 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbacus: Self-Supervised Event Counting-Aligned Distributional Pretraining for Sequential User Modeling
Dec 18, 2025



Modeling user purchase behavior is a critical challenge in display advertising systems, necessary for real-time bidding. The difficulty arises from the sparsity of positive user events and the stochasticity of user actions, leading to severe class imbalance and irregular event timing. Predictive systems usually rely on hand-crafted "counter" features, overlooking the fine-grained temporal evolution of user intent. Meanwhile, current sequential models extract direct sequential signal, missing useful event-counting statistics. We enhance deep sequential models with self-supervised pretraining strategies for display advertising. Especially, we introduce Abacus, a novel approach of predicting the empirical frequency distribution of user events. We further propose a hybrid objective unifying Abacus with sequential learning objectives, combining stability of aggregated statistics with the sequence modeling sensitivity. Experiments on two real-world datasets show that Abacus pretraining outperforms existing methods accelerating downstream task convergence, while hybrid approach yields up to +6.1% AUC compared to the baselines.
Maximizing the Success Probability of Policy Allocations in Online Systems
Dec 26, 2023



The effectiveness of advertising in e-commerce largely depends on the ability of merchants to bid on and win impressions for their targeted users. The bidding procedure is highly complex due to various factors such as market competition, user behavior, and the diverse objectives of advertisers. In this paper we consider the problem at the level of user timelines instead of individual bid requests, manipulating full policies (i.e. pre-defined bidding strategies) and not bid values. In order to optimally allocate policies to users, typical multiple treatments allocation methods solve knapsack-like problems which aim at maximizing an expected value under constraints. In the industrial contexts such as online advertising, we argue that optimizing for the probability of success is a more suited objective than expected value maximization, and we introduce the SuccessProbaMax algorithm that aims at finding the policy allocation which is the most likely to outperform a fixed reference policy. Finally, we conduct comprehensive experiments both on synthetic and real-world data to evaluate its performance. The results demonstrate that our proposed algorithm outperforms conventional expected-value maximization algorithms in terms of success rate.
A Large Scale Benchmark for Individual Treatment Effect Prediction and Uplift Modeling
Nov 19, 2021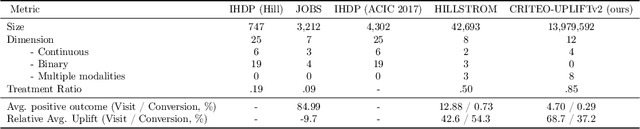
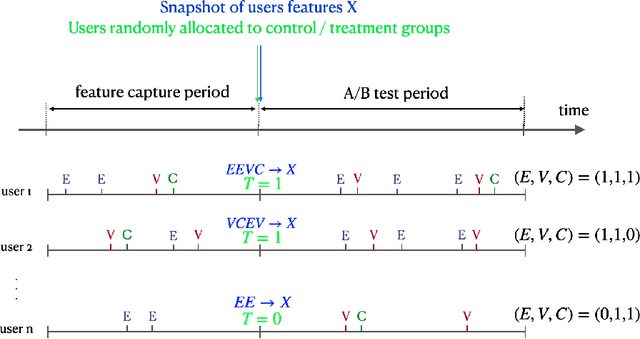
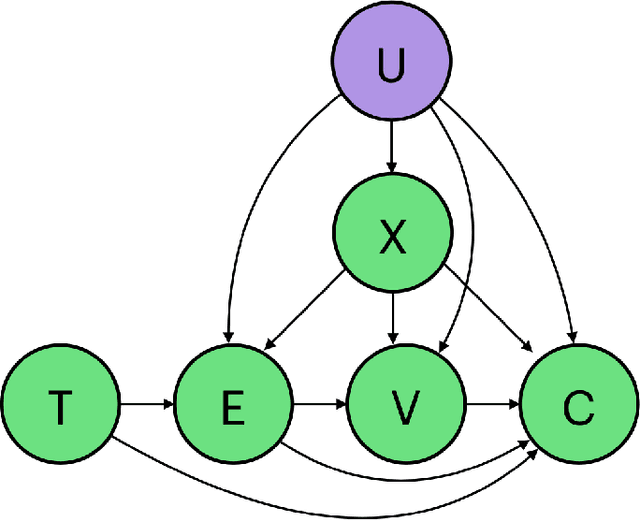

