 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuromuscular Reinforcement Learning to Actuate Human Limbs through FES
Sep 16, 2022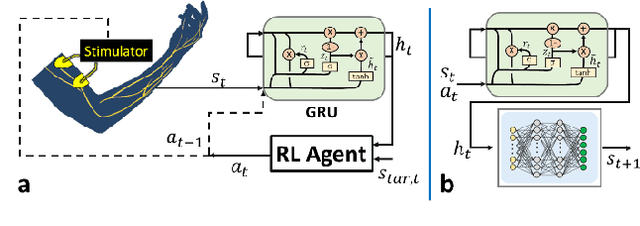
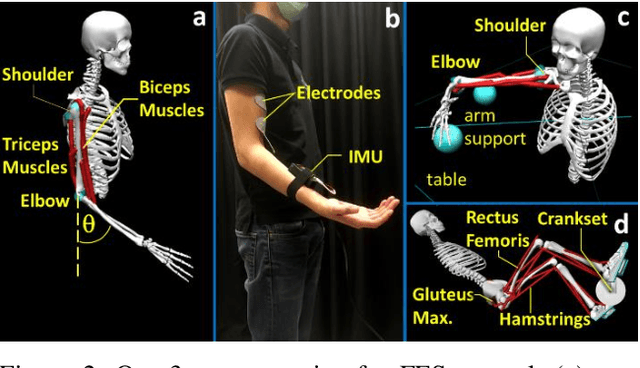
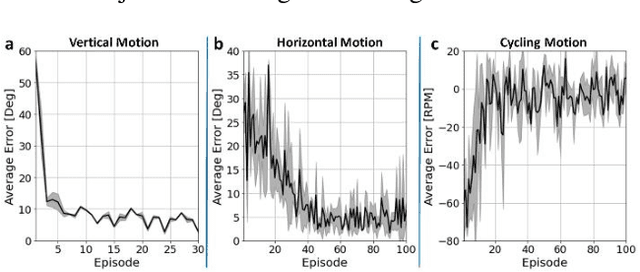

Functional Electrical Stimulation (FES) is a technique to evoke muscle contraction through low-energy electrical signals. FES can animate paralysed limbs. Yet, an open challenge remains on how to apply FES to achieve desired movements. This challenge is accentuated by the complexities of human bodies and the non-stationarities of the muscles' responses. The former causes difficulties in performing inverse dynamics, and the latter causes control performance to degrade over extended periods of use. Here, we engage the challenge via a data-driven approach. Specifically, we learn to control FES through Reinforcement Learning (RL) which can automatically customise the stimulation for the patients. However, RL typically has Markovian assumptions while FES control systems are non-Markovian because of the non-stationarities. To deal with this problem, we use a recurrent neural network to create Markovian state representations. We cast FES controls into RL problems and train RL agents to control FES in different settings in both simulations and the real world. The results show that our RL controllers can maintain control performances over long periods and have better stimulation characteristics than PID controllers.
The role of haptic communication in dyadic collaborative object manipulation tasks
Mar 02, 2022
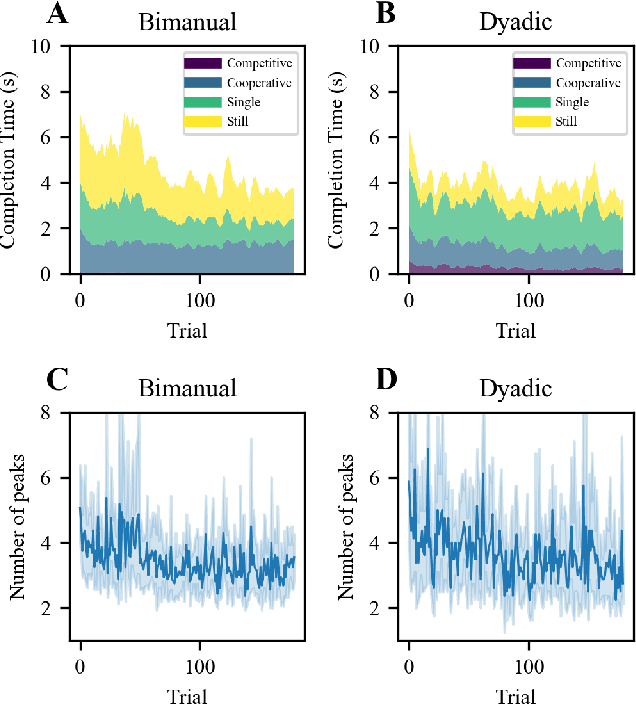
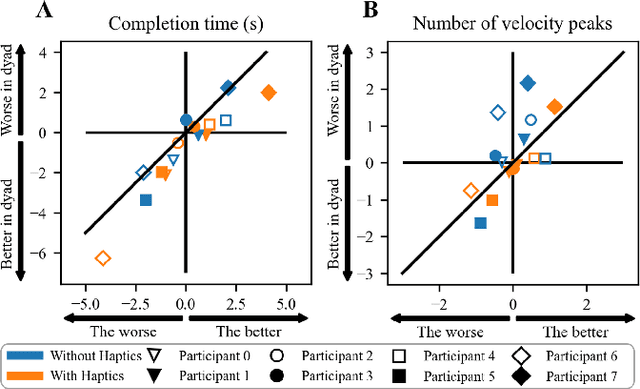
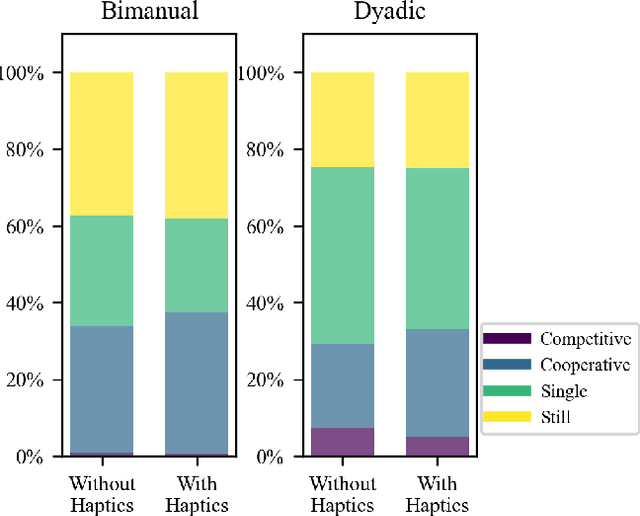
Intuitive and efficient physical human-robot collaboration relies on the mutual observability of the human and the robot, i.e. the two entities being able to interpret each other's intentions and actions. This is remedied by a myriad of methods involving human sensing or intention decoding, as well as human-robot turn-taking and sequential task planning. However, the physical interaction establishes a rich channel of communication through forces, torques and haptics in general, which is often overlooked in industrial implementations of human-robot interaction. In this work, we investigate the role of haptics in human collaborative physical tasks, to identify how to integrate