 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind Your Manners! A Dataset and A Continual Learning Approach for Assessing Social Appropriateness of Robot Actions
Jul 24, 2020
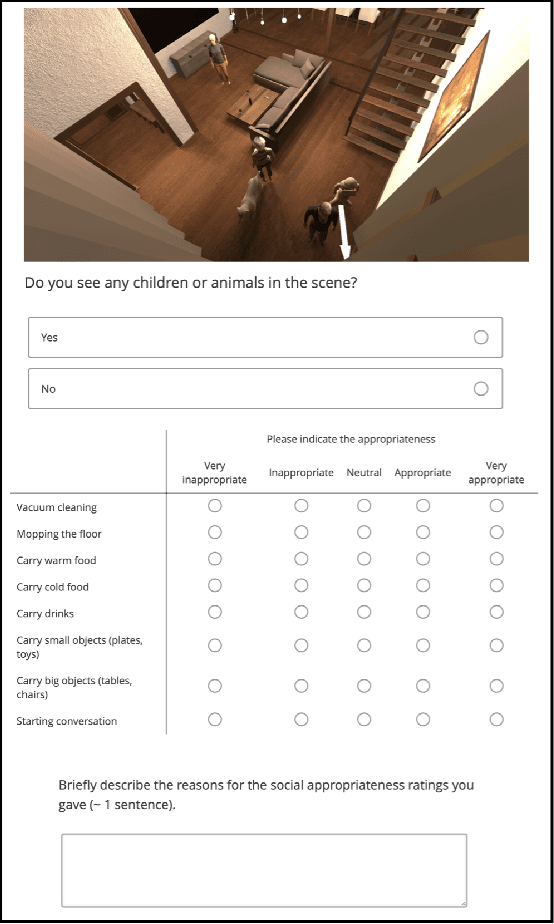
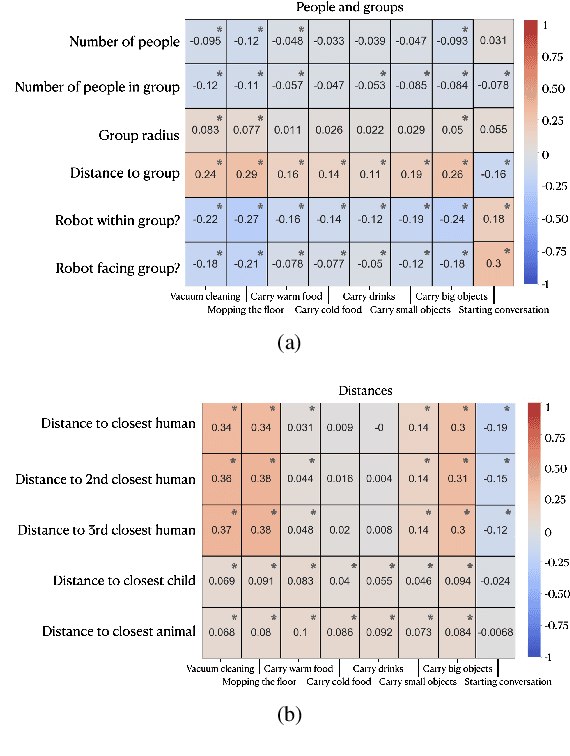
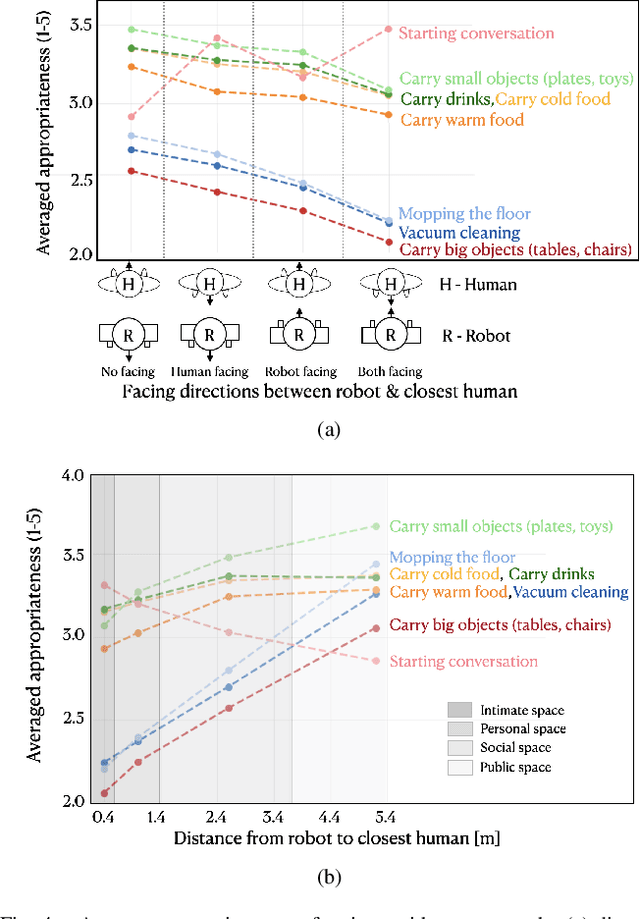
To date, endowing robots with an ability to assess social appropriateness of their actions has not been possible. This has been mainly due to (i) the lack of relevant and labelled data, and (ii) the lack of formulations of this as a lifelong learning problem. In this paper, we address these two issues. We first introduce the Socially Appropriate Domestic Robot Actions dataset (MANNERS-DB), which contains appropriateness labels of robot actions annotated by humans. To be able to control but vary the configurations of the scenes and the social settings, MANNERS-DB has been created utilising a simulation environment by uniformly sampling relevant contextual attributes. Secondly, we train and evaluate a baseline Bayesian Neural Network (BNN) that estimates social appropriateness of actions in the MANNERS-DB. Finally, we formulate learning social appropriateness of actions as a continual learning problem using the uncertainty of the BNN parameters. The experimental results show that the social appropriateness of robot actions can be predicted with a