 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Counterfactual Risk Minimization
Feb 23, 2023Counterfactual Risk Minimization (CRM) is a framework for dealing with the logged bandit feedback problem, where the goal is to improve a logging policy using offline data. In this paper, we explore the case where it is possible to deploy learned policies multiple times and acquire new data. We extend the CRM principle and its theory to this scenario, which we call "Sequential Counterfactual Risk Minimization (SCRM)." We introduce a novel counterfactual estimator and identify conditions that can improve the performance of CRM in terms of excess risk and regret rates, by using an analysis similar to restart strategies in accelerated optimization methods. We also provide an empirical evaluation of our method in both discrete and continuous action settings, and demonstrate the benefits of multiple deployments of CRM.
Deep learning for ECoG brain-computer interface: end-to-end vs. hand-crafted features
Oct 05, 2022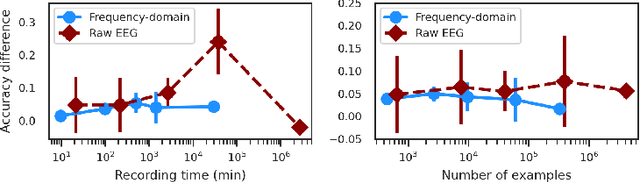
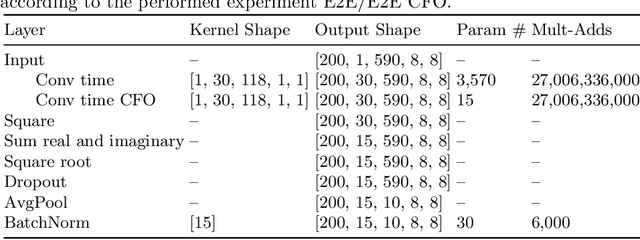

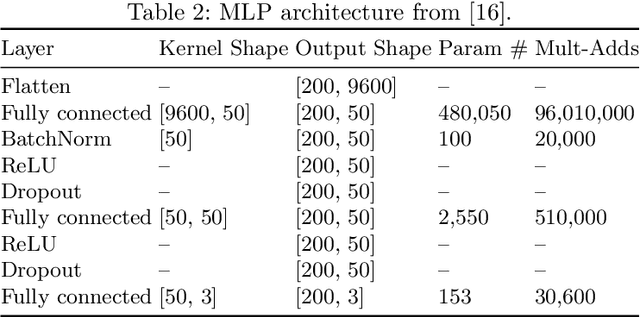
In brain signal processing, deep learning (DL) models have become commonly used. However, the performance gain from using end-to-end DL models compared to conventional ML approaches is usually significant but moderate, typically at the cost of increased computational load and deteriorated explainability. The core idea behind deep learning approaches is scaling the performance with bigger datasets. However, brain signals are temporal data with a low signal-to-noise ratio, uncertain labels, and nonstationary data in time. Those factors may influence the training process and slow down the models' performance improvement. These factors' influence may differ for end-to-end DL model and one using hand-crafted features. As not studied before, this paper compares models that use raw ECoG signal and time-frequency features for BCI motor imagery decoding. We investigate whether the current dataset size is a stronger limitation for any models. Finally, obtained filters were compared to identify differences between hand-crafted features and optimized with backpropagation. To compare the effectiveness of both strategies, we used a multilayer perceptron and a mix of convolutional and LSTM layers that were already proved effective in this task. The analysis was performed on the long-term clinical trial database (almost 600 minutes of recordings) of a tetraplegic patient executing motor imagery tasks for 3D hand translation. For a given dataset, the results showed that end-to-end training might not be significantly better than the hand-crafted features-based model. The performance gap is reduced with bigger datasets, but considering the increased computational load, end-to-end training may not be profitable for this application.
