 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataset Dictionary Learning in a Wasserstein Space for Federated Domain Adaptation
Jul 16, 2024



Multi-Source Domain Adaptation (MSDA) is a challenging scenario where multiple related and heterogeneous source datasets must be adapted to an unlabeled target dataset. Conventional MSDA methods often overlook that data holders may have privacy concerns, hindering direct data sharing. In response, decentralized MSDA has emerged as a promising strategy to achieve adaptation without centralizing clients' data. Our work proposes a novel approach, Decentralized Dataset Dictionary Learning, to address this challenge. Our method leverages Wasserstein barycenters to model the distributional shift across multiple clients, enabling effective adaptation while preserving data privacy. Specifically, our algorithm expresses each client's underlying distribution as a Wasserstein barycenter of public atoms, weighted by private barycentric coordinates. Our approach ensures that the barycentric coordinates remain undisclosed throughout the adaptation process. Extensive experimentation across five visual domain adaptation benchmarks demonstrates the superiority of our strategy over existing decentralized MSDA techniques. Moreover, our method exhibits enhanced robustness to client parallelism while maintaining relative resilience compared to conventional decentralized MSDA methodologies.
Lighter, Better, Faster Multi-Source Domain Adaptation with Gaussian Mixture Models and Optimal Transport
Apr 16, 2024



In this paper, we tackle Multi-Source Domain Adaptation (MSDA), a task in transfer learning where one adapts multiple heterogeneous, labeled source probability measures towards a different, unlabeled target measure. We propose a novel framework for MSDA, based on Optimal Transport (OT) and Gaussian Mixture Models (GMMs). Our framework has two key advantages. First, OT between GMMs can be solved efficiently via linear programming. Second, it provides a convenient model for supervised learning, especially classification, as components in the GMM can be associated with existing classes. Based on the GMM-OT problem, we propose a novel technique for calculating barycenters of GMMs. Based on this novel algorithm, we propose two new strategies for MSDA: GMM-WBT and GMM-DaDiL. We empirically evaluate our proposed methods on four benchmarks in image classification and fault diagnosis, showing that we improve over the prior art while being faster and involving fewer parameters.
Optimal Transport for Domain Adaptation through Gaussian Mixture Models
Mar 18, 2024In this paper we explore domain adaptation through optimal transport. We propose a novel approach, where we model the data distributions through Gaussian mixture models. This strategy allows us to solve continuous optimal transport through an equivalent discrete problem. The optimal transport solution gives us a matching between source and target domain mixture components. From this matching, we can map data points between domains, or transfer the labels from the source domain components towards the target domain. We experiment with 2 domain adaptation benchmarks in fault diagnosis, showing that our methods have state-of-the-art performance.
Federated Dataset Dictionary Learning for Multi-Source Domain Adaptation
Sep 14, 2023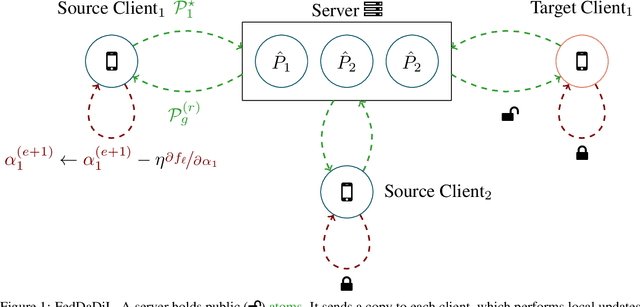

