 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large Scale Benchmark for Individual Treatment Effect Prediction and Uplift Modeling
Paper and Code
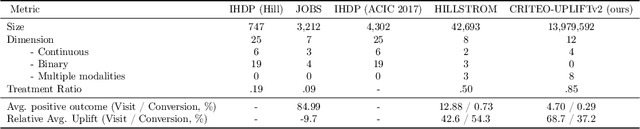
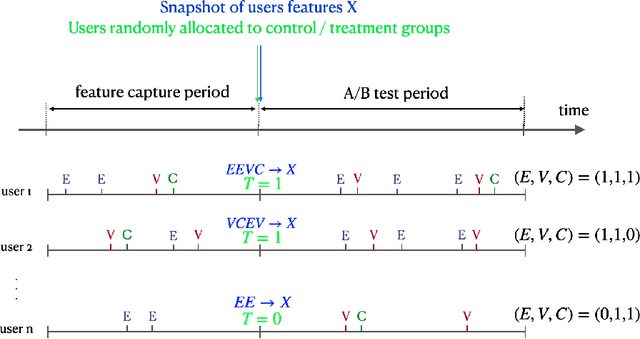
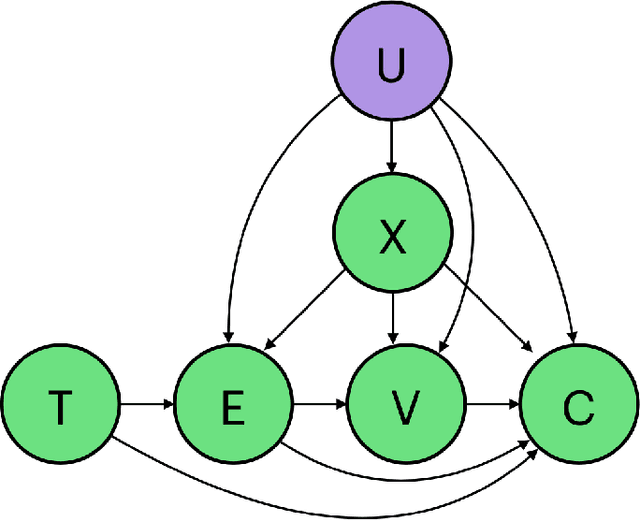

Individual Treatment Effect (ITE) prediction is an important area of research in machine learning which aims at explaining and estimating the causal impact of an action at the granular level. It represents a problem of growing interest in multiple sectors of application such as healthcare, online advertising or socioeconomics. To foster research on this topic we release a publicly available collection of 13.9 million samples collected from several randomized control trials, scaling up previously available datasets by a healthy 210x factor. We provide details on the data collection and perform sanity checks to validate the use of this data for causal inference tasks. First, we formalize the task of uplift modeling (UM) that can be performed with this data, along with the relevant evaluation metrics. Then, we propose synthetic response surfaces and heterogeneous treatment assignment providing a general set-up for ITE prediction. Finally, we report experiments to validate key characteristics of the dataset leveraging its size to evaluate and compare - with high statistical significance - a selection of baseline UM and ITE prediction methods.