 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFunctional Natural Policy Gradients
Mar 30, 2026We propose a cross-fitted debiasing device for policy learning from offline data. A key consequence of the resulting learning principle is $\sqrt N$ regret even for policy classes with complexity greater than Donsker, provided a product-of-errors nuisance remainder is $O(N^{-1/2})$. The regret bound factors into a plug-in policy error factor governed by policy-class complexity and an environment nuisance factor governed by the complexity of the environment dynamics, making explicit how one may be traded against the other.
Logarithmic Regret for Unconstrained Submodular Maximization Stochastic Bandit
Oct 11, 2024We address the online unconstrained submodular maximization problem (Online USM), in a setting with stochastic bandit feedback. In this framework, a decision-maker receives noisy rewards from a nonmonotone submodular function, taking values in a known bounded interval. This paper proposes Double-Greedy - Explore-then-Commit (DG-ETC), adapting the Double-Greedy approach from the offline and online full-information settings. DG-ETC satisfies a O(d log(dT)) problemdependent upper bound for the 1/2-approximate pseudo-regret, as well as a O(dT^{2/3}log(dT)^{1/3}) problem-free one at the same time, outperforming existing approaches. To that end, we introduce a notion of hardness for submodular functions, characterizing how difficult it is to maximize them with this type of strategy.
Covariance-Adaptive Least-Squares Algorithm for Stochastic Combinatorial Semi-Bandits
Feb 23, 2024



We address the problem of stochastic combinatorial semi-bandits, where a player can select from P subsets of a set containing d base items. Most existing algorithms (e.g. CUCB, ESCB, OLS-UCB) require prior knowledge on the reward distribution, like an upper bound on a sub-Gaussian proxy-variance, which is hard to estimate tightly. In this work, we design a variance-adaptive version of OLS-UCB, relying on an online estimation of the covariance structure. Estimating the coefficients of a covariance matrix is much more manageable in practical settings and results in improved regret upper bounds compared to proxy variance-based algorithms. When covariance coefficients are all non-negative, we show that our approach efficiently leverages the semi-bandit feedback and provably outperforms bandit feedback approaches, not only in exponential regimes where P $\gg$ d but also when P $\le$ d, which is not straightforward from most existing analyses.
Maximizing the Success Probability of Policy Allocations in Online Systems
Dec 26, 2023



The effectiveness of advertising in e-commerce largely depends on the ability of merchants to bid on and win impressions for their targeted users. The bidding procedure is highly complex due to various factors such as market competition, user behavior, and the diverse objectives of advertisers. In this paper we consider the problem at the level of user timelines instead of individual bid requests, manipulating full policies (i.e. pre-defined bidding strategies) and not bid values. In order to optimally allocate policies to users, typical multiple treatments allocation methods solve knapsack-like problems which aim at maximizing an expected value under constraints. In the industrial contexts such as online advertising, we argue that optimizing for the probability of success is a more suited objective than expected value maximization, and we introduce the SuccessProbaMax algorithm that aims at finding the policy allocation which is the most likely to outperform a fixed reference policy. Finally, we conduct comprehensive experiments both on synthetic and real-world data to evaluate its performance. The results demonstrate that our proposed algorithm outperforms conventional expected-value maximization algorithms in terms of success rate.
