 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairJob: A Real-World Dataset for Fairness in Online Systems
Jul 03, 2024
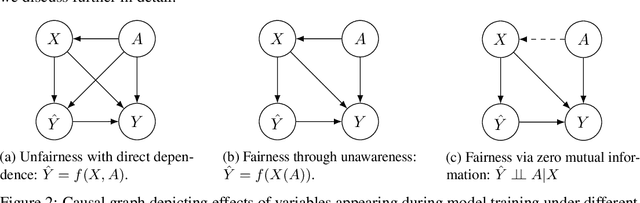
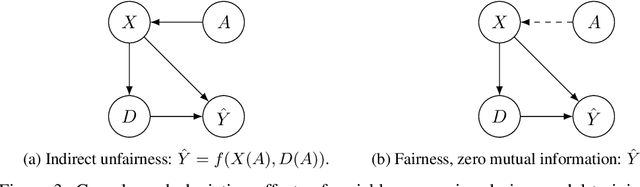
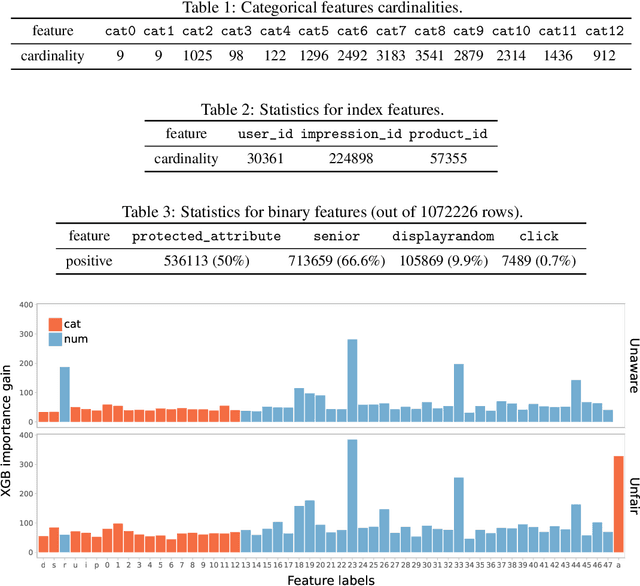
We introduce a fairness-aware dataset for job recommendation in advertising, designed to foster research in algorithmic fairness within real-world scenarios. It was collected and prepared to comply with privacy standards and business confidentiality. An additional challenge is the lack of access to protected user attributes such as gender, for which we propose a solution to obtain a proxy estimate. Despite being anonymized and including a proxy for a sensitive attribute, our dataset preserves predictive power and maintains a realistic and challenging benchmark. This dataset addresses a significant gap in the availability of fairness-focused resources for high-impact domains like advertising -- the actual impact being having access or not to precious employment opportunities, where balancing fairness and utility is a common industrial challenge. We also explore various stages in the advertising process where unfairness can occur and introduce a method to compute a fair utility metric for the job recommendations in online systems case from a biased dataset. Experimental evaluations of bias mitigation techniques on the released dataset demonstrate potential improvements in fairness and the associated trade-offs with utility.
Sequential Counterfactual Risk Minimization
Feb 23, 2023Counterfactual Risk Minimization (CRM) is a framework for dealing with the logged bandit feedback problem, where the goal is to improve a logging policy using offline data. In this paper, we explore the case where it is possible to deploy learned policies multiple times and acquire new data. We extend the CRM principle and its theory to this scenario, which we call "Sequential Counterfactual Risk Minimization (SCRM)." We introduce a novel counterfactual estimator and identify conditions that can improve the performance of CRM in terms of excess risk and regret rates, by using an analysis similar to restart strategies in accelerated optimization methods. We also provide an empirical evaluation of our method in both discrete and continuous action settings, and demonstrate the benefits of multiple deployments of CRM.