physical communication in human-robot teams. We present a task to balance a ball at a target position on a board either bimanually by one participant, or dyadically by two participants, with and without haptic information. The task requires that the two sides coordinate with each other, in real-time, to balance the ball at the target. We found that with training the completion time and number of velocity peaks of the ball decreased, and that participants gradually became consistent in their braking strategy. Moreover we found that the presence of haptic information improved the performance (decreased completion time) and led to an increase in overall cooperative movements. Overall, our results show that humans can better coordinate with one another when haptic feedback is available. These results also highlight the likely importance of haptic communication in human-robot physical interaction, both as a tool to infer human intentions and to make the robot behaviour interpretable to humans.
The Response Shift Paradigm to Quantify Human Trust in AI Recommendations
Feb 16, 2022Explainability, interpretability and how much they affect human trust in AI systems are ultimately problems of human cognition as much as machine learning, yet the effectiveness of AI recommendations and the trust afforded by end-users are typically not evaluated quantitatively. We developed and validated a general purpose Human-AI interaction paradigm which quantifies the impact of AI recommendations on human decisions. In our paradigm we confronted human users with quantitative prediction tasks: asking them for a first response, before confronting them with an AI's recommendations (and explanation), and then asking the human user to provide an updated final response. The difference between final and first responses constitutes the shift or sway in the human decision which we use as metric of the AI's recommendation impact on the human, representing the trust they place on the AI. We evaluated this paradigm on hundreds of users through Amazon Mechanical Turk using a multi-branched experiment confronting users with good/poor AI systems that had good, poor or no explainability. Our proof-of-principle paradigm allows one to quantitatively compare the rapidly growing set of XAI/IAI approaches in terms of their effect on the end-user and opens up the possibility of (machine) learning trust.