Impact of dataset size and long-term ECoG-based BCI usage on deep learning decoders performance
Sep 08, 2022

In brain-computer interfaces (BCI) research, recording data is time-consuming and expensive, which limits access to big datasets. This may influence the BCI system performance as machine learning methods depend strongly on the training dataset size. Important questions arise: taking into account neuronal signal characteristics (e.g., non-stationarity), can we achieve higher decoding performance with more data to train decoders? What is the perspective for further improvement with time in the case of long-term BCI studies? In this study, we investigated the impact of long-term recordings on motor imagery decoding from two main perspectives: model requirements regarding dataset size and potential for patient adaptation. We evaluated the multilinear model and two deep learning (DL) models on a long-term BCI and Tetraplegia NCT02550522 clinical trial dataset containing 43 sessions of ECoG recordings performed with a tetraplegic patient. In the experiment, a participant executed 3D virtual hand translation using motor imagery patterns. We designed multiple computational experiments in which training datasets were increased or translated to investigate the relationship between models' performance and different factors influencing recordings. Our analysis showed that adding more data to the training dataset may not instantly increase performance for datasets already containing 40 minutes of the signal. DL decoders showed similar requirements regarding the dataset size compared to the multilinear model while demonstrating higher decoding performance. Moreover, high decoding performance was obtained with relatively small datasets recorded later in the experiment, suggesting motor imagery patterns improvement and patient adaptation. Finally, we proposed UMAP embeddings and local intrinsic dimensionality as a way to visualize the data and potentially evaluate data quality.
Nested bandits
Jun 19, 2022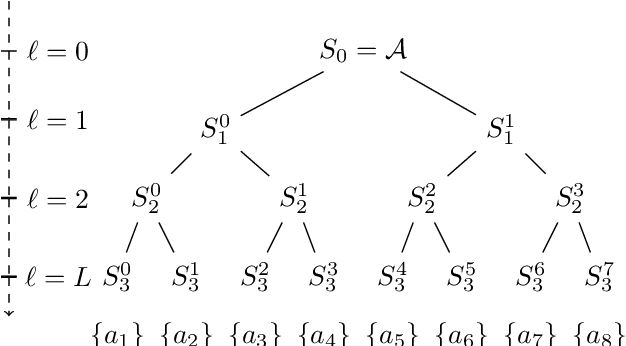
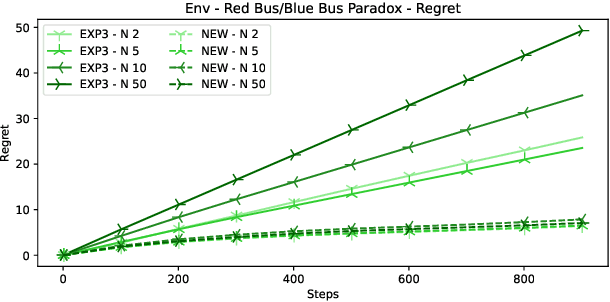
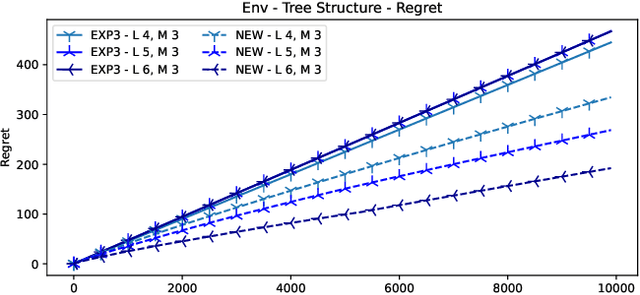
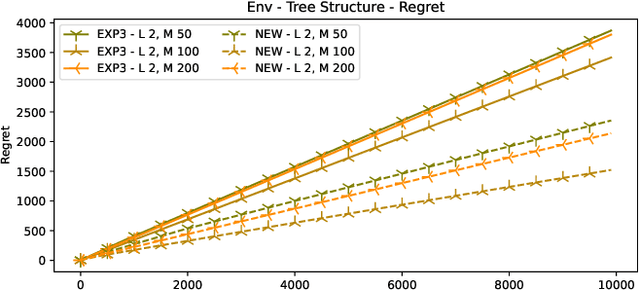
In many online decision processes, the optimizing agent is called to choose between large numbers of alternatives with many inherent similarities; in turn, these similarities imply closely correlated losses that may confound standard discrete choice models and bandit algorithms. We study this question in the context of nested bandits, a class of adversarial multi-armed bandit problems where the learner seeks to minimize their regret in the presence of a large number of distinct alternatives with a hierarchy of embedded (non-combinatorial) similarities. In this setting, optimal algorithms based on the exponential weights blueprint (like Hedge, EXP3, and their variants) may incur significant regret because they tend to spend excessive amounts of time exploring irrelevant alternatives with similar, suboptimal costs. To account for this, we propose a nested exponential weights (NEW) algorithm that performs a layered exploration of the learner's set of alternatives based on a nested, step-by-step selection method. In so doing, we obtain a series of tight bounds for the learner's regret showing that online learning problems with a high degree of similarity between alternatives can be resolved efficiently, without a red bus / blue bus paradox occurring.
