 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy is the prediction wrong? Towards underfitting case explanation via meta-classification
Feb 20, 2023



In this paper we present a heuristic method to provide individual explanations for those elements in a dataset (data points) which are wrongly predicted by a given classifier. Since the general case is too difficult, in the present work we focus on faulty data from an underfitted model. First, we project the faulty data into a hand-crafted, and thus human readable, intermediate representation (meta-representation, profile vectors), with the aim of separating the two main causes of miss-classification: the classifier is not strong enough, or the data point belongs to an area of the input space where classes are not separable. Second, in the space of these profile vectors, we present a method to fit a meta-classifier (decision tree) and express its output as a set of interpretable (human readable) explanation rules, which leads to several target diagnosis labels: data point is either correctly classified, or faulty due to a too weak model, or faulty due to mixed (overlapped) classes in the input space. Experimental results on several real datasets show more than 80% diagnosis label accuracy and confirm that the proposed intermediate representation allows to achieve a high degree of invariance with respect to the classifier used in the input space and to the dataset being classified, i.e. we can learn the metaclassifier on a dataset with a given classifier and successfully predict diagnosis labels for a different dataset or classifier (or both).
Deep learning for ECoG brain-computer interface: end-to-end vs. hand-crafted features
Oct 05, 2022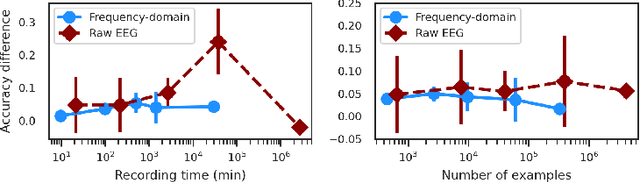
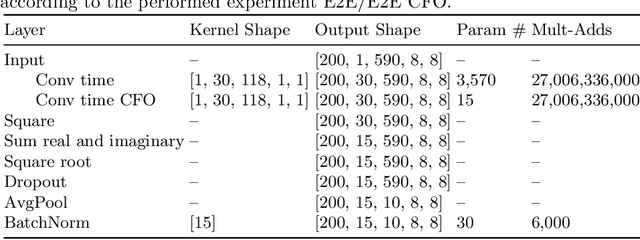

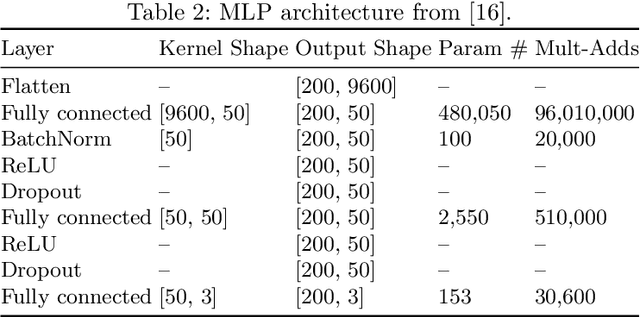
In brain signal processing, deep learning (DL) models have become commonly used. However, the performance gain from using end-to-end DL models compared to conventional ML approaches is usually significant but moderate, typically at the cost of increased computational load and deteriorated explainability. The core idea behind deep learning approaches is scaling the performance with bigger datasets. However, brain signals are temporal data with a low signal-to-noise ratio, uncertain labels, and nonstationary data in time. Those factors may influence the training process and slow down the models' performance improvement. These factors' influence may differ for end-to-end DL model and one using hand-crafted features. As not studied before, this paper compares models that use raw ECoG signal and time-frequency features for BCI motor imagery decoding. We investigate whether the current dataset size is a stronger limitation for any models. Finally, obtained filters were compared to identify differences between hand-crafted features and optimized with backpropagation. To compare the effectiveness of both strategies, we used a multilayer perceptron and a mix of convolutional and LSTM layers that were already proved effective in this task. The analysis was performed on the long-term clinical trial database (almost 600 minutes of recordings) of a tetraplegic patient executing motor imagery tasks for 3D hand translation. For a given dataset, the results showed that end-to-end training might not be significantly better than the hand-crafted features-based model. The performance gap is reduced with bigger datasets, but considering the increased computational load, end-to-end training may not be profitable for this application.
Impact of dataset size and long-term ECoG-based BCI usage on deep learning decoders performance
Sep 08, 2022

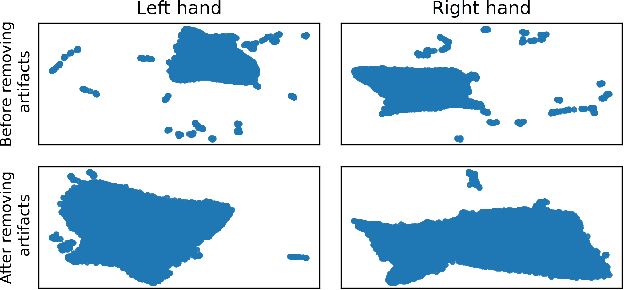