MIDAS: Deep learning human action intention prediction from natural eye movement patterns
Jan 22, 2022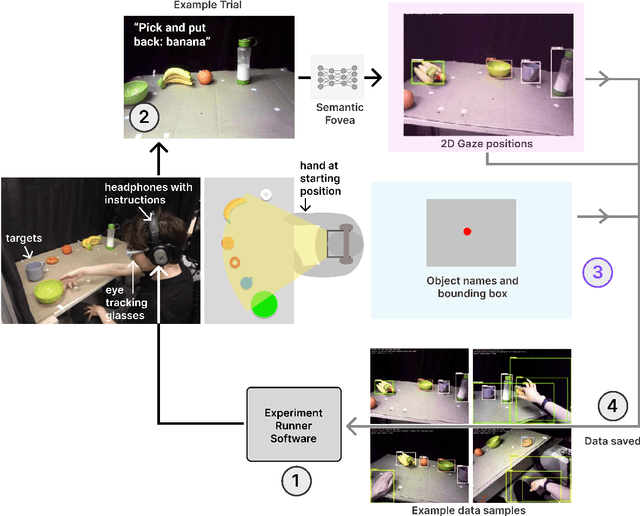
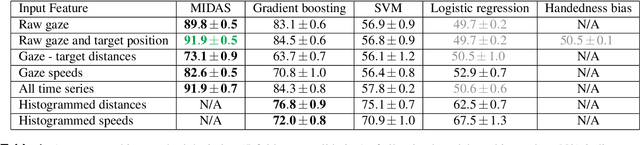
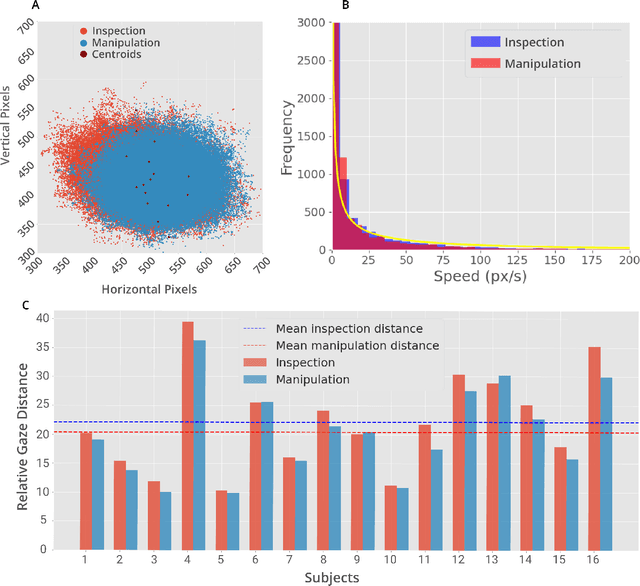
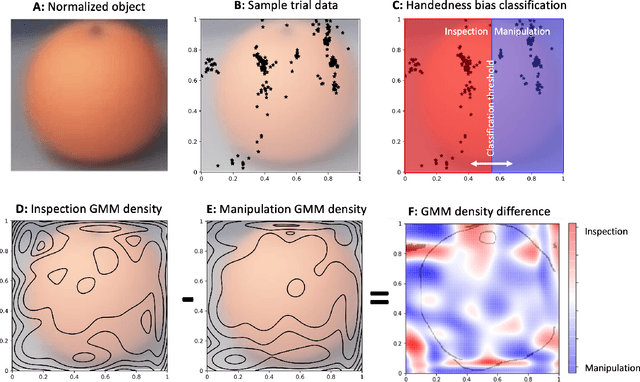
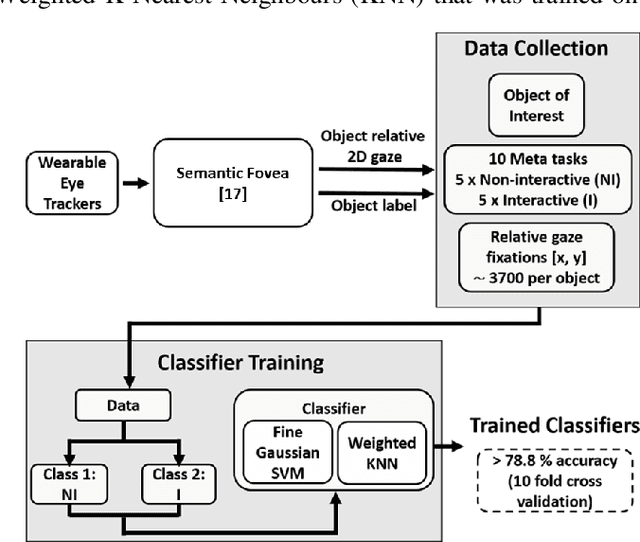
Eye movements have long been studied as a window into the attentional mechanisms of the human brain and made accessible as novelty style human-machine interfaces. However, not everything that we gaze upon, is something we want to interact with; this is known as the Midas Touch problem for gaze interfaces. To overcome the Midas Touch problem, present interfaces tend not to rely on natural gaze cues, but rather use dwell time or gaze gestures. Here we present an entirely data-driven approach to decode human intention for object manipulation tasks based solely on natural gaze cues. We run data collection experiments where 16 participants are given manipulation and inspection tasks to be performed on various objects on a table in front of them. The subjects' eye movements are recorded using wearable eye-trackers allowing the participants to freely move their head and gaze upon the scene. We use our Semantic Fovea, a convolutional neural network model to obtain the objects in the scene and their relation to gaze traces at every frame. We then evaluate the data and examine several ways to model the classification task for intention prediction. Our evaluation shows that intention prediction is not a naive result of the data, but rather relies on non-linear temporal processing of gaze cues. We model the task as a time series classification problem and design a bidirectional Long-Short-Term-Memory (LSTM) network architecture to decode intentions. Our results show that we can decode human intention of motion purely from natural gaze cues and object relative position, with $91.9\%$ accuracy. Our work demonstrates the feasibility of natural gaze as a Zero-UI interface for human-machine interaction, i.e., users will only need to act naturally, and do not need to interact with the interface itself or deviate from their natural eye movement patterns.
