 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeFed-GMM-DaDiL: A Decentralized Federated Framework for Domain Adaptation
May 05, 2026Decentralized multi-source domain adaptation seeks to transfer knowledge from multiple heterogeneous and related source domains to an unlabeled target domain in a decentralized setting. We address this challenge through a fully decentralized federated approach, DeFed-GMM-DaDiL, an extension of the GMM-Dataset Dictionary Learning (DaDiL) framework. Each client models its dataset as a Gaussian Mixture Model (GMM), and the federation jointly approximates them via labeled Wasserstein barycenters of shared, learnable GMM atoms. This design enables adaptation without a central server while preserving clients' privacy. We empirically study the stability of the learned representations in scenarios where the target domain has missing classes. Empirical results demonstrate that DeFed-GMM-DaDiL maintains stable and consistent shared representations across clients, effectively reconstructs missing classes, and achieves competitive performance on multi-source domain adaptation benchmarks.
Gromov-Wasserstein Methods for Multi-View Relational Embedding and Clustering
Apr 26, 2026Learning low-dimensional representations from multi-view relational data is challenging when underlying geometries differ across views. We propose Bary-GWMDS, a Gromov-Wasserstein-based method that operates directly on distance matrices to learn a consensus embedding preserving shared relational structure. By leveraging intrinsic distances, the approach naturally handles nonlinear distortions across views. We also introduce Mean-GWMDS-C, a clustering-oriented formulation that averages distance matrices and learns reduced-support representations via a consensus Gromov-Wasserstein transport. Experiments on synthetic and real-world datasets show that the proposed framework yields stable and geometrically meaningful embeddings.
Structure-Preserving Multi-View Embedding Using Gromov-Wasserstein Optimal Transport
Apr 03, 2026Multi-view data analysis seeks to integrate multiple representations of the same samples in order to recover a coherent low-dimensional structure. Classical approaches often rely on feature concatenation or explicit alignment assumptions, which become restrictive under heterogeneous geometries or nonlinear distortions. In this work, we propose two geometry-aware multi-view embedding strategies grounded in Gromov-Wasserstein (GW) optimal transport. The first, termed Mean-GWMDS, aggregates view-specific relational information by averaging distance matrices and applying GW-based multidimensional scaling to obtain a representative embedding. The second strategy, referred to as Multi-GWMDS, adopts a selection-based paradigm in which multiple geometry-consistent candidate embeddings are generated via GW-based alignment and a representative embedding is selected. Experiments on synthetic manifolds and real-world datasets show that the proposed methods effectively preserve intrinsic relational structure across views. These results highlight GW-based approaches as a flexible and principled framework for multi-view representation learning.
Computing Wasserstein Barycenters through Gradient Flows
Oct 06, 2025Wasserstein barycenters provide a powerful tool for aggregating probability measures, while leveraging the geometry of their ambient space. Existing discrete methods suffer from poor scalability, as they require access to the complete set of samples from input measures. We address this issue by recasting the original barycenter problem as a gradient flow in the Wasserstein space. Our approach offers two advantages. First, we achieve scalability by sampling mini-batches from the input measures. Second, we incorporate functionals over probability measures, which regularize the barycenter problem through internal, potential, and interaction energies. We present two algorithms for empirical and Gaussian mixture measures, providing convergence guarantees under the Polyak-{\L}ojasiewicz inequality. Experimental validation on toy datasets and domain adaptation benchmarks show that our methods outperform previous discrete and neural net-based methods for computing Wasserstein barycenters.
KD$^{2}$M: An unifying framework for feature knowledge distillation
Apr 02, 2025



Knowledge Distillation (KD) seeks to transfer the knowledge of a teacher, towards a student neural net. This process is often done by matching the networks' predictions (i.e., their output), but, recently several works have proposed to match the distributions of neural nets' activations (i.e., their features), a process known as \emph{distribution matching}. In this paper, we propose an unifying framework, Knowledge Distillation through Distribution Matching (KD$^{2}$M), which formalizes this strategy. Our contributions are threefold. We i) provide an overview of distribution metrics used in distribution matching, ii) benchmark on computer vision datasets, and iii) derive new theoretical results for KD.