Efficient Kernel UCB for Contextual Bandits
Feb 11, 2022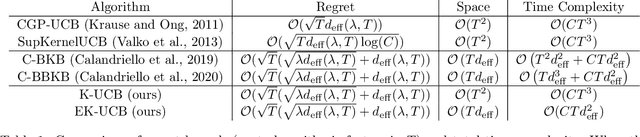
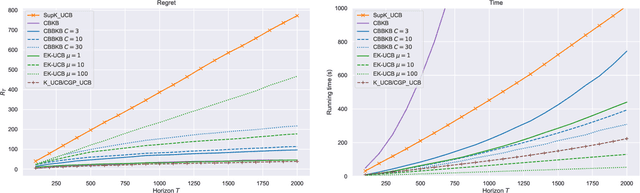
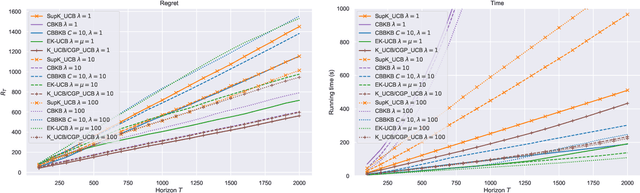
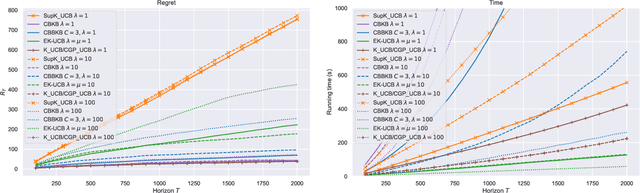
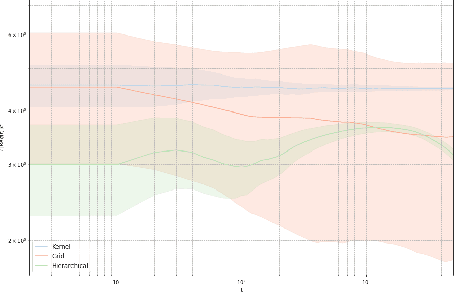
In this paper, we tackle the computational efficiency of kernelized UCB algorithms in contextual bandits. While standard methods require a O(CT^3) complexity where T is the horizon and the constant C is related to optimizing the UCB rule, we propose an efficient contextual algorithm for large-scale problems. Specifically, our method relies on incremental Nystrom approximations of the joint kernel embedding of contexts and actions. This allows us to achieve a complexity of O(CTm^2) where m is the number of Nystrom points. To recover the same regret as the standard kernelized UCB algorithm, m needs to be of order of the effective dimension of the problem, which is at most O(\sqrt(T)) and nearly constant in some cases.