Efficient Kernel UCB for Contextual Bandits
Feb 11, 2022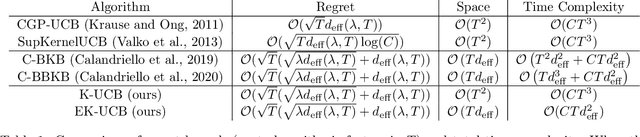
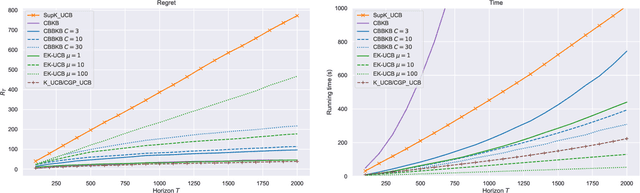
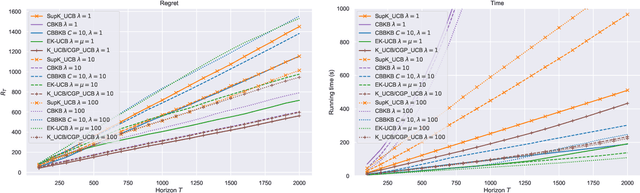
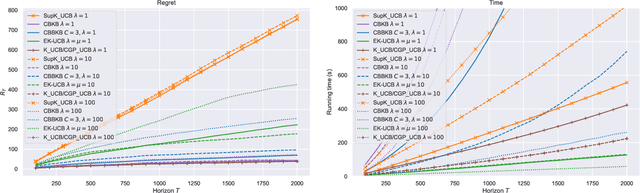
In this paper, we tackle the computational efficiency of kernelized UCB algorithms in contextual bandits. While standard methods require a O(CT^3) complexity where T is the horizon and the constant C is related to optimizing the UCB rule, we propose an efficient contextual algorithm for large-scale problems. Specifically, our method relies on incremental Nystrom approximations of the joint kernel embedding of contexts and actions. This allows us to achieve a complexity of O(CTm^2) where m is the number of Nystrom points. To recover the same regret as the standard kernelized UCB algorithm, m needs to be of order of the effective dimension of the problem, which is at most O(\sqrt(T)) and nearly constant in some cases.
Lessons from the AdKDD'21 Privacy-Preserving ML Challenge
Jan 31, 2022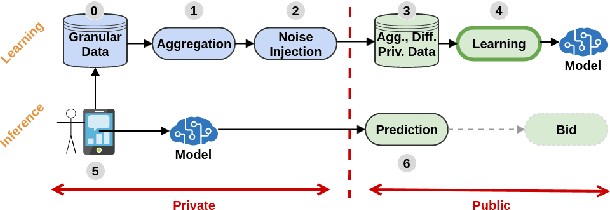
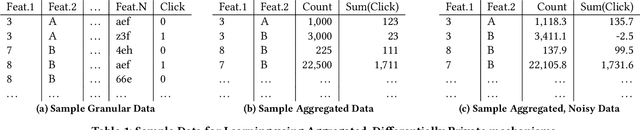
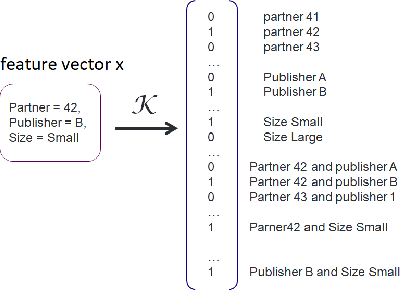
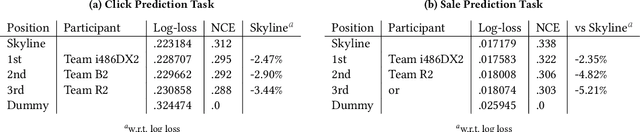
Designing data sharing mechanisms providing performance and strong privacy guarantees is a hot topic for the Online Advertising industry. Namely, a prominent proposal discussed under the Improving Web Advertising Business Group at W3C only allows sharing advertising signals through aggregated, differentially private reports of past displays. To study this proposal extensively, an open Privacy-Preserving Machine Learning Challenge took place at AdKDD'21, a premier workshop on Advertising Science with data provided by advertising company Criteo. In this paper, we describe the challenge tasks, the structure of the available datasets, report the challenge results, and enable its full reproducibility. A key finding is that learning models on large, aggregated data in the presence of a small set of unaggregated data points can be surprisingly efficient and cheap. We also run additional experiments to observe the sensitivity of winning methods to different parameters such as privacy budget or quantity of available privileged side information. We conclude that the industry needs either alternate designs for private data sharing or a breakthrough in learning with aggregated data only to keep ad relevance at a reasonable level.