Unsupervised Anomaly Detection through Mass Repulsing Optimal Transport
Feb 18, 2025
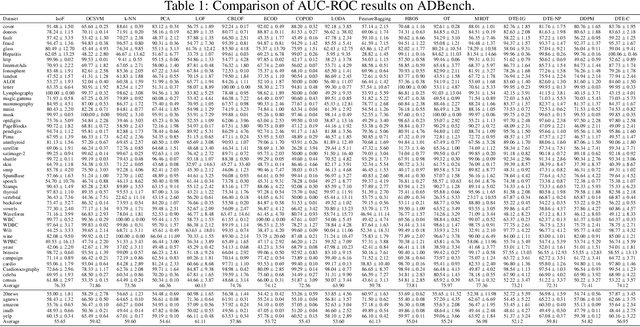
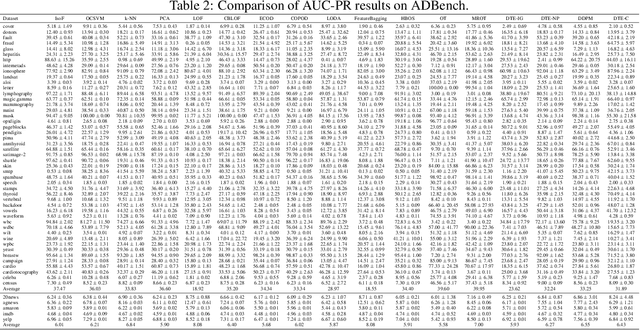
Detecting anomalies in datasets is a longstanding problem in machine learning. In this context, anomalies are defined as a sample that significantly deviates from the remaining data. Meanwhile, optimal transport (OT) is a field of mathematics concerned with the transportation, between two probability measures, at least effort. In classical OT, the optimal transportation strategy of a measure to itself is the identity. In this paper, we tackle anomaly detection by forcing samples to displace its mass, while keeping the least effort objective. We call this new transportation problem Mass Repulsing Optimal Transport (MROT). Naturally, samples lying in low density regions of space will be forced to displace mass very far, incurring a higher transportation cost. We use these concepts to design a new anomaly score. Through a series of experiments in existing benchmarks, and fault detection problems, we show that our algorithm improves over existing methods.
A dimensionality reduction technique based on the Gromov-Wasserstein distance
Jan 23, 2025Analyzing relationships between objects is a pivotal problem within data science. In this context, Dimensionality reduction (DR) techniques are employed to generate smaller and more manageable data representations. This paper proposes a new method for dimensionality reduction, based on optimal transportation theory and the Gromov-Wasserstein distance. We offer a new probabilistic view of the classical Multidimensional Scaling (MDS) algorithm and the nonlinear dimensionality reduction algorithm, Isomap (Isometric Mapping or Isometric Feature Mapping) that extends the classical MDS, in which we use the Gromov-Wasserstein distance between the probability measure of high-dimensional data, and its low-dimensional representation. Through gradient descent, our method embeds high-dimensional data into a lower-dimensional space, providing a robust and efficient solution for analyzing complex high-dimensional datasets.