Nested bandits
Jun 19, 2022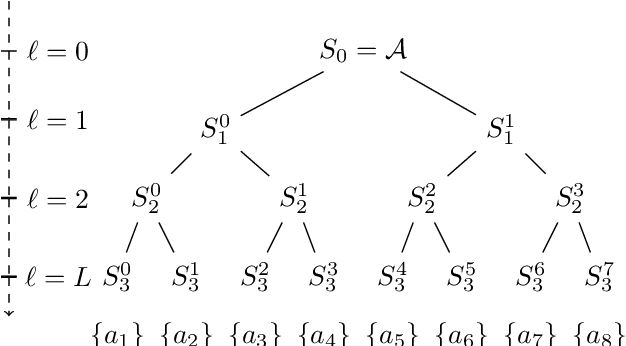
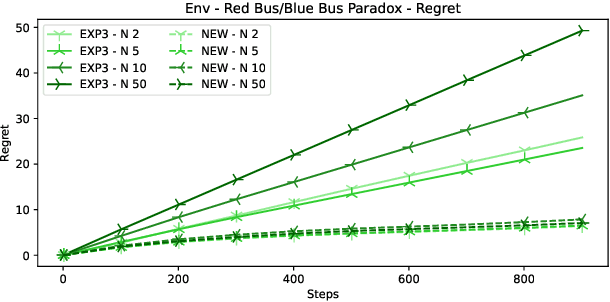
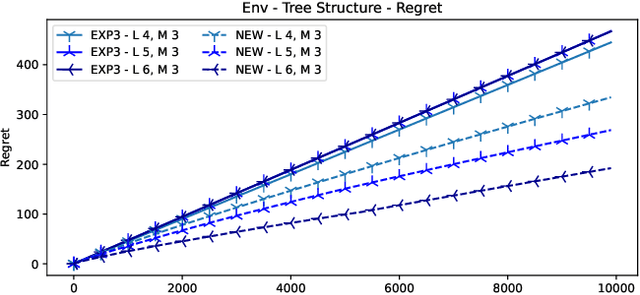
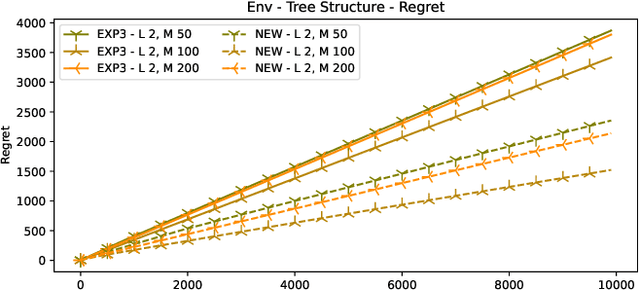
In many online decision processes, the optimizing agent is called to choose between large numbers of alternatives with many inherent similarities; in turn, these similarities imply closely correlated losses that may confound standard discrete choice models and bandit algorithms. We study this question in the context of nested bandits, a class of adversarial multi-armed bandit problems where the learner seeks to minimize their regret in the presence of a large number of distinct alternatives with a hierarchy of embedded (non-combinatorial) similarities. In this setting, optimal algorithms based on the exponential weights blueprint (like Hedge, EXP3, and their variants) may incur significant regret because they tend to spend excessive amounts of time exploring irrelevant alternatives with similar, suboptimal costs. To account for this, we propose a nested exponential weights (NEW) algorithm that performs a layered exploration of the learner's set of alternatives based on a nested, step-by-step selection method. In so doing, we obtain a series of tight bounds for the learner's regret showing that online learning problems with a high degree of similarity between alternatives can be resolved efficiently, without a red bus / blue bus paradox occurring.
Diverse Weight Averaging for Out-of-Distribution Generalization
May 19, 2022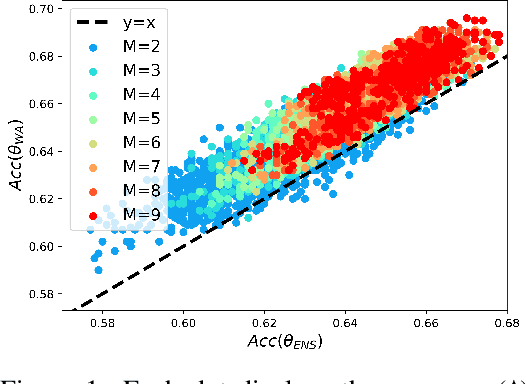



Standard neural networks struggle to generalize under distribution shifts. For out-of-distribution generalization in computer vision, the best current approach averages the weights along a training run. In this paper, we propose Diverse Weight Averaging (DiWA) that makes a simple change to this strategy: DiWA averages the weights obtained from several independent training runs rather than from a single run. Perhaps surprisingly, averaging these weights performs well under soft constraints despite the network's nonlinearities. The main motivation behind DiWA is to increase the functional diversity across averaged models. Indeed, models obtained from different runs are more diverse than those collected along a single run thanks to differences in hyperparameters and training procedures. We motivate the need for diversity by a new bias-variance-covariance-locality decomposition of the expected error, exploiting similarities between DiWA and standard functional ensembling. Moreover, this decomposition highlights that DiWA succeeds when the variance term dominates, which we show happens when the marginal distribution changes at test time. Experimentally, DiWA consistently improves the state of the art on the competitive DomainBed benchmark without inference overhead.