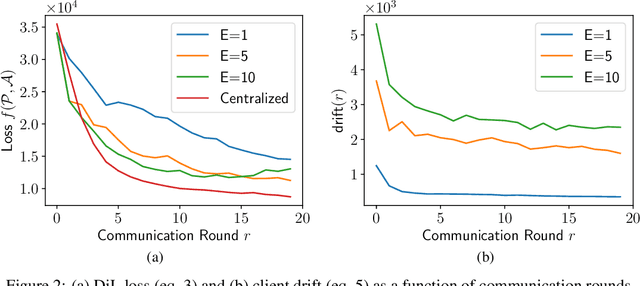
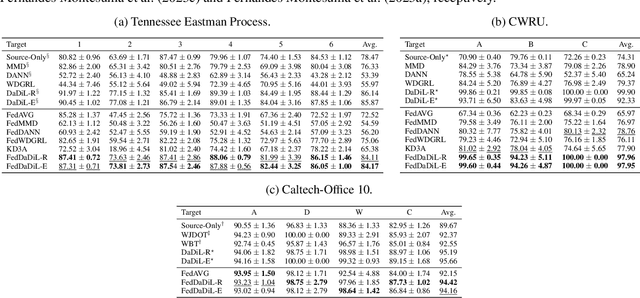
In this article, we propose an approach for federated domain adaptation, a setting where distributional shift exists among clients and some have unlabeled data. The proposed framework, FedDaDiL, tackles the resulting challenge through dictionary learning of empirical distributions. In our setting, clients' distributions represent particular domains, and FedDaDiL collectively trains a federated dictionary of empirical distributions. In particular, we build upon the Dataset Dictionary Learning framework by designing collaborative communication protocols and aggregation operations. The chosen protocols keep clients' data private, thus enhancing overall privacy compared to its centralized counterpart. We empirically demonstrate that our approach successfully generates labeled data on the target domain with extensive experiments on (i) Caltech-Office, (ii) TEP, and (iii) CWRU benchmarks. Furthermore, we compare our method to its centralized counterpart and other benchmarks in federated domain adaptation.
Multi-Source Domain Adaptation meets Dataset Distillation through Dataset Dictionary Learning
Sep 14, 2023In this paper, we consider the intersection of two problems in machine learning: Multi-Source Domain Adaptation (MSDA) and Dataset Distillation (DD). On the one hand, the first considers adapting multiple heterogeneous labeled source domains to an unlabeled target domain. On the other hand, the second attacks the problem of synthesizing a small summary containing all the information about the datasets. We thus consider a new problem called MSDA-DD. To solve it, we adapt previous works in the MSDA literature, such as Wasserstein Barycenter Transport and Dataset Dictionary Learning, as well as DD method Distribution Matching. We thoroughly experiment with this novel problem on four benchmarks (Caltech-Office 10, Tennessee-Eastman Process, Continuous Stirred Tank Reactor, and Case Western Reserve University), where we show that, even with as little as 1 sample per class, one achieves state-of-the-art adaptation performance.
Multi-Source Domain Adaptation for Cross-Domain Fault Diagnosis of Chemical Processes
Aug 22, 2023Fault diagnosis is an essential component in process supervision. Indeed, it determines which kind of fault has occurred, given that it has been previously detected, allowing for appropriate intervention. Automatic fault diagnosis systems use machine learning for predicting the fault type from sensor readings. Nonetheless, these models are sensible to changes in the data distributions, which may be caused by changes in the monitored process, such as changes in the mode of operation. This scenario is known as Cross-Domain Fault Diagnosis (CDFD). We provide an extensive comparison of single and multi-source unsupervised domain adaptation (SSDA and MSDA respectively) algorithms for CDFD. We study these methods in the context of the Tennessee-Eastmann Process, a widely used benchmark in the chemical industry. We show that using multiple domains during training has a positive effect, even when no adaptation is employed. As such, the MSDA baseline improves over the SSDA baseline classification accuracy by 23% on average. In addition, under the multiple-sources scenario, we improve classification accuracy of the no adaptation setting by 8.4% on average.
Multi-Source Domain Adaptation through Dataset Dictionary Learning in Wasserstein Space
Jul 27, 2023



This paper seeks to solve Multi-Source Domain Adaptation (MSDA), which aims to mitigate data distribution shifts when transferring knowledge from multiple labeled source domains to an unlabeled target domain. We propose a novel MSDA framework based on dictionary learning and optimal transport. We interpret each domain in MSDA as an empirical distribution. As such, we express each domain as a Wasserstein barycenter of dictionary atoms, which are empirical distributions. We propose a novel algorithm, DaDiL, for learning via mini-batches: (i) atom distributions; (ii) a matrix of barycentric coordinates. Based on our dictionary, we propose two novel methods for MSDA: DaDil-R, based on the reconstruction of labeled samples in the target domain, and DaDiL-E, based on the ensembling of classifiers learned on atom distributions. We evaluate our methods in 3 benchmarks: Caltech-Office, Office 31, and CRWU, where we improved previous state-of-the-art by 3.15%, 2.29%, and 7.71% in classification performance. Finally, we show that interpolations in the Wasserstein hull of learned atoms provide data that can generalize to the target domain.
Recent Advances in Optimal Transport for Machine Learning
Jun 28, 2023Recently, Optimal Transport has been proposed as a probabilistic framework in Machine Learning for comparing and manipulating probability distributions. This is rooted in its rich history and theory, and has offered new solutions to different problems in machine learning, such as generative modeling and transfer learning. In this survey we explore contributions of Optimal Transport for Machine Learning over the period 2012 -- 2022, focusing on four sub-fields of Machine Learning: supervised, unsupervised, transfer and reinforcement learning. We further highlight the recent development in computational Optimal Transport, and its interplay with Machine Learning practice.
Deep learning for ECoG brain-computer interface: end-to-end vs. hand-crafted features
Oct 05, 2022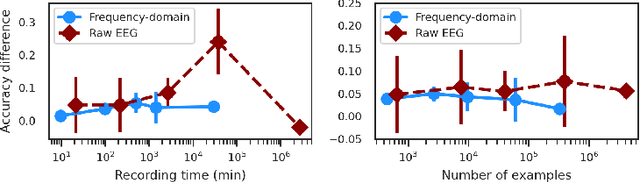
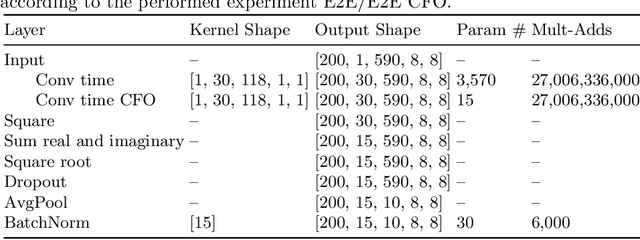