A Large Scale Benchmark for Individual Treatment Effect Prediction and Uplift Modeling
Nov 19, 2021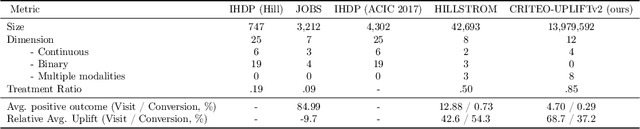
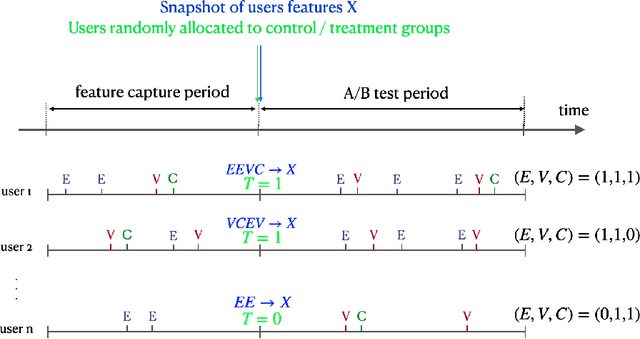
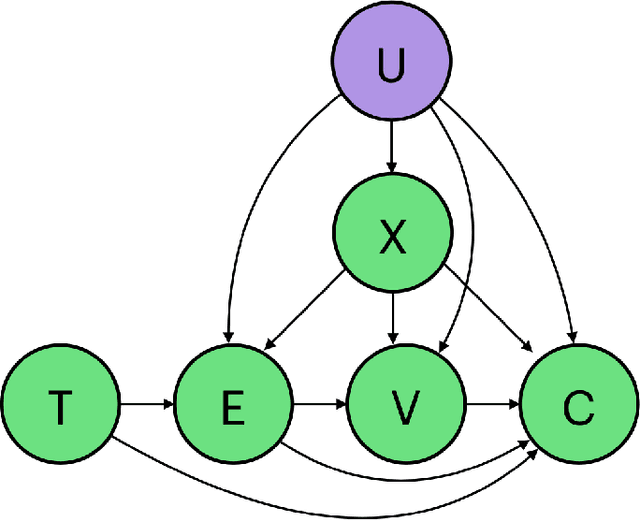

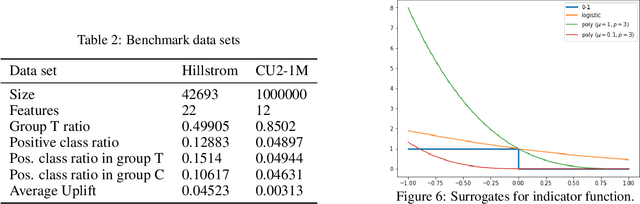
Individual Treatment Effect (ITE) prediction is an important area of research in machine learning which aims at explaining and estimating the causal impact of an action at the granular level. It represents a problem of growing interest in multiple sectors of application such as healthcare, online advertising or socioeconomics. To foster research on this topic we release a publicly available collection of 13.9 million samples collected from several randomized control trials, scaling up previously available datasets by a healthy 210x factor. We provide details on the data collection and perform sanity checks to validate the use of this data for causal inference tasks. First, we formalize the task of uplift modeling (UM) that can be performed with this data, along with the relevant evaluation metrics. Then, we propose synthetic response surfaces and heterogeneous treatment assignment providing a general set-up for ITE prediction. Finally, we report experiments to validate key characteristics of the dataset leveraging its size to evaluate and compare - with high statistical significance - a selection of baseline UM and ITE prediction methods.
Treatment Targeting by AUUC Maximization with Generalization Guarantees
Dec 17, 2020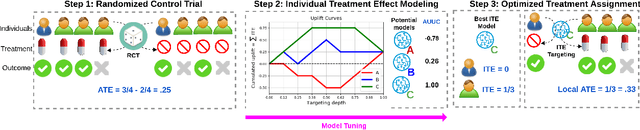
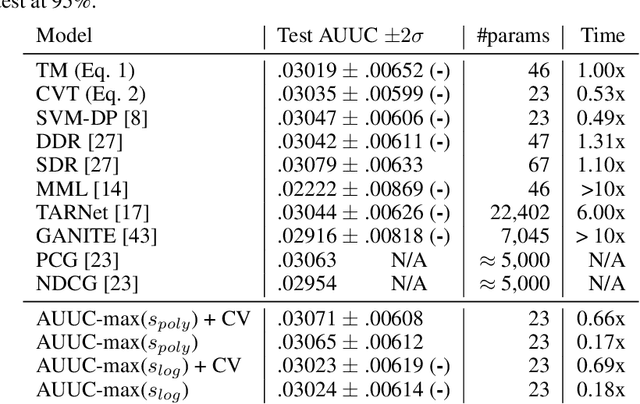
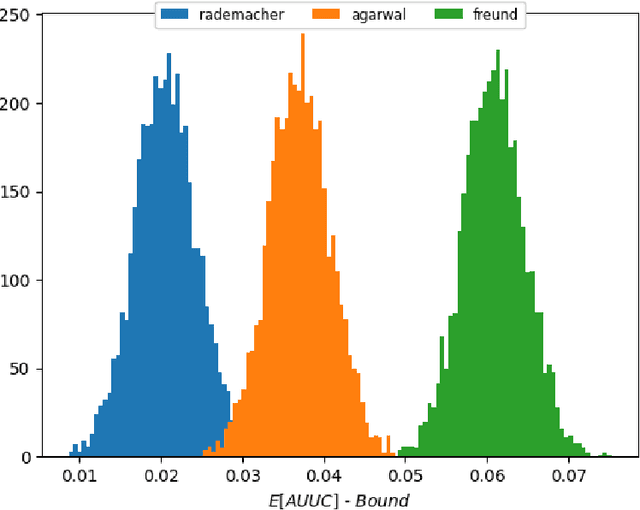
We consider the task of optimizing treatment assignment based on individual treatment effect prediction. This task is found in many applications such as personalized medicine or targeted advertising and has gained a surge of interest in recent years under the name of Uplift Modeling. It consists in targeting treatment to the individuals for whom it would be the most beneficial. In real life scenarios, when we do not have access to