Individual Treatment Effect (ITE) prediction is an important area of research in machine learning which aims at explaining and estimating the causal impact of an action at the granular level. It represents a problem of growing interest in multiple sectors of application such as healthcare, online advertising or socioeconomics. To foster research on this topic we release a publicly available collection of 13.9 million samples collected from several randomized control trials, scaling up previously available datasets by a healthy 210x factor. We provide details on the data collection and perform sanity checks to validate the use of this data for causal inference tasks. First, we formalize the task of uplift modeling (UM) that can be performed with this data, along with the relevant evaluation metrics. Then, we propose synthetic response surfaces and heterogeneous treatment assignment providing a general set-up for ITE prediction. Finally, we report experiments to validate key characteristics of the dataset leveraging its size to evaluate and compare - with high statistical significance - a selection of baseline UM and ITE prediction methods.
Treatment Targeting by AUUC Maximization with Generalization Guarantees
Dec 17, 2020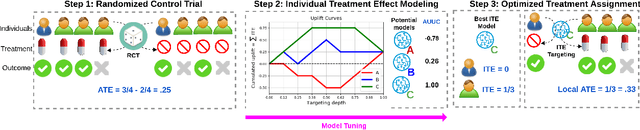
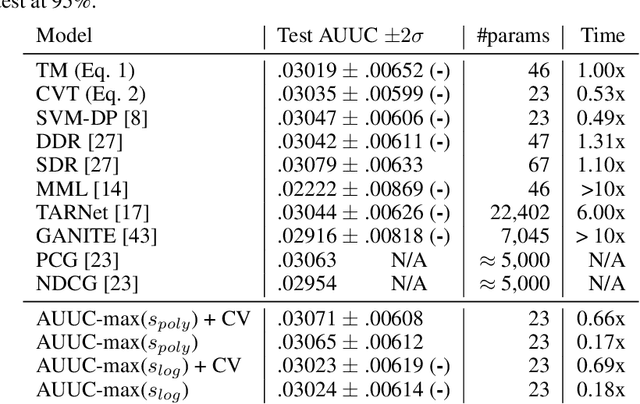
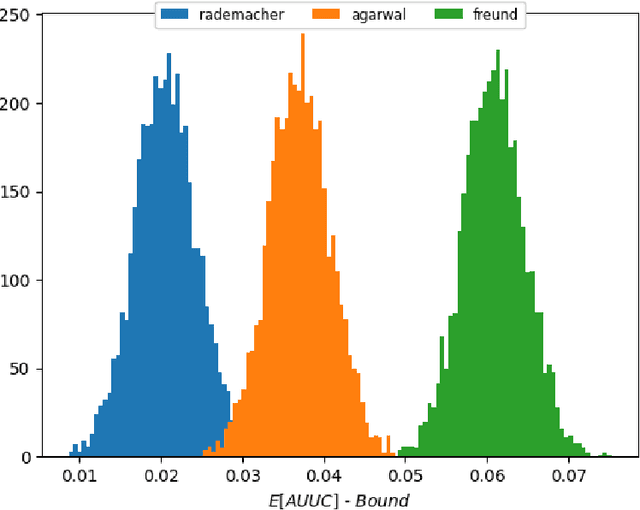
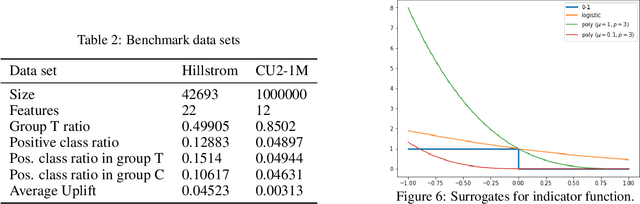
We consider the task of optimizing treatment assignment based on individual treatment effect prediction. This task is found in many applications such as personalized medicine or targeted advertising and has gained a surge of interest in recent years under the name of Uplift Modeling. It consists in targeting treatment to the individuals for whom it would be the most beneficial. In real life scenarios, when we do not have access to ground-truth individual treatment effect, the capacity of models to do so is generally measured by the Area Under the Uplift Curve (AUUC), a metric that differs from the learning objectives of most of the Individual Treatment Effect (ITE) models. We argue that the learning of these models could inadvertently degrade AUUC and lead to suboptimal treatment assignment. To tackle this issue, we propose a generalization bound on the AUUC and present a novel learning algorithm that optimizes a derivable surrogate of this bound, called AUUC-max. Finally, we empirically demonstrate the tightness of this generalization bound, its effectiveness for hyper-parameter tuning and show the efficiency of the proposed algorithm compared to a wide range of competitive baselines on two classical benchmarks.