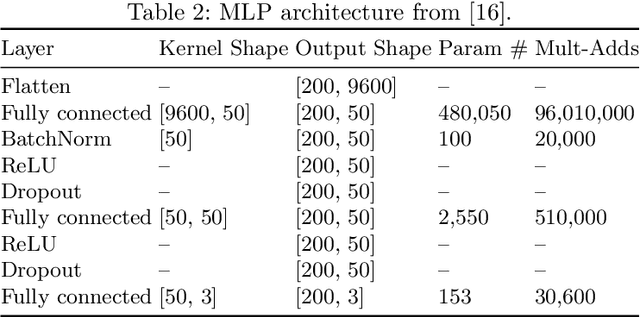
In brain signal processing, deep learning (DL) models have become commonly used. However, the performance gain from using end-to-end DL models compared to conventional ML approaches is usually significant but moderate, typically at the cost of increased computational load and deteriorated explainability. The core idea behind deep learning approaches is scaling the performance with bigger datasets. However, brain signals are temporal data with a low signal-to-noise ratio, uncertain labels, and nonstationary data in time. Those factors may influence the training process and slow down the models' performance improvement. These factors' influence may differ for end-to-end DL model and one using hand-crafted features. As not studied before, this paper compares models that use raw ECoG signal and time-frequency features for BCI motor imagery decoding. We investigate whether the current dataset size is a stronger limitation for any models. Finally, obtained filters were compared to identify differences between hand-crafted features and optimized with backpropagation. To compare the effectiveness of both strategies, we used a multilayer perceptron and a mix of convolutional and LSTM layers that were already proved effective in this task. The analysis was performed on the long-term clinical trial database (almost 600 minutes of recordings) of a tetraplegic patient executing motor imagery tasks for 3D hand translation. For a given dataset, the results showed that end-to-end training might not be significantly better than the hand-crafted features-based model. The performance gap is reduced with bigger datasets, but considering the increased computational load, end-to-end training may not be profitable for this application.
Impact of dataset size and long-term ECoG-based BCI usage on deep learning decoders performance
Sep 08, 2022

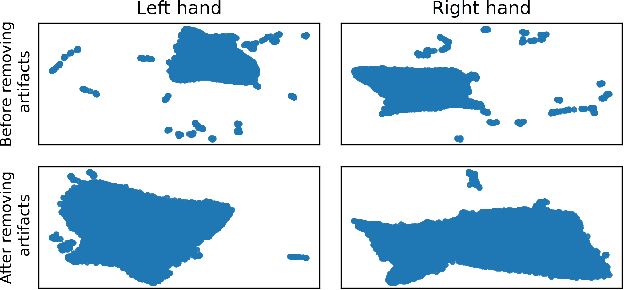
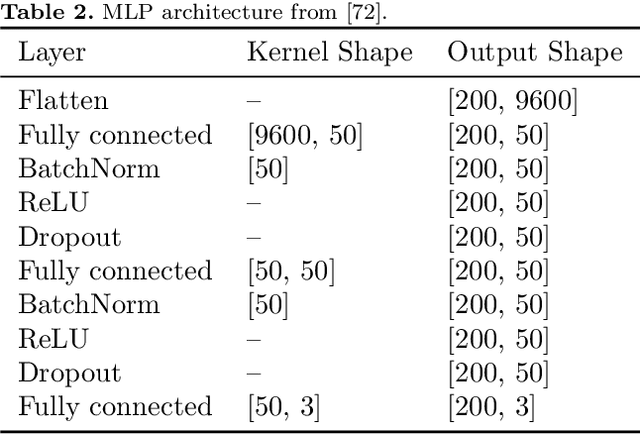
In brain-computer interfaces (BCI) research, recording data is time-consuming and expensive, which limits access to big datasets. This may influence the BCI system performance as machine learning methods depend strongly on the training dataset size. Important questions arise: taking into account neuronal signal characteristics (e.g., non-stationarity), can we achieve higher decoding performance with more data to train decoders? What is the perspective for further improvement with time in the case of long-term BCI studies? In this study, we investigated the impact of long-term recordings on motor imagery decoding from two main perspectives: model requirements regarding dataset size and potential for patient adaptation. We evaluated the multilinear model and two deep learning (DL) models on a long-term BCI and Tetraplegia NCT02550522 clinical trial dataset containing 43 sessions of ECoG recordings performed with a tetraplegic patient. In the experiment, a participant executed 3D virtual hand translation using motor imagery patterns. We designed multiple computational experiments in which training datasets were increased or translated to investigate the relationship between models' performance and different factors influencing recordings. Our analysis showed that adding more data to the training dataset may not instantly increase performance for datasets already containing 40 minutes of the signal. DL decoders showed similar requirements regarding the dataset size compared to the multilinear model while demonstrating higher decoding performance. Moreover, high decoding performance was obtained with relatively small datasets recorded later in the experiment, suggesting motor imagery patterns improvement and patient adaptation. Finally, we proposed UMAP embeddings and local intrinsic dimensionality as a way to visualize the data and potentially evaluate data quality.