I am Robot: Neuromuscular Reinforcement Learning to Actuate Human Limbs through Functional Electrical Stimulation
Mar 09, 2021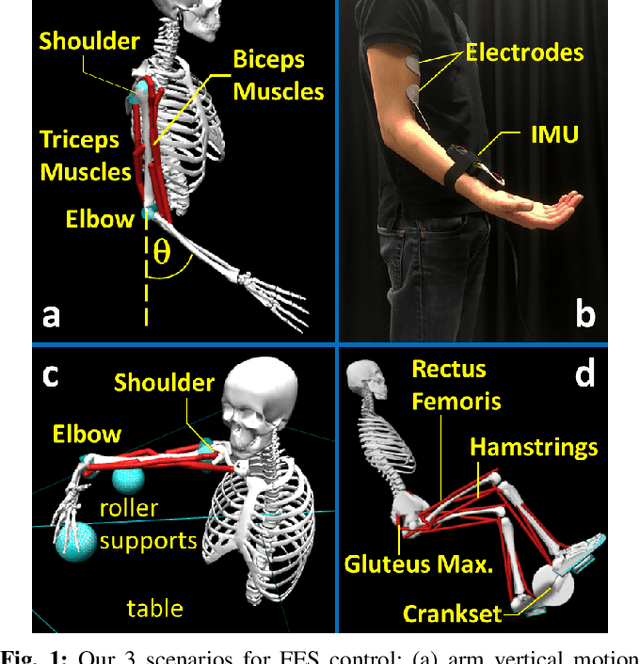
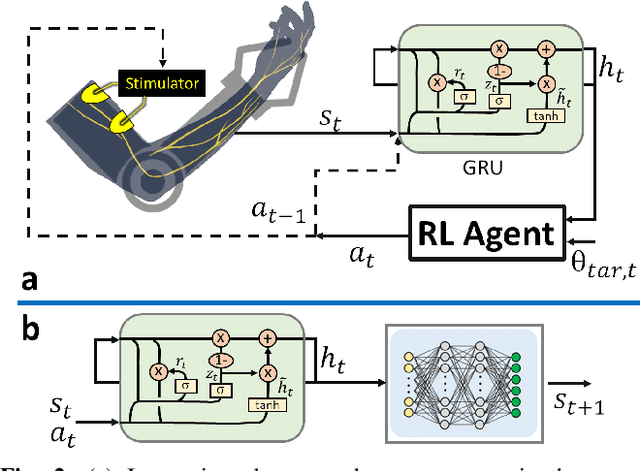
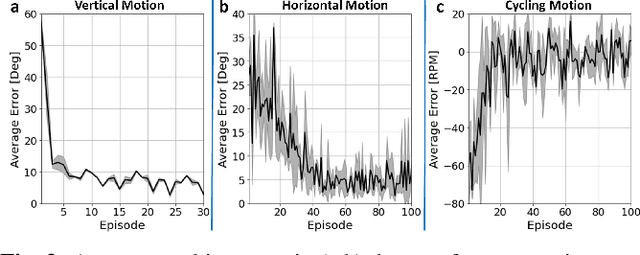
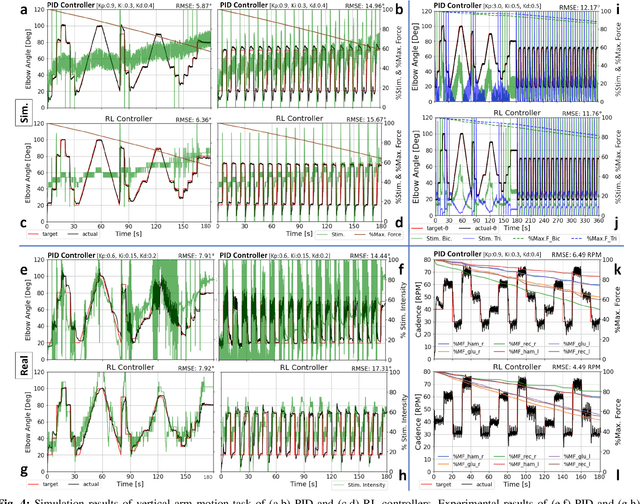
Human movement disorders or paralysis lead to the loss of control of muscle activation and thus motor control. Functional Electrical Stimulation (FES) is an established and safe technique for contracting muscles by stimulating the skin above a muscle to induce its contraction. However, an open challenge remains on how to restore motor abilities to human limbs through FES, as the problem of controlling the stimulation is unclear. We are taking a robotics perspective on this problem, by developing robot learning algorithms that control the ultimate humanoid robot, the human body, through electrical muscle stimulation. Human muscles are not trivial to control as actuators due to their force production being non-stationary as a result of fatigue and other internal state changes, in contrast to robot actuators which are well-understood and stationary over broad operation ranges. We present our Deep Reinforcement Learning approach to the control of human muscles with FES, using a recurrent neural network for dynamic state representation, to overcome the unobserved elements of the behaviour of human muscles under external stimulation. We demonstrate our technique both in neuromuscular simulations but also experimentally on a human. Our results show that our controller can learn to manipulate human muscles, applying appropriate levels of stimulation to achieve the given tasks while compensating for advancing muscle fatigue which arises throughout the tasks. Additionally, our technique can learn quickly enough to be implemented in real-world human-in-the-loop settings.
