giving no further insights about the quality of this trade-off. In this paper, we propose a new Markov Decision Problem (MDP) formulation for finding optimal decision trees. The main interest of this formulation is that we can compute the optimal decision trees for several interpretability-performance trade-offs by solving a single dynamic program, letting the user choose a posteriori the tree that best suits their needs. Empirically, we show that our method is competitive with state-of-the-art algorithms in terms of accuracy and runtime while returning a whole set of trees on the interpretability-performance Pareto front.