satisfactory level of precision. Our work takes robots one step closer to a human-like understanding of (social) appropriateness of actions, with respect to the social context they operate in. To facilitate reproducibility and further progress in this area, the MANNERS-DB, the trained models and the relevant code will be made publicly available.
Real-World Human-Robot Collaborative Reinforcement Learning
Mar 02, 2020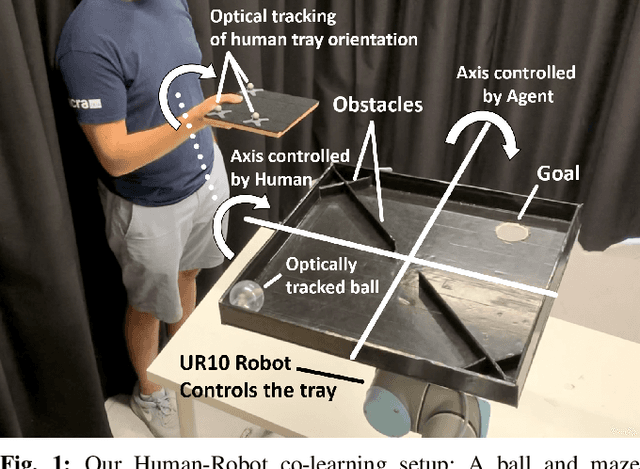
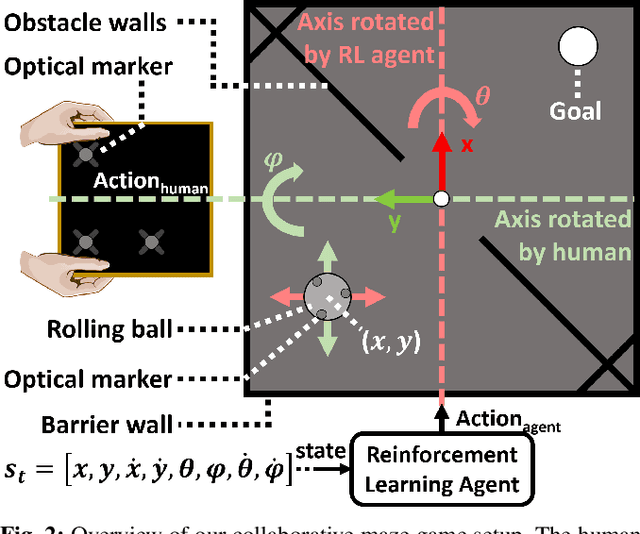
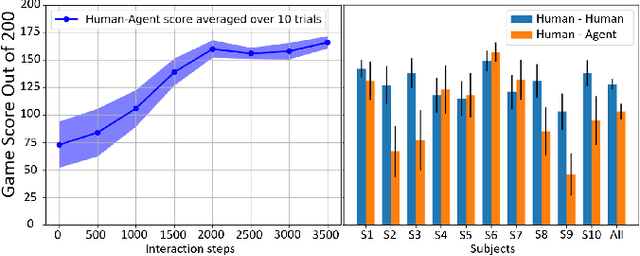
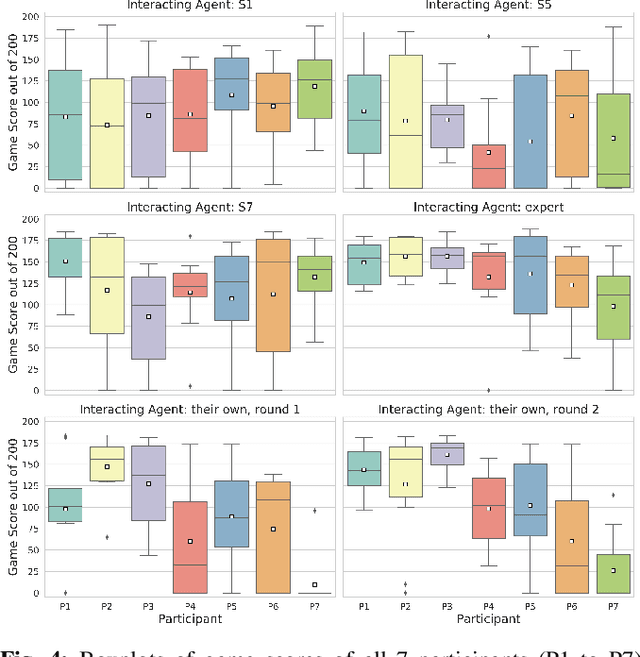
The intuitive collaboration of humans and intelligent robots (embodied AI) in the real-world is an essential objective for many desirable applications of robotics. Whilst there is much research regarding explicit communication, we focus on how humans and robots interact implicitly, on motor adaptation level. We present a real-world setup of a human-robot collaborative maze game, designed to be non-trivial and only solvable through collaboration, by limiting the actions to rotations of two orthogonal axes, and assigning each axes to one player. This results in neither the human nor the agent being able to solve the game on their own. We use a state-of-the-art reinforcement learning algorithm for the robotic agent, and achieve results within 30 minutes of real-world play, without