Gaze-contingent decoding of human navigation intention on an autonomous wheelchair platform
Mar 04, 2021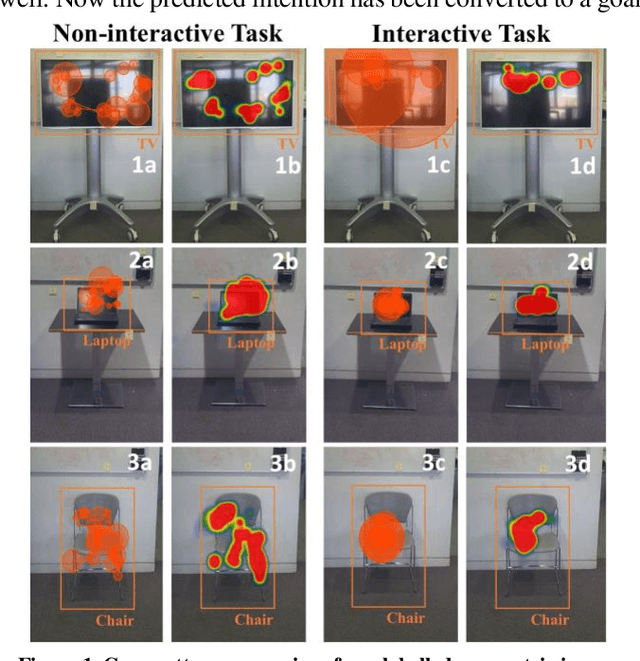

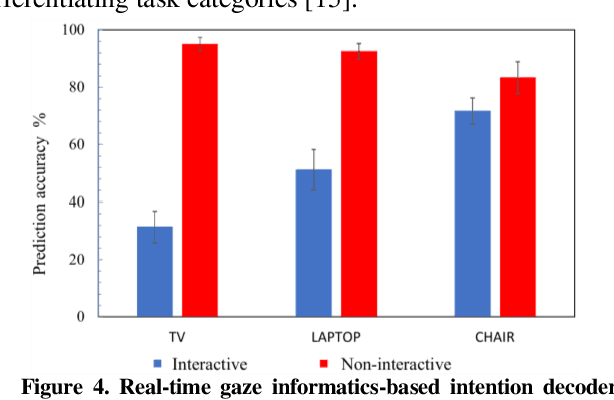
We have pioneered the Where-You-Look-Is Where-You-Go approach to controlling mobility platforms by decoding how the user looks at the environment to understand where they want to navigate their mobility device. However, many natural eye-movements are not relevant for action intention decoding, only some are, which places a challenge on decoding, the so-called Midas Touch Problem. Here, we present a new solution, consisting of 1. deep computer vision to understand what object a user is looking at in their field of view, with 2. an analysis of where on the object's bounding box the user is looking, to 3. use a simple machine learning classifier to determine whether the overt visual attention on the object is predictive of a navigation intention to that object. Our decoding system ultimately determines whether the user wants to drive to e.g., a door or just looks at it. Crucially, we find that when users look at an object and imagine they were moving towards it, the resulting eye-movements from this motor imagery (akin to neural interfaces) remain decodable. Once a driving intention and thus also the location is detected our system instructs our autonomous wheelchair platform, the A.Eye-Drive, to navigate to the desired object while avoiding static and moving obstacles. Thus, for navigation purposes, we have realised a cognitive-level human interface, as it requires the user only to cognitively interact with the desired goal, not to continuously steer their wheelchair to the target (low-level human interfacing).
