 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning with Structured Hierarchical Grammar Representations of Actions
Oct 23, 2019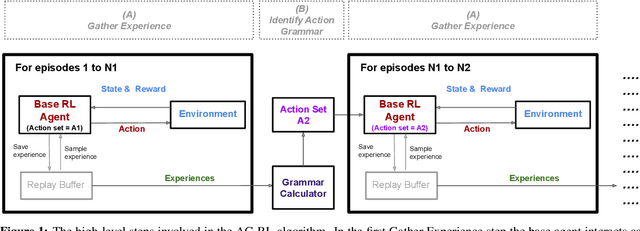
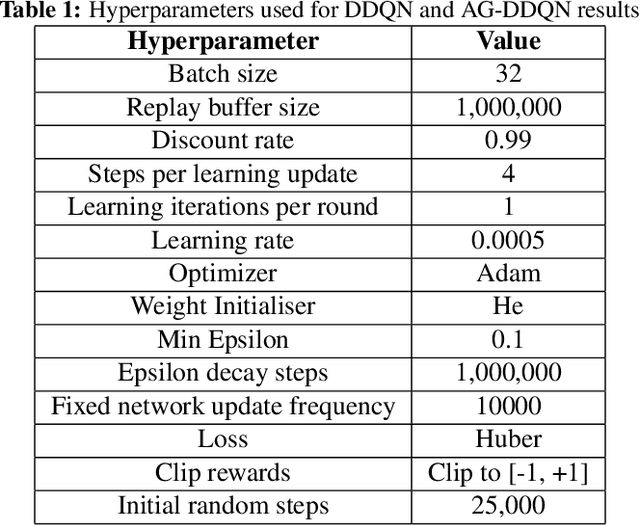

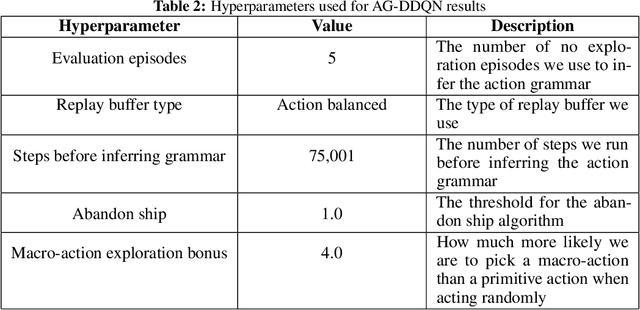
From a young age humans learn to use grammatical principles to hierarchically combine words into sentences. Action grammars is the parallel idea, that there is an underlying set of rules (a "grammar") that govern how we hierarchically combine actions to form new, more complex actions. We introduce the Action Grammar Reinforcement Learning (AG-RL) framework which leverages the concept of action grammars to consistently improve the sample efficiency of Reinforcement Learning agents. AG-RL works by using a grammar inference algorithm to infer the "action grammar" of an agent midway through training. The agent's action space is then augmented with macro-actions identified by the grammar. We apply this framework to Double Deep Q-Learning (AG-DDQN) and a discrete action version of Soft Actor-Critic (AG-SAC) and find that it improves performance in 8 out of 8 tested Atari games (median +31%, max +668%) and 19 out of 20 tested Atari games (median +96%, maximum +3,756%) respectively without substantive hyperparameter tuning. We also show that AG-SAC beats the model-free state-of-the-art for sample efficiency in 17 out of the 20 tested Atari games (median +62%, maximum +13,140%), again without substantive hyperparameter tuning.
Soft Actor-Critic for Discrete Action Settings
Oct 18, 2019


Soft Actor-Critic is a state-of-the-art reinforcement learning algorithm for continuous action settings that is not applicable to discrete action settings. Many important settings involve discrete actions, however, and so here we derive an alternative version of the Soft Actor-Critic algorithm that is applicable to discrete action settings. We then show that, even without any hyperparameter tuning, it is competitive with the tuned model-free state-of-the-art on a selection of games from the Atari suite.