ground-truth individual treatment effect, the capacity of models to do so is generally measured by the Area Under the Uplift Curve (AUUC), a metric that differs from the learning objectives of most of the Individual Treatment Effect (ITE) models. We argue that the learning of these models could inadvertently degrade AUUC and lead to suboptimal treatment assignment. To tackle this issue, we propose a generalization bound on the AUUC and present a novel learning algorithm that optimizes a derivable surrogate of this bound, called AUUC-max. Finally, we empirically demonstrate the tightness of this generalization bound, its effectiveness for hyper-parameter tuning and show the efficiency of the proposed algorithm compared to a wide range of competitive baselines on two classical benchmarks.
Individual Treatment Effect Estimation in a Low Compliance Setting
Aug 07, 2020
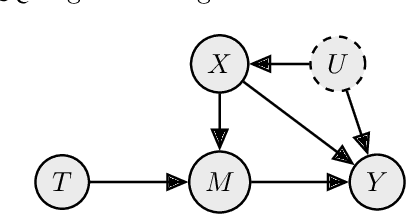
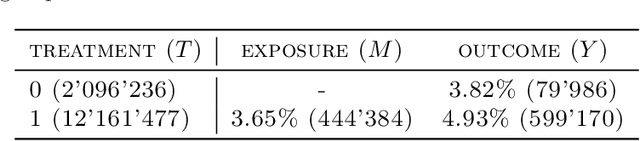
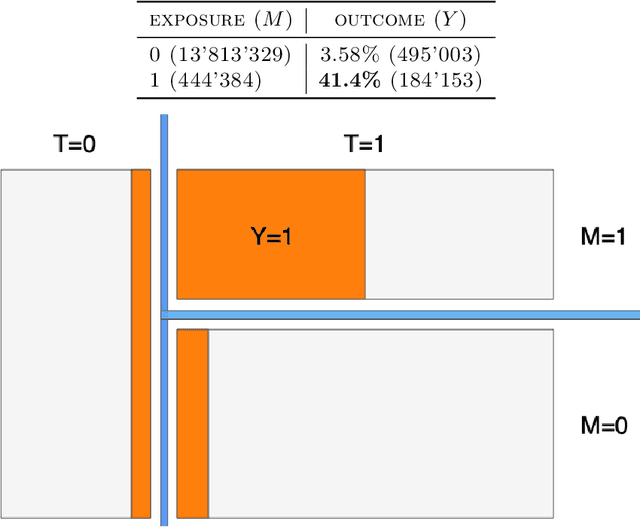
Individual Treatment Effect (ITE) estimation is an extensively researched problem, with applications in various domains. We model the case where there is heterogeneous non-compliance to a randomly assigned treatment, a typical situation in health (because of non-compliance to prescription) or digital advertising (because of competition and ad blockers for instance). The lower the compliance, the more the effect of treatment prescription, or individual prescription effect (IPE), signal fades away and becomes hard to capture. We propose a new approach to estimate IPE that takes advantage of observed compliance information to prevent signal fading. Using the Structural Causal Model framework and do-calculus, we define a general mediated causal effect setting under which our proposed estimator soundly recovers the IPE, and study its asymptotic variance. Finally, we conduct extensive experiments on both synthetic and real-world datasets that highlight the benefit of the approach, which consistently improves state-of-the-art in low compliance settings.
