 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataset Dictionary Learning in a Wasserstein Space for Federated Domain Adaptation
Jul 16, 2024



Multi-Source Domain Adaptation (MSDA) is a challenging scenario where multiple related and heterogeneous source datasets must be adapted to an unlabeled target dataset. Conventional MSDA methods often overlook that data holders may have privacy concerns, hindering direct data sharing. In response, decentralized MSDA has emerged as a promising strategy to achieve adaptation without centralizing clients' data. Our work proposes a novel approach, Decentralized Dataset Dictionary Learning, to address this challenge. Our method leverages Wasserstein barycenters to model the distributional shift across multiple clients, enabling effective adaptation while preserving data privacy. Specifically, our algorithm expresses each client's underlying distribution as a Wasserstein barycenter of public atoms, weighted by private barycentric coordinates. Our approach ensures that the barycentric coordinates remain undisclosed throughout the adaptation process. Extensive experimentation across five visual domain adaptation benchmarks demonstrates the superiority of our strategy over existing decentralized MSDA techniques. Moreover, our method exhibits enhanced robustness to client parallelism while maintaining relative resilience compared to conventional decentralized MSDA methodologies.
Federated learning with incremental clustering for heterogeneous data
Jun 17, 2022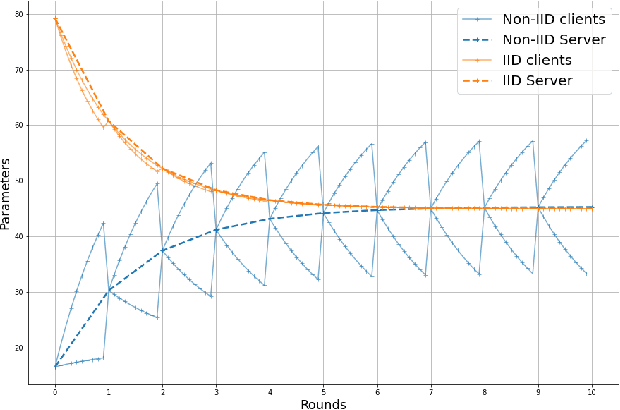
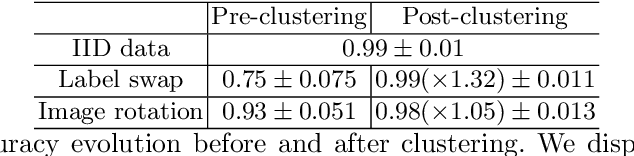
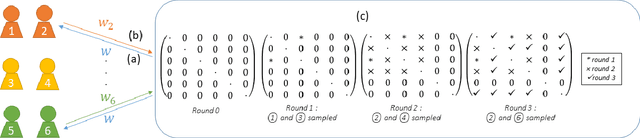

Federated learning enables different parties to collaboratively build a global model under the orchestration of a server while keeping the training data on clients' devices. However, performance is affected when clients have heterogeneous data. To cope with this problem, we assume that despite data heterogeneity, there are groups of clients who have similar data distributions that can be clustered. In previous approaches, in order to cluster clients the server requires clients to send their parameters simultaneously. However, this can be problematic in a context where there is a significant number of participants that may have limited availability. To prevent such a bottleneck, we propose FLIC (Federated Learning with Incremental Clustering), in which the server exploits the updates sent by clients during federated training instead of asking them to send their parameters simultaneously. Hence no additional communications between the server and the clients are necessary other than what classical federated learning requires. We empirically demonstrate for various non-IID cases that our approach successfully splits clients into groups following the same data distributions. We also identify the limitations of FLIC by studying its capability to partition clients at the early stages of the federated learning process efficiently. We further address attacks on models as a form of data heterogeneity and empirically show that FLIC is a robust defense against poisoning attacks even when the proportion of malicious clients is higher than 50\%.