 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpact of dataset size and long-term ECoG-based BCI usage on deep learning decoders performance
Paper and Code
Sep 08, 2022

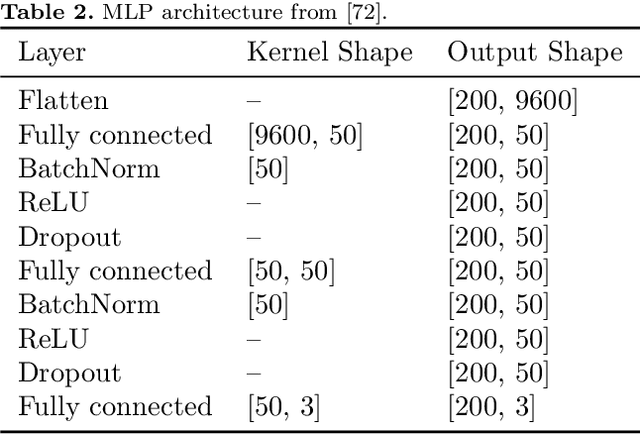
In brain-computer interfaces (BCI) research, recording data is time-consuming and expensive, which limits access to big datasets. This may influence the BCI system performance as machine learning methods depend strongly on the training dataset size. Important questions arise: taking into account neuronal signal characteristics (e.g., non-stationarity), can we achieve higher decoding performance with more data to train decoders? What is the perspective for further improvement with time in the case of long-term BCI studies? In this study, we investigated the impact of long-term recordings on motor imagery decoding from two main perspectives: model requirements regarding dataset size and potential for patient adaptation. We evaluated the multilinear model and two deep learning (DL) models on a long-term BCI and Tetraplegia NCT02550522 clinical trial dataset containing 43 sessions of ECoG recordings performed with a tetraplegic patient. In the experiment, a participant executed 3D virtual hand translation using motor imagery patterns. We designed multiple computational experiments in which training datasets were increased or translated to investigate the relationship between models' performance and different factors influencing recordings. Our analysis showed that adding more data to the training dataset may not instantly increase performance for datasets already containing 40 minutes of the signal. DL decoders showed similar requirements regarding the dataset size compared to the multilinear model while demonstrating higher decoding performance. Moreover, high decoding performance was obtained with relatively small datasets recorded later in the experiment, suggesting motor imagery patterns improvement and patient adaptation. Finally, we proposed UMAP embeddings and local intrinsic dimensionality as a way to visualize the data and potentially evaluate data quality.