Non-invasive Cognitive-level Human Interfacing for the Robotic Restoration of Reaching & Grasping
Feb 25, 2021
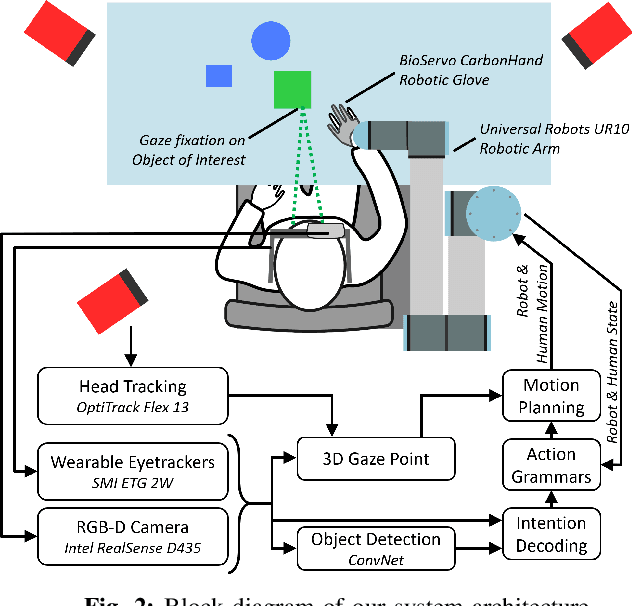
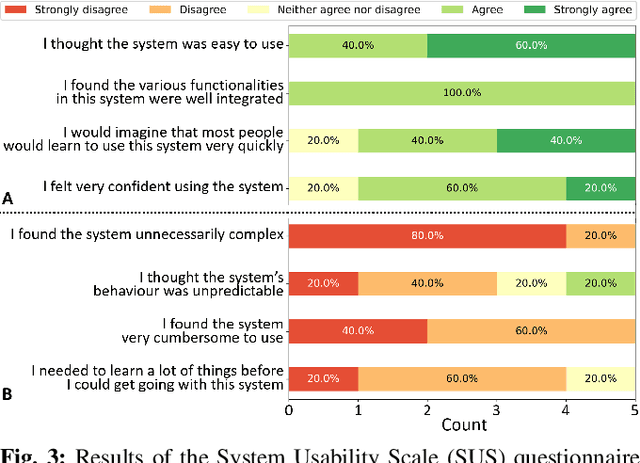
Assistive and Wearable Robotics have the potential to support humans with different types of motor impairments to become independent and fulfil their activities of daily living successfully. The success of these robot systems, however, relies on the ability to meaningfully decode human action intentions and carry them out appropriately. Neural interfaces have been explored for use in such system with several successes, however, they tend to be invasive and require training periods in the order of months. We present a robotic system for human augmentation, capable of actuating the user's arm and fingers for them, effectively restoring the capability of reaching, grasping and manipulating objects; controlled solely through the user's eye movements. We combine wearable eye tracking, the visual context of the environment and the structural grammar of human actions to create a cognitive-level assistive robotic setup that enables the users in fulfilling activities of daily living, while conserving interpretability, and the agency of the user. The interface is worn, calibrated and ready to use within 5 minutes. Users learn to control and make successful use of the system with an additional 5 minutes of interaction. The system is tested with 5 healthy participants, showing an average success rate of $96.6\%$ on first attempt across 6 tasks.
