 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataset Dictionary Learning in a Wasserstein Space for Federated Domain Adaptation
Jul 16, 2024



Multi-Source Domain Adaptation (MSDA) is a challenging scenario where multiple related and heterogeneous source datasets must be adapted to an unlabeled target dataset. Conventional MSDA methods often overlook that data holders may have privacy concerns, hindering direct data sharing. In response, decentralized MSDA has emerged as a promising strategy to achieve adaptation without centralizing clients' data. Our work proposes a novel approach, Decentralized Dataset Dictionary Learning, to address this challenge. Our method leverages Wasserstein barycenters to model the distributional shift across multiple clients, enabling effective adaptation while preserving data privacy. Specifically, our algorithm expresses each client's underlying distribution as a Wasserstein barycenter of public atoms, weighted by private barycentric coordinates. Our approach ensures that the barycentric coordinates remain undisclosed throughout the adaptation process. Extensive experimentation across five visual domain adaptation benchmarks demonstrates the superiority of our strategy over existing decentralized MSDA techniques. Moreover, our method exhibits enhanced robustness to client parallelism while maintaining relative resilience compared to conventional decentralized MSDA methodologies.
Federated Dataset Dictionary Learning for Multi-Source Domain Adaptation
Sep 14, 2023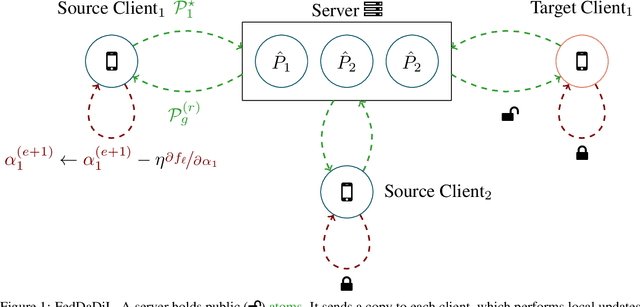

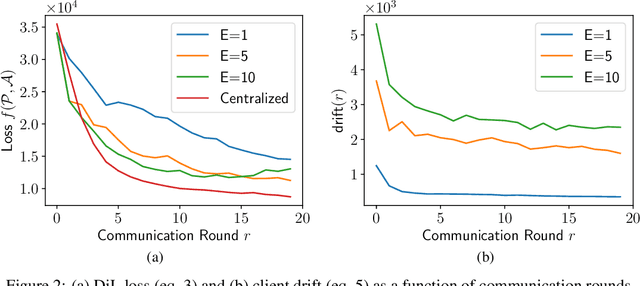
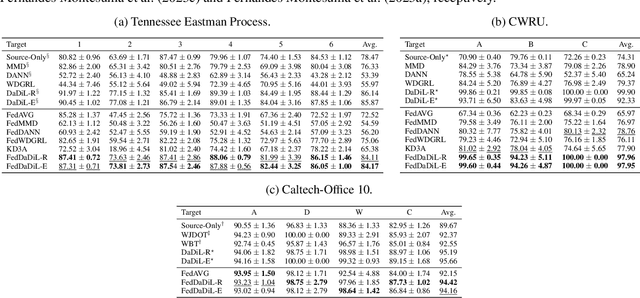
In this article, we propose an approach for federated domain adaptation, a setting where distributional shift exists among clients and some have unlabeled data. The proposed framework, FedDaDiL, tackles the resulting challenge through dictionary learning of empirical distributions. In our setting, clients' distributions represent particular domains, and FedDaDiL collectively trains a federated dictionary of empirical distributions. In particular, we build upon the Dataset Dictionary Learning framework by designing collaborative communication protocols and aggregation operations. The chosen protocols keep clients' data private, thus enhancing overall privacy compared to its centralized counterpart. We empirically demonstrate that our approach successfully generates labeled data on the target domain with extensive experiments on (i) Caltech-Office, (ii) TEP, and (iii) CWRU benchmarks. Furthermore, we compare our method to its centralized counterpart and other benchmarks in federated domain adaptation.