 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Research Community in Interpretable Reinforcement Learning: the InterpPol Workshop
Apr 16, 2024
Embracing the pursuit of intrinsically explainable reinforcement learning raises crucial questions: what distinguishes explainability from interpretability? Should explainable and interpretable agents be developed outside of domains where transparency is imperative? What advantages do interpretable policies offer over neural networks? How can we rigorously define and measure interpretability in policies, without user studies? What reinforcement learning paradigms,are the most suited to develop interpretable agents? Can Markov Decision Processes integrate interpretable state representations? In addition to motivate an Interpretable RL community centered around the aforementioned questions, we propose the first venue dedicated to Interpretable RL: the InterpPol Workshop.
MIDAS: Deep learning human action intention prediction from natural eye movement patterns
Jan 22, 2022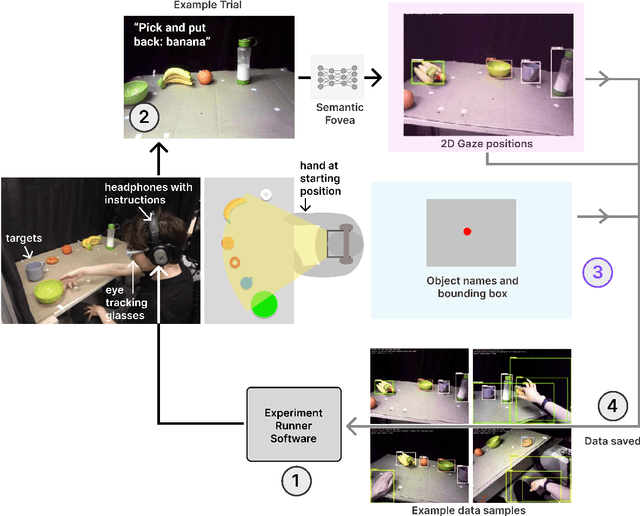
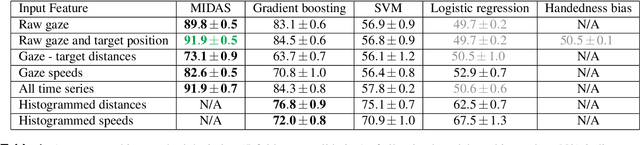
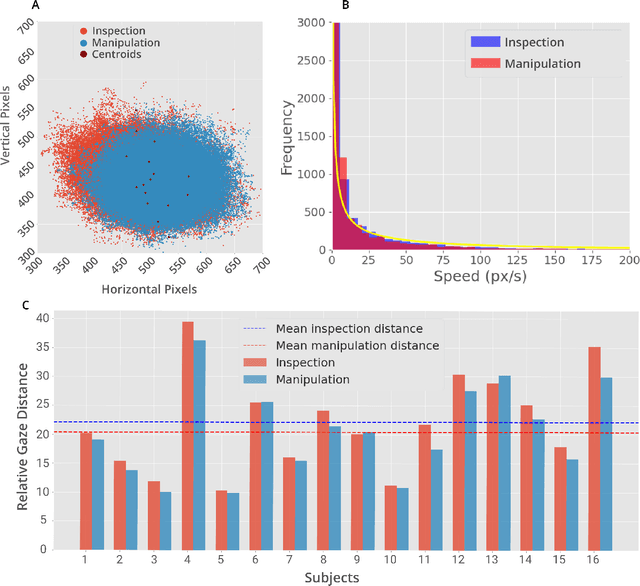
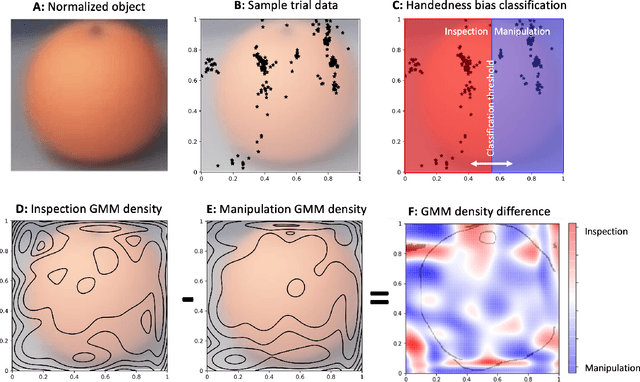
Eye movements have long been studied as a window into the attentional mechanisms of the human brain and made accessible as novelty style human-machine interfaces. However, not everything that we gaze upon, is something we want to interact with; this is known as the Midas Touch problem for gaze interfaces. To overcome the Midas Touch problem, present interfaces tend not to rely on natural gaze cues, but rather use dwell time or gaze gestures. Here we present an entirely data-driven approach to decode human intention for object manipulation tasks based solely on natural gaze cues. We run data collection experiments where 16 participants are given manipulation and inspection tasks to be performed on various objects on a table in front of them. The subjects' eye movements are recorded using wearable eye-trackers allowing the participants to freely move their head and gaze upon the scene. We use our Semantic Fovea, a convolutional neural network model to obtain the objects in the scene and their relation to gaze traces at every frame. We then evaluate the data and examine several ways to model the classification task for intention prediction. Our evaluation shows that intention prediction is not a naive result of the data, but rather relies on non-linear temporal processing of gaze cues. We model the task as a time series classification problem and design a bidirectional Long-Short-Term-Memory (LSTM) network architecture to decode intentions. Our results show that we can decode human intention of motion purely from natural gaze cues and object relative position, with $91.9\%$ accuracy. Our work demonstrates the feasibility of natural gaze as a Zero-UI interface for human-machine interaction, i.e., users will only need to act naturally, and do not need to interact with the interface itself or deviate from their natural eye movement patterns.
Enabling risk-aware Reinforcement Learning for medical interventions through uncertainty decomposition
Sep 16, 2021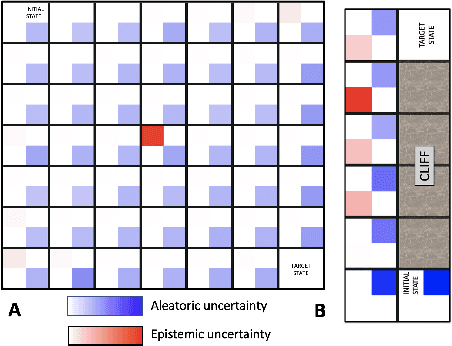

Reinforcement Learning (RL) is emerging as tool for tackling complex control and decision-making problems. However, in high-risk environments such as healthcare, manufacturing, automotive or aerospace, it is often challenging to bridge the gap between an apparently optimal policy learnt by an agent and its real-world deployment, due to the uncertainties and risk associated with it. Broadly speaking RL agents face two kinds of uncertainty, 1. aleatoric uncertainty, which reflects randomness or noise in the dynamics of the world, and 2. epistemic uncertainty, which reflects the bounded knowledge of the agent due to model limitations and finite amount of information/data the agent has acquired about the world. These two types of uncertainty carry fundamentally different implications for the evaluation of performance and the level of risk or trust. Yet these aleatoric and epistemic uncertainties are generally confounded as standard and even distributional RL is agnostic to this difference. Here we propose how a distributional approach (UA-DQN) can be recast to render uncertainties by decomposing the net effects of each uncertainty. We demonstrate the operation of this method in grid world examples to build intuition and then show a proof of concept application for an RL agent operating as a clinical decision support system in critical care