 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxtral
Jul 17, 2025We present Voxtral Mini and Voxtral Small, two multimodal audio chat models. Voxtral is trained to comprehend both spoken audio and text documents, achieving state-of-the-art performance across a diverse range of audio benchmarks, while preserving strong text capabilities. Voxtral Small outperforms a number of closed-source models, while being small enough to run locally. A 32K context window enables the model to handle audio files up to 40 minutes in duration and long multi-turn conversations. We also contribute three benchmarks for evaluating speech understanding models on knowledge and trivia. Both Voxtral models are released under Apache 2.0 license.
Magistral
Jun 12, 2025



We introduce Magistral, Mistral's first reasoning model and our own scalable reinforcement learning (RL) pipeline. Instead of relying on existing implementations and RL traces distilled from prior models, we follow a ground up approach, relying solely on our own models and infrastructure. Notably, we demonstrate a stack that enabled us to explore the limits of pure RL training of LLMs, present a simple method to force the reasoning language of the model, and show that RL on text data alone maintains most of the initial checkpoint's capabilities. We find that RL on text maintains or improves multimodal understanding, instruction following and function calling. We present Magistral Medium, trained for reasoning on top of Mistral Medium 3 with RL alone, and we open-source Magistral Small (Apache 2.0) which further includes cold-start data from Magistral Medium.
A Large Scale Benchmark for Individual Treatment Effect Prediction and Uplift Modeling
Nov 19, 2021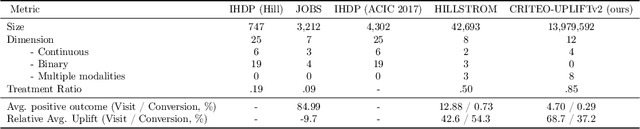
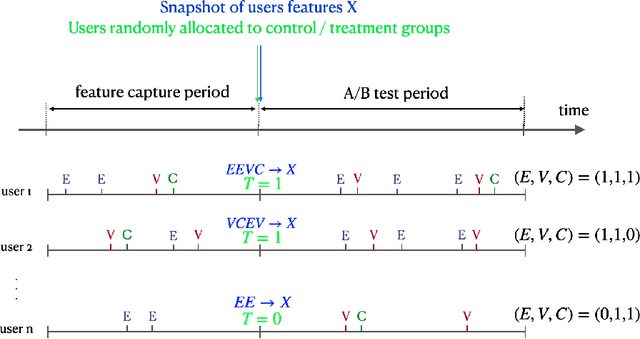
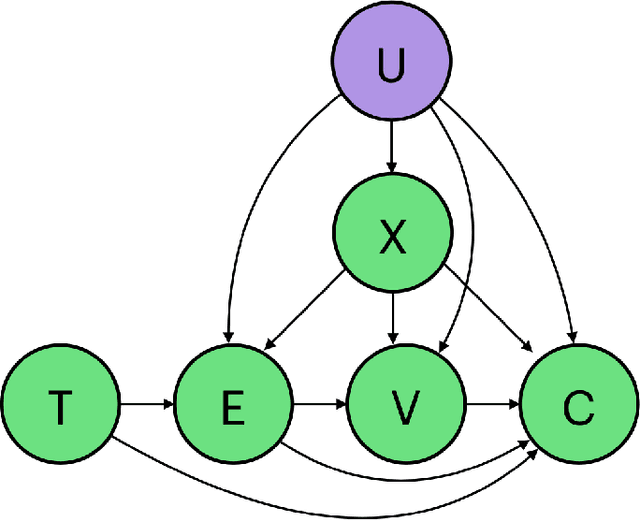

Individual Treatment Effect (ITE) prediction is an important area of research in machine learning which aims at explaining and estimating the causal impact of an action at the granular level. It represents a problem of growing interest in multiple sectors of application such as healthcare, online advertising or socioeconomics. To foster research on this topic we release a publicly available collection of 13.9 million samples collected from several randomized control trials, scaling up previously available datasets by a healthy 210x factor. We provide details on the data collection and perform sanity checks to validate the use of this data for causal inference tasks. First, we formalize the task of uplift modeling (UM) that can be performed with this data, along with the relevant evaluation metrics. Then, we propose synthetic response surfaces and heterogeneous treatment assignment providing a general set-up for ITE prediction. Finally, we report experiments to validate key characteristics of the dataset leveraging its size to evaluate and compare - with high statistical significance - a selection of baseline UM and ITE prediction methods.
Individual Treatment Effect Estimation in a Low Compliance Setting
Aug 07, 2020
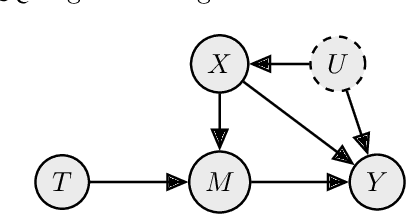
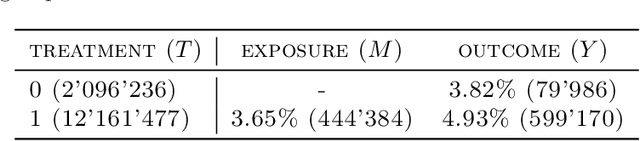
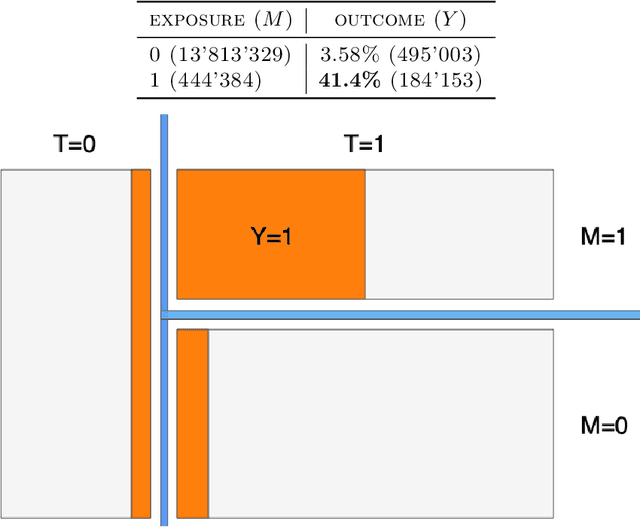
Individual Treatment Effect (ITE) estimation is an extensively researched problem, with applications in various domains. We model the case where there is heterogeneous non-compliance to a randomly assigned treatment, a typical situation in health (because of non-compliance to prescription) or digital advertising (because of competition and ad blockers for instance). The lower the compliance, the more the effect of treatment prescription, or individual prescription effect (IPE), signal fades away and becomes hard to capture. We propose a new approach to estimate IPE that takes advantage of observed compliance information to prevent signal fading. Using the Structural Causal Model framework and do-calculus, we define a general mediated causal effect setting under which our proposed estimator soundly recovers the IPE, and study its asymptotic variance. Finally, we conduct extensive experiments on both synthetic and real-world datasets that highlight the benefit of the approach, which consistently improves state-of-the-art in low compliance settings.