Real-World Human-Robot Collaborative Reinforcement Learning
Mar 02, 2020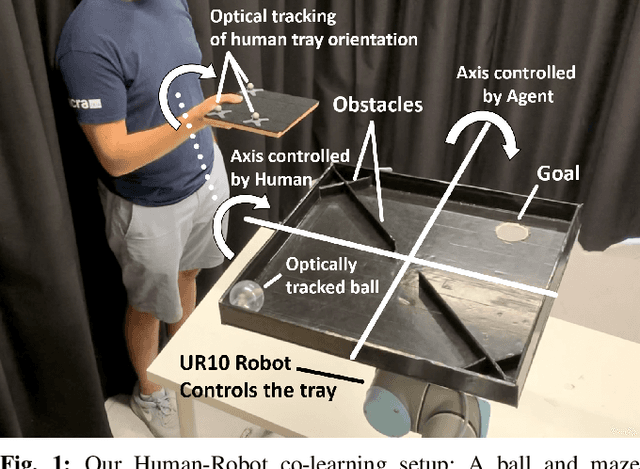
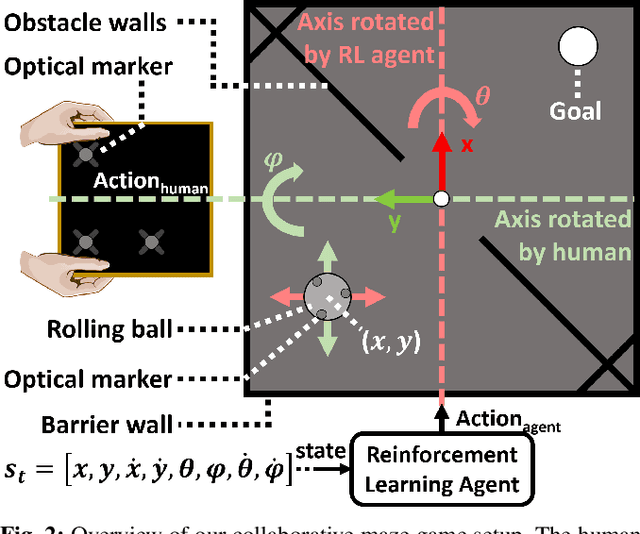
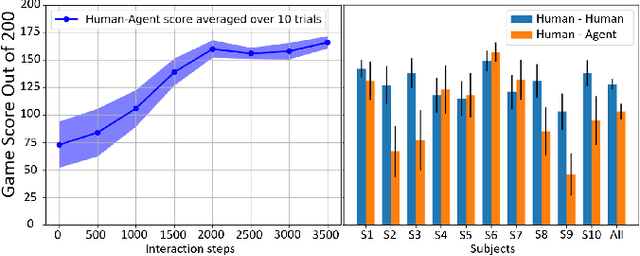
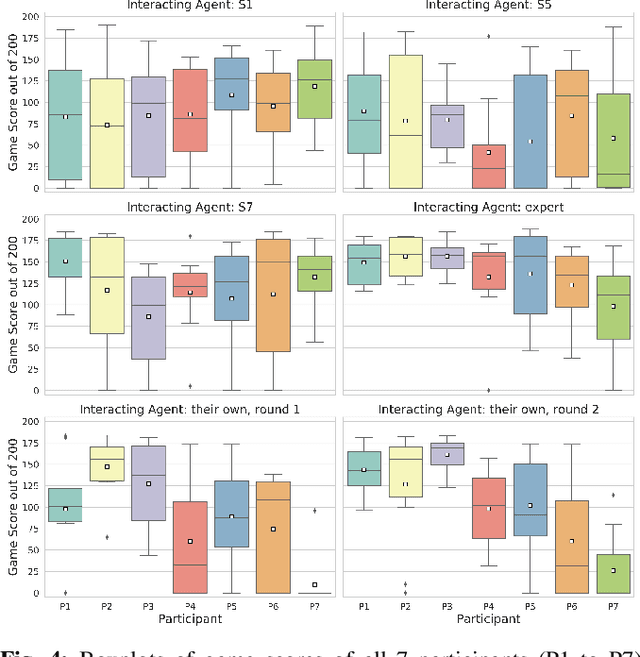
The intuitive collaboration of humans and intelligent robots (embodied AI) in the real-world is an essential objective for many desirable applications of robotics. Whilst there is much research regarding explicit communication, we focus on how humans and robots interact implicitly, on motor adaptation level. We present a real-world setup of a human-robot collaborative maze game, designed to be non-trivial and only solvable through collaboration, by limiting the actions to rotations of two orthogonal axes, and assigning each axes to one player. This results in neither the human nor the agent being able to solve the game on their own. We use a state-of-the-art reinforcement learning algorithm for the robotic agent, and achieve results within 30 minutes of real-world play, without any type of pre-training. We then use this system to perform systematic experiments on human/agent behaviour and adaptation when co-learning a policy for the collaborative game. We present results on how co-policy learning occurs over time between the human and the robotic agent resulting in each participant's agent serving as a representation of how they would play the game. This allows us to relate a person's success when playing with different agents than their own, by comparing the policy of the agent with that of their own agent.