any type of pre-training. We then use this system to perform systematic experiments on human/agent behaviour and adaptation when co-learning a policy for the collaborative game. We present results on how co-policy learning occurs over time between the human and the robotic agent resulting in each participant's agent serving as a representation of how they would play the game. This allows us to relate a person's success when playing with different agents than their own, by comparing the policy of the agent with that of their own agent.
Human-Robot Collaboration via Deep Reinforcement Learning of Real-World Interactions
Dec 02, 2019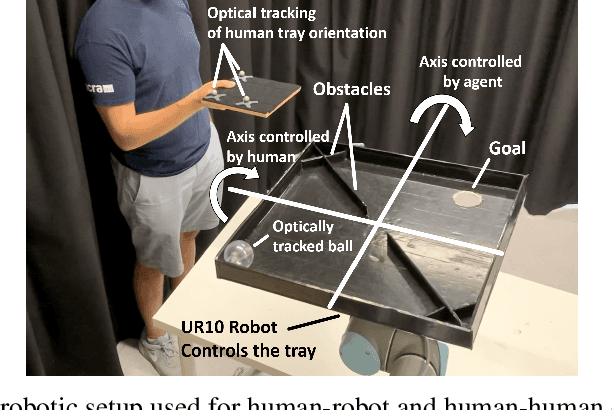
We present a robotic setup for real-world testing and evaluation of human-robot and human-human collaborative learning. Leveraging the sample-efficiency of the Soft Actor-Critic algorithm, we have implemented a robotic platform able to learn a non-trivial collaborative task with a human partner, without pre-training in simulation, and using only 30 minutes of real-world interactions. This enables us to study Human-Robot and Human-Human collaborative learning through real-world interactions. We present preliminary results, showing that state-of-the-art deep learning methods can take human-robot collaborative learning a step closer to that of humans interacting with each other.