Online Multi-Source Domain Adaptation through Gaussian Mixtures and Dataset Dictionary Learning
Jul 29, 2024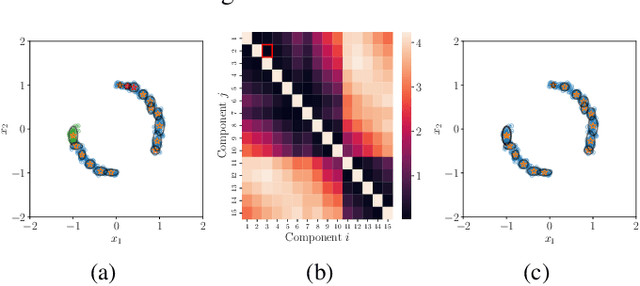
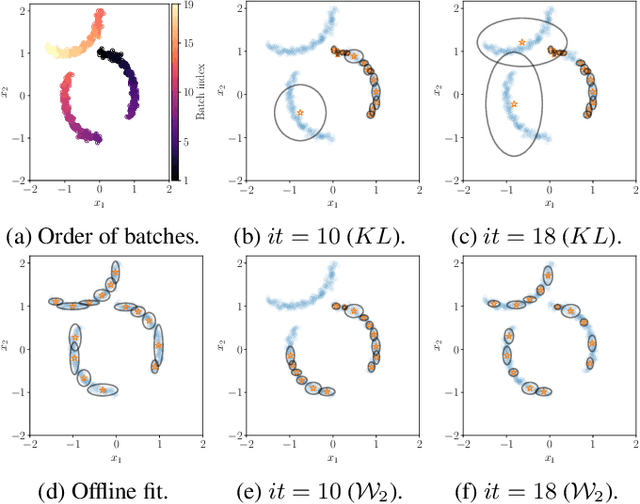
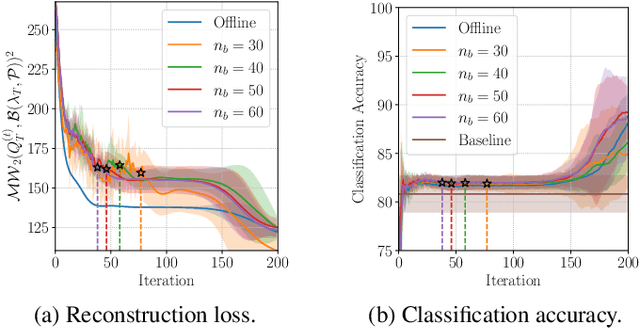
This paper addresses the challenge of online multi-source domain adaptation (MSDA) in transfer learning, a scenario where one needs to adapt multiple, heterogeneous source domains towards a target domain that comes in a stream. We introduce a novel approach for the online fit of a Gaussian Mixture Model (GMM), based on the Wasserstein geometry of Gaussian measures. We build upon this method and recent developments in dataset dictionary learning for proposing a novel strategy in online MSDA. Experiments on the challenging Tennessee Eastman Process benchmark demonstrate that our approach is able to adapt \emph{on the fly} to the stream of target domain data. Furthermore, our online GMM serves as a memory, representing the whole stream of data.
Dataset Dictionary Learning in a Wasserstein Space for Federated Domain Adaptation
Jul 16, 2024



Multi-Source Domain Adaptation (MSDA) is a challenging scenario where multiple related and heterogeneous source datasets must be adapted to an unlabeled target dataset. Conventional MSDA methods often overlook that data holders may have privacy concerns, hindering direct data sharing. In response, decentralized MSDA has emerged as a promising strategy to achieve adaptation without centralizing clients' data. Our work proposes a novel approach, Decentralized Dataset Dictionary Learning, to address this challenge. Our method leverages Wasserstein barycenters to model the distributional shift across multiple clients, enabling effective adaptation while preserving data privacy. Specifically, our algorithm expresses each client's underlying distribution as a Wasserstein barycenter of public atoms, weighted by private barycentric coordinates. Our approach ensures that the barycentric coordinates remain undisclosed throughout the adaptation process. Extensive experimentation across five visual domain adaptation benchmarks demonstrates the superiority of our strategy over existing decentralized MSDA techniques. Moreover, our method exhibits enhanced robustness to client parallelism while maintaining relative resilience compared to conventional decentralized MSDA methodologies.
Lighter, Better, Faster Multi-Source Domain Adaptation with Gaussian Mixture Models and Optimal Transport
Apr 16, 2024



In this paper, we tackle Multi-Source Domain Adaptation (MSDA), a task in transfer learning where one adapts multiple heterogeneous, labeled source probability measures towards a different, unlabeled target measure. We propose a novel framework for MSDA, based on Optimal Transport (OT) and Gaussian Mixture Models (GMMs). Our framework has two key advantages. First, OT between GMMs can be solved efficiently via linear programming. Second, it provides a convenient model for supervised learning, especially classification, as components in the GMM can be associated with existing classes. Based on the GMM-OT problem, we propose a novel technique for calculating barycenters of GMMs. Based on this novel algorithm, we propose two new strategies for MSDA: GMM-WBT and GMM-DaDiL. We empirically evaluate our proposed methods on four benchmarks in image classification and fault diagnosis, showing that we improve over the prior art while being faster and involving fewer parameters.