 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIDAS: Deep learning human action intention prediction from natural eye movement patterns
Jan 22, 2022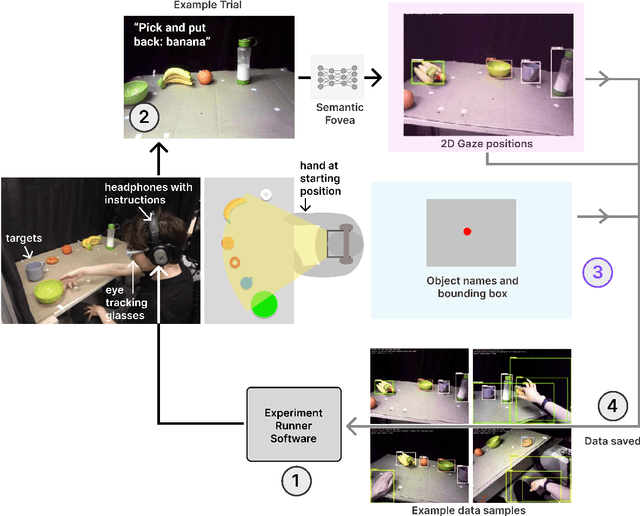
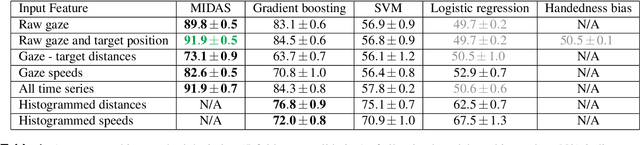
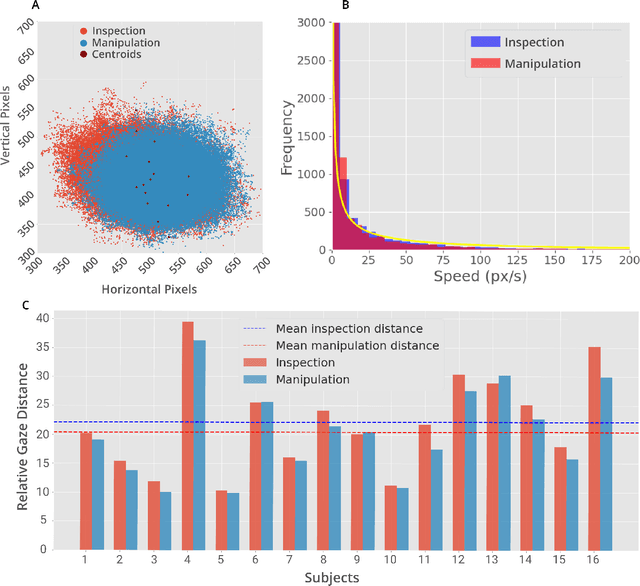
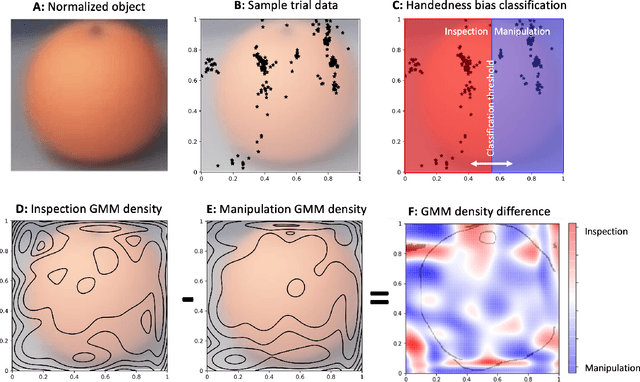
Eye movements have long been studied as a window into the attentional mechanisms of the human brain and made accessible as novelty style human-machine interfaces. However, not everything that we gaze upon, is something we want to interact with; this is known as the Midas Touch problem for gaze interfaces. To overcome the Midas Touch problem, present interfaces tend not to rely on natural gaze cues, but rather use dwell time or gaze gestures. Here we present an entirely data-driven approach to decode human intention for object manipulation tasks based solely on natural gaze cues. We run data collection experiments where 16 participants are given manipulation and inspection tasks to be performed on various objects on a table in front of them. The subjects' eye movements are recorded using wearable eye-trackers allowing the participants to freely move their head and gaze upon the scene. We use our Semantic Fovea, a convolutional neural network model to obtain the objects in the scene and their relation to gaze traces at every frame. We then evaluate the data and examine several ways to model the classification task for intention prediction. Our evaluation shows that intention prediction is not a naive result of the data, but rather relies on non-linear temporal processing of gaze cues. We model the task as a time series classification problem and design a bidirectional Long-Short-Term-Memory (LSTM) network architecture to decode intentions. Our results show that we can decode human intention of motion purely from natural gaze cues and object relative position, with $91.9\%$ accuracy. Our work demonstrates the feasibility of natural gaze as a Zero-UI interface for human-machine interaction, i.e., users will only need to act naturally, and do not need to interact with the interface itself or deviate from their natural eye movement patterns.
Human Visual Attention Prediction Boosts Learning & Performance of Autonomous Driving Agents
Sep 11, 2019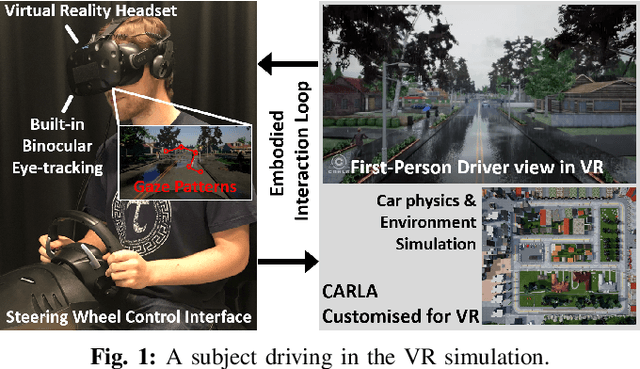


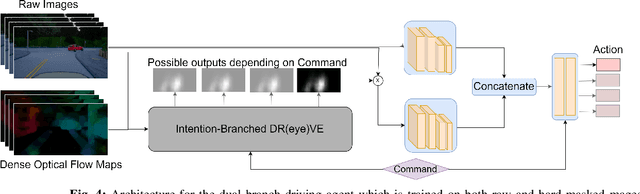
Autonomous driving is a multi-task problem requiring a deep understanding of the visual environment. End-to-end autonomous systems have attracted increasing interest as a method of learning to drive without exhaustively programming behaviours for different driving scenarios. When humans drive, they rely on a finely tuned sensory system which enables them to quickly acquire the information they need while filtering unnecessary details. This ability to identify task-specific high-interest regions within an image could be beneficial to autonomous driving agents and machine learning systems in general. To create a system capable of imitating human gaze patterns and visual attention, we collect eye movement data from human drivers in a virtual reality environment. We use this data to train deep neural networks predicting where humans are most likely to look when driving. We then use the outputs of this trained network to selectively mask driving images using a variety of masking techniques. Finally, autonomous driving agents are trained using these masked images as input. Upon comparison, we found that a dual-branch architecture which processes both raw and attention-masked images substantially outperforms all other models, reducing error in control signal predictions by 25.5\% compared to a standard end-to-end model trained only on raw images.