Decoding ECoG signal into 3D hand translation using deep learning
Oct 05, 2021


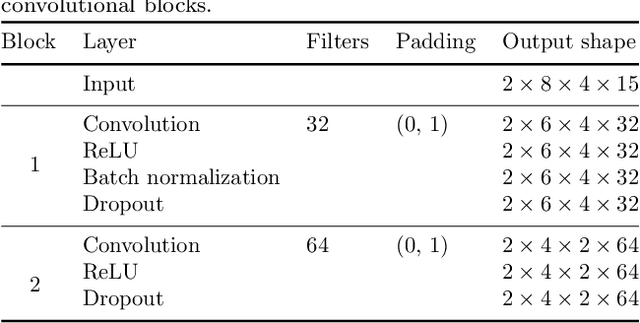
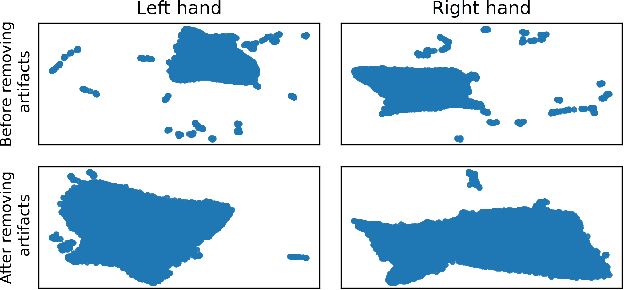
Motor brain-computer interfaces (BCIs) are a promising technology that may enable motor-impaired people to interact with their environment. Designing real-time and accurate BCI is crucial to make such devices useful, safe, and easy to use by patients in a real-life environment. Electrocorticography (ECoG)-based BCIs emerge as a good compromise between invasiveness of the recording device and good spatial and temporal resolution of the recorded signal. However, most ECoG signal decoders used to predict continuous hand movements are linear models. These models have a limited representational capacity and may fail to capture the relationship between ECoG signal and continuous hand movements. Deep learning (DL) models, which are state-of-the-art in many problems, could be a solution to better capture this relationship. In this study, we tested several DL-based architectures to predict imagined 3D continuous hand translation using time-frequency features extracted from ECoG signals. The dataset used in the analysis is a part of a long-term clinical trial (ClinicalTrials.gov identifier: NCT02550522) and was acquired during a closed-loop experiment with a tetraplegic subject. The proposed architectures include multilayer perceptron (MLP), convolutional neural networks (CNN), and long short-term memory networks (LSTM). The accuracy of the DL-based and multilinear models was compared offline using cosine similarity. Our results show that CNN-based architectures outperform the current state-of-the-art multilinear model. The best architecture exploited the spatial correlation between neighboring electrodes with CNN and benefited from the sequential character of the desired hand trajectory by using LSTMs. Overall, DL increased the average cosine similarity, compared to the multilinear model, by up to 60%, from 0.189 to 0.302 and from 0.157 to 0.249 for the left and right hand, respectively.
Zeroth-order non-convex learning via hierarchical dual averaging
Sep 13, 2021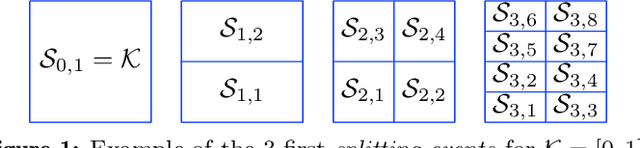
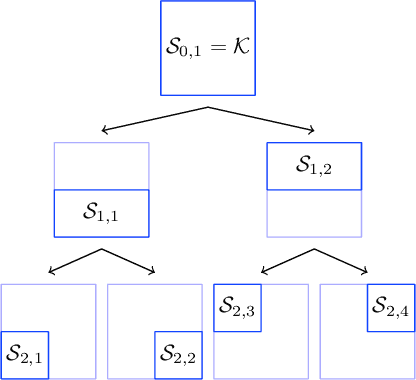
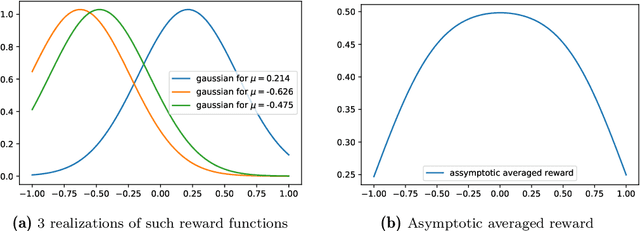
We propose a hierarchical version of dual averaging for zeroth-order online non-convex optimization - i.e., learning processes where, at each stage, the optimizer is facing an unknown non-convex loss function and only receives the incurred loss as feedback. The proposed class of policies relies on the construction of an online model that aggregates loss information as it arrives, and it consists of two principal components: (a) a regularizer adapted to the Fisher information metric (as opposed to the metric norm of the ambient space); and (b) a principled exploration of the problem's state space based on an adapted hierarchical schedule. This construction enables sharper control of the model's bias and variance, and allows us to derive tight bounds for both the learner's static and dynamic regret - i.e., the regret incurred against the best dynamic policy in hindsight over the horizon of play.