A Large Scale Benchmark for Individual Treatment Effect Prediction and Uplift Modeling
Nov 19, 2021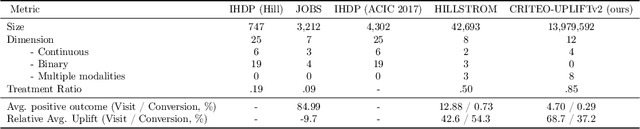
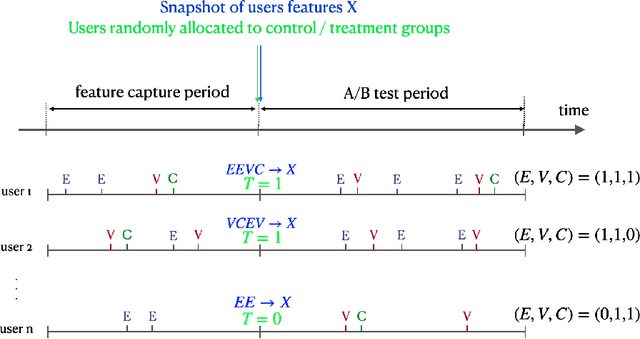
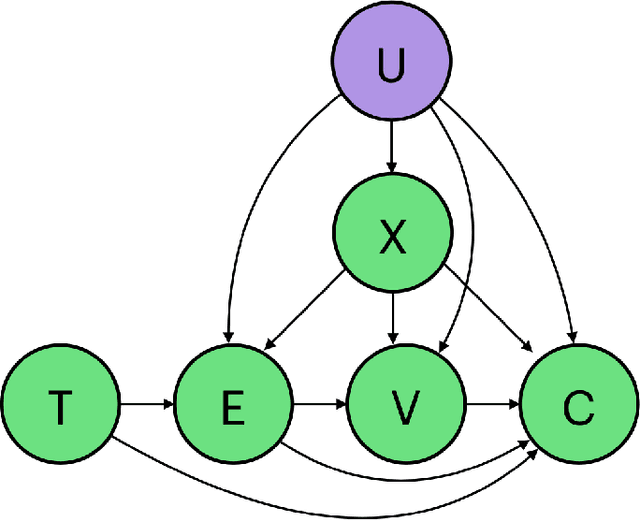

Individual Treatment Effect (ITE) prediction is an important area of research in machine learning which aims at explaining and estimating the causal impact of an action at the granular level. It represents a problem of growing interest in multiple sectors of application such as healthcare, online advertising or socioeconomics. To foster research on this topic we release a publicly available collection of 13.9 million samples collected from several randomized control trials, scaling up previously available datasets by a healthy 210x factor. We provide details on the data collection and perform sanity checks to validate the use of this data for causal inference tasks. First, we formalize the task of uplift modeling (UM) that can be performed with this data, along with the relevant evaluation metrics. Then, we propose synthetic response surfaces and heterogeneous treatment assignment providing a general set-up for ITE prediction. Finally, we report experiments to validate key characteristics of the dataset leveraging its size to evaluate and compare - with high statistical significance - a selection of baseline UM and ITE prediction methods.
Zeroth-order non-convex learning via hierarchical dual averaging
Sep 13, 2021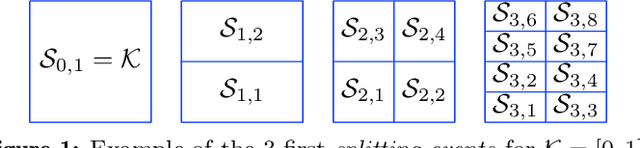
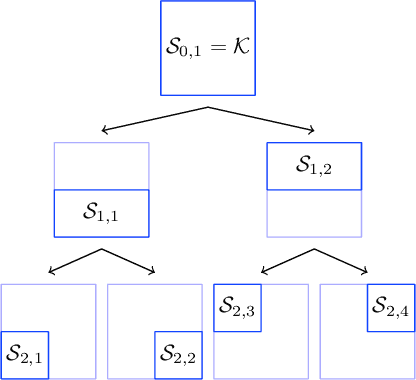
We propose a hierarchical version of dual averaging for zeroth-order online non-convex optimization - i.e., learning processes where, at each stage, the optimizer is facing an unknown non-convex loss function and only receives the incurred loss as feedback. The proposed class of policies relies on the construction of an online model that aggregates loss information as it arrives, and it consists of two principal components: (a) a regularizer adapted to the Fisher information metric (as opposed to the metric norm of the ambient space); and (b) a principled exploration of the problem's state space based on an adapted hierarchical schedule. This construction enables sharper control of the model's bias and variance, and allows us to derive tight bounds for both the learner's static and dynamic regret - i.e., the regret incurred against the best dynamic policy in hindsight over the horizon of play.