Human-Robot Collaboration via Deep Reinforcement Learning of Real-World Interactions
Dec 02, 2019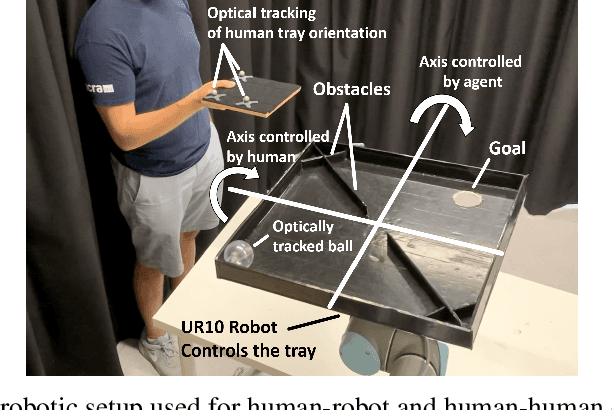
We present a robotic setup for real-world testing and evaluation of human-robot and human-human collaborative learning. Leveraging the sample-efficiency of the Soft Actor-Critic algorithm, we have implemented a robotic platform able to learn a non-trivial collaborative task with a human partner, without pre-training in simulation, and using only 30 minutes of real-world interactions. This enables us to study Human-Robot and Human-Human collaborative learning through real-world interactions. We present preliminary results, showing that state-of-the-art deep learning methods can take human-robot collaborative learning a step closer to that of humans interacting with each other.
Reinforcement Learning with Structured Hierarchical Grammar Representations of Actions
Oct 23, 2019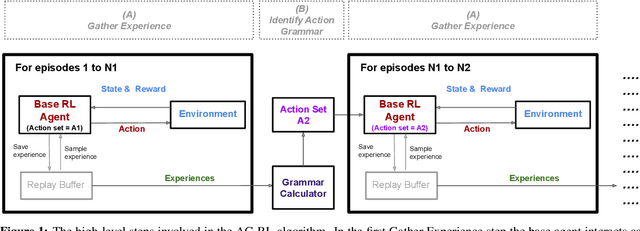
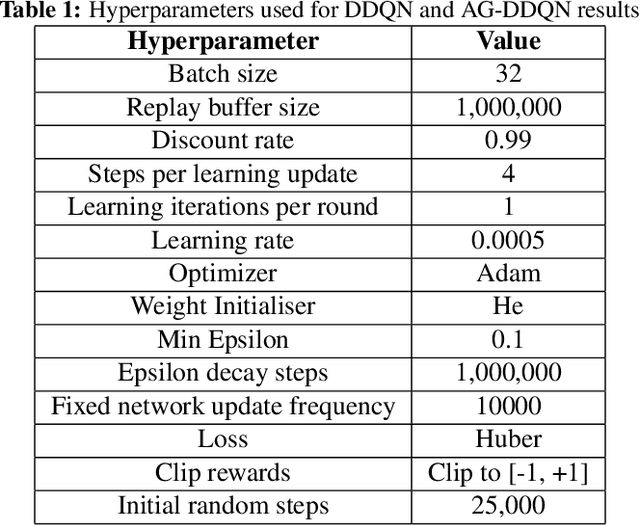

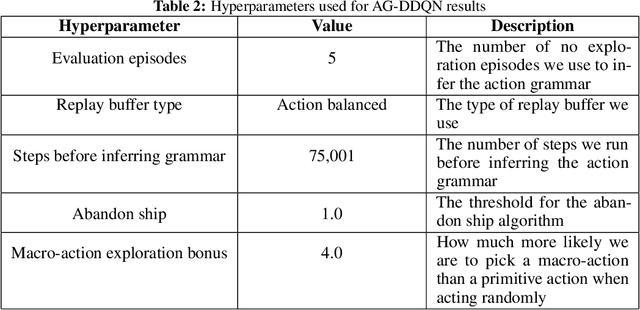
From a young age humans learn to use grammatical principles to hierarchically combine words into sentences. Action grammars is the parallel idea, that there is an underlying set of rules (a "grammar") that govern how we hierarchically combine actions to form new, more complex actions. We introduce the Action Grammar Reinforcement Learning (AG-RL) framework which leverages the concept of action grammars to consistently improve the sample efficiency of Reinforcement Learning agents. AG-RL works by using a grammar inference algorithm to infer the "action grammar" of an agent midway through training. The agent's action space is then augmented with macro-actions identified by the grammar. We apply this framework to Double Deep Q-Learning (AG-DDQN) and a discrete action version of Soft Actor-Critic (AG-SAC) and find that it improves performance in 8 out of 8 tested Atari games (median +31%, max +668%) and 19 out of 20 tested Atari games (median +96%, maximum +3,756%) respectively without substantive hyperparameter tuning. We also show that AG-SAC beats the model-free state-of-the-art for sample efficiency in 17 out of the 20 tested Atari games (median +62%, maximum +13,140%), again without substantive hyperparameter tuning.