Automatic Segmentation and Location Learning of Neonatal Cerebral Ventricles in 3D Ultrasound Data Combining CNN and CPPN
Dec 05, 2020

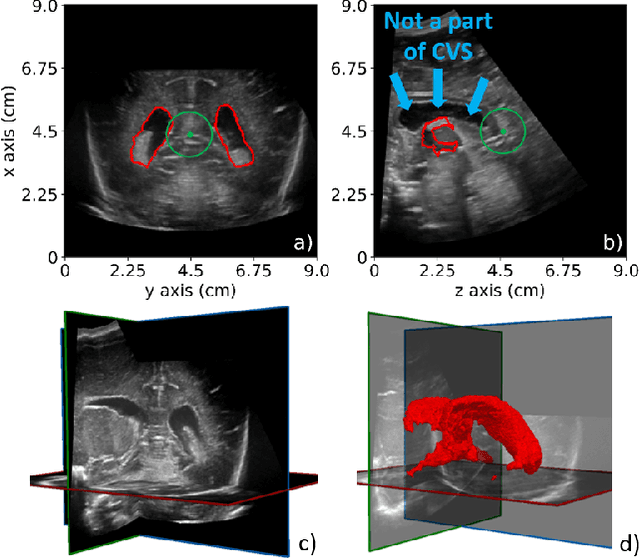

Preterm neonates are highly likely to suffer from ventriculomegaly, a dilation of the Cerebral Ventricular System (CVS). This condition can develop into life-threatening hydrocephalus and is correlated with future neuro-developmental impairments. Consequently, it must be detected and monitored by physicians. In clinical routing, manual 2D measurements are performed on 2D ultrasound (US) images to estimate the CVS volume but this practice is imprecise due to the unavailability of 3D information. A way to tackle this problem would be to develop automatic CVS segmentation algorithms for 3D US data. In this paper, we investigate the potential of 2D and 3D Convolutional Neural Networks (CNN) to solve this complex task and propose to use Compositional Pattern Producing Network (CPPN) to enable the CNNs to learn CVS location. Our database was composed of 25 3D US volumes collected on 21 preterm nenonates at the age of $35.8 \pm 1.6$ gestational weeks. We found that the CPPN enables to encode CVS location, which increases the accuracy of the CNNs when they have few layers. Accuracy of the 2D and 3D CNNs reached intraobserver variability (IOV) in the case of dilated ventricles with Dice of $0.893 \pm 0.008$ and $0.886 \pm 0.004$ respectively (IOV = $0.898 \pm 0.008$) and with volume errors of $0.45 \pm 0.42$ cm$^3$ and $0.36 \pm 0.24$ cm$^3$ respectively (IOV = $0.41 \pm 0.05$ cm$^3$). 3D CNNs were more accurate than 2D CNNs in the case of normal ventricles with Dice of $0.797 \pm 0.041$ against $0.776 \pm 0.038$ (IOV = $0.816 \pm 0.009$) and volume errors of $0.35 \pm 0.29$ cm$^3$ against $0.35 \pm 0.24$ cm$^3$ (IOV = $0.2 \pm 0.11$ cm$^3$). The best segmentation time of volumes of size $320 \times 320 \times 320$ was obtained by a 2D CNN in $3.5 \pm 0.2$ s.