Online non-convex optimization with imperfect feedback
Oct 16, 2020
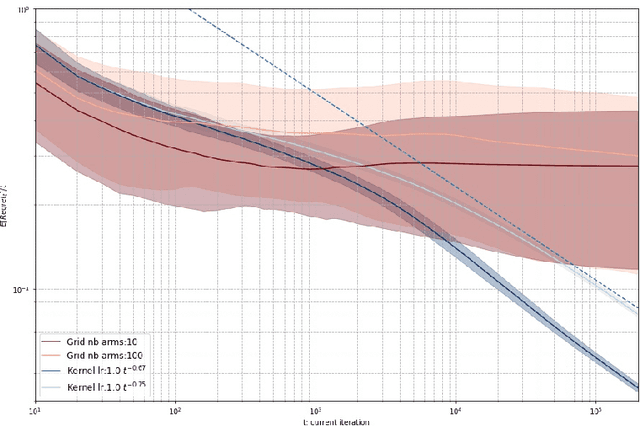
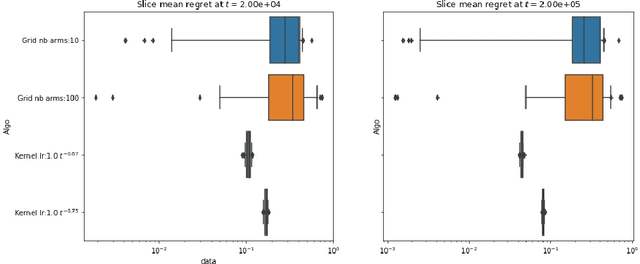
We consider the problem of online learning with non-convex losses. In terms of feedback, we assume that the learner observes - or otherwise constructs - an inexact model for the loss function encountered at each stage, and we propose a mixed-strategy learning policy based on dual averaging. In this general context, we derive a series of tight regret minimization guarantees, both for the learner's static (external) regret, as well as the regret incurred against the best dynamic policy in hindsight. Subsequently, we apply this general template to the case where the learner only has access to the actual loss incurred at each stage of the process. This is achieved by means of a kernel-based estimator which generates an inexact model for each round's loss function using only the learner's realized losses as input.
Individual Treatment Effect Estimation in a Low Compliance Setting
Aug 07, 2020
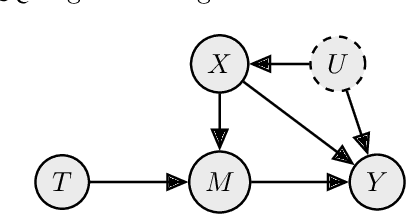
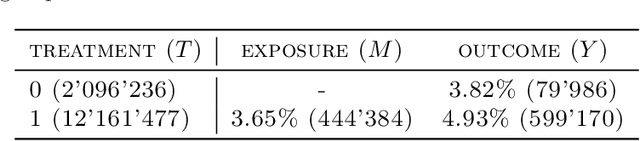
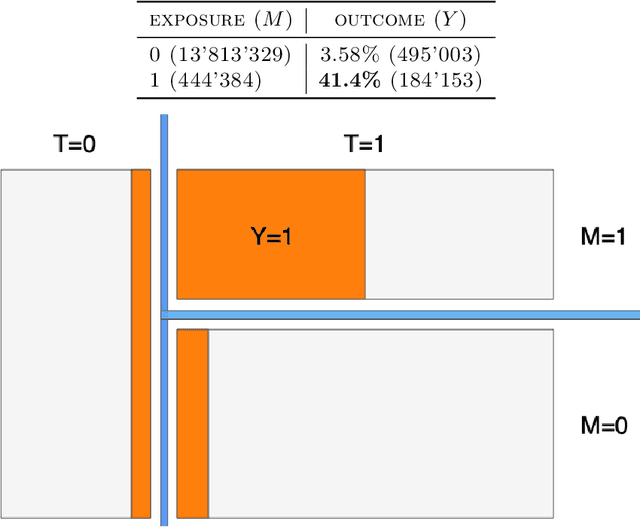
Individual Treatment Effect (ITE) estimation is an extensively researched problem, with applications in various domains. We model the case where there is heterogeneous non-compliance to a randomly assigned treatment, a typical situation in health (because of non-compliance to prescription) or digital advertising (because of competition and ad blockers for instance). The lower the compliance, the more the effect of treatment prescription, or individual prescription effect (IPE), signal fades away and becomes hard to capture. We propose a new approach to estimate IPE that takes advantage of observed compliance information to prevent signal fading. Using the Structural Causal Model framework and do-calculus, we define a general mediated causal effect setting under which our proposed estimator soundly recovers the IPE, and study its asymptotic variance. Finally, we conduct extensive experiments on both synthetic and real-world datasets that highlight the benefit of the approach, which consistently improves state-of-the-art in low compliance settings.