Optimization Approaches for Counterfactual Risk Minimization with Continuous Actions
Apr 22, 2020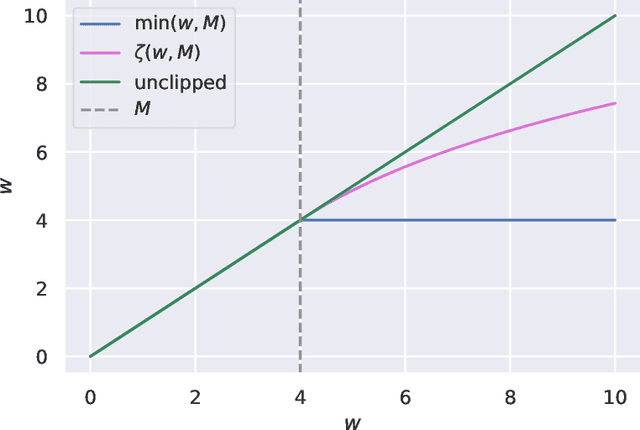

Counterfactual reasoning from logged data has become increasingly important for a large range of applications such as web advertising or healthcare. In this paper, we address the problem of counterfactual risk minimization for learning a stochastic policy with a continuous action space. Whereas previous works have mostly focused on deriving statistical estimators with importance sampling, we show that the optimization perspective is equally important for solving the resulting nonconvex optimization problems.Specifically, we demonstrate the benefits of proximal point algorithms and soft-clipping estimators which are more amenable to gradient-based optimization than classical hard clipping. We propose multiple synthetic, yet realistic, evaluation setups, and we release a new large-scale dataset based on web advertising data for this problem that is crucially missing public benchmarks.
Attribution Modeling Increases Efficiency of Bidding in Display Advertising
Jul 21, 2017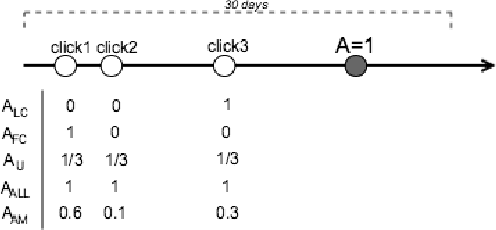
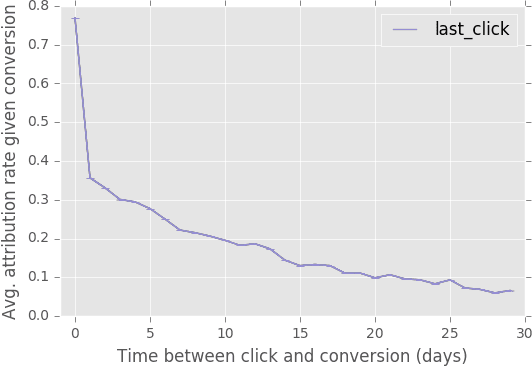
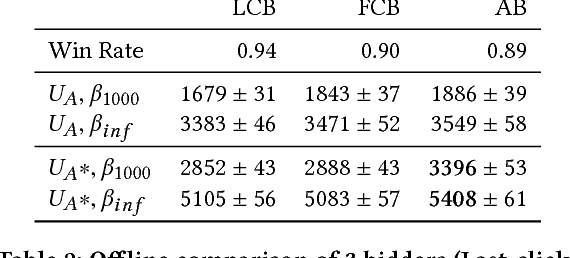
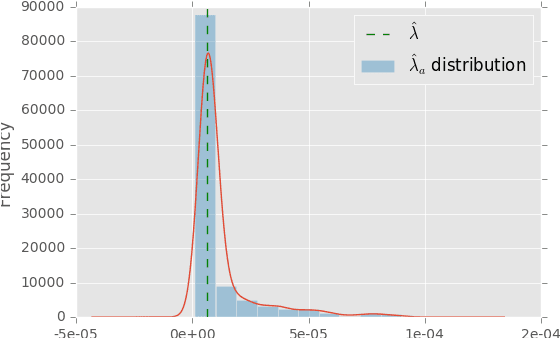
Predicting click and conversion probabilities when bidding on ad exchanges is at the core of the programmatic advertising industry. Two separated lines of previous works respectively address i) the prediction of user conversion probability and ii) the attribution of these conversions to advertising events (such as clicks) after the fact. We argue that attribution modeling improves the efficiency of the bidding policy in the context of performance advertising. Firstly we explain the inefficiency of the standard bidding policy with respect to attribution. Secondly we learn and utilize an attribution model in the bidder itself and show how it modifies the average bid after a click. Finally we produce evidence of the effectiveness of the proposed method on both offline and online experiments with data spanning several weeks of real traffic from Criteo, a leader in performance advertising.