Online non-convex optimization with imperfect feedback
Oct 16, 2020
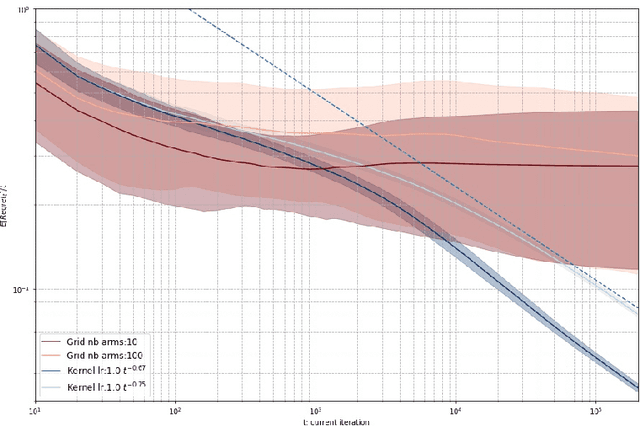
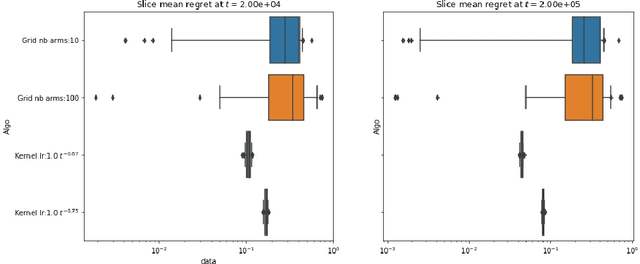
We consider the problem of online learning with non-convex losses. In terms of feedback, we assume that the learner observes - or otherwise constructs - an inexact model for the loss function encountered at each stage, and we propose a mixed-strategy learning policy based on dual averaging. In this general context, we derive a series of tight regret minimization guarantees, both for the learner's static (external) regret, as well as the regret incurred against the best dynamic policy in hindsight. Subsequently, we apply this general template to the case where the learner only has access to the actual loss incurred at each stage of the process. This is achieved by means of a kernel-based estimator which generates an inexact model for each round's loss function using only the learner's realized losses as input.
Individual Treatment Effect Estimation in a Low Compliance Setting
Aug 07, 2020
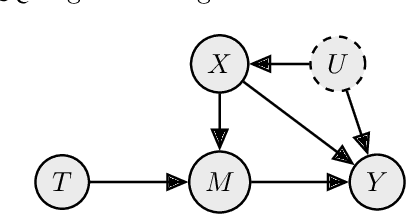
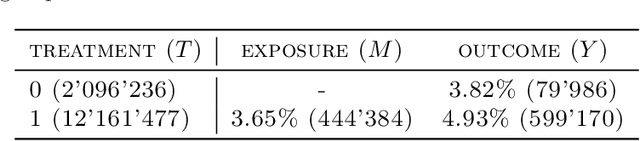
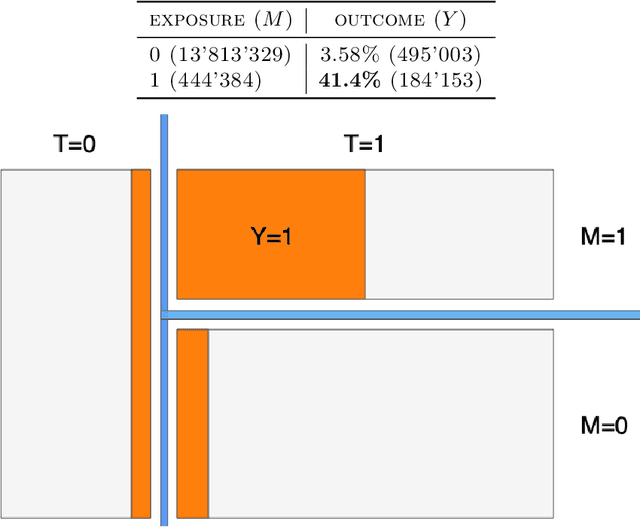
Individual Treatment Effect (ITE) estimation is an extensively researched problem, with applications in various domains. We model the case where there is heterogeneous non-compliance to a randomly assigned treatment, a typical situation in health (because of non-compliance to prescription) or digital advertising (because of competition and ad blockers for instance). The lower the compliance, the more the effect of treatment prescription, or individual prescription effect (IPE), signal fades away and becomes hard to capture. We propose a new approach to estimate IPE that takes advantage of observed compliance information to prevent signal fading. Using the Structural Causal Model framework and do-calculus, we define a general mediated causal effect setting under which our proposed estimator soundly recovers the IPE, and study its asymptotic variance. Finally, we conduct extensive experiments on both synthetic and real-world datasets that highlight the benefit of the approach, which consistently improves state-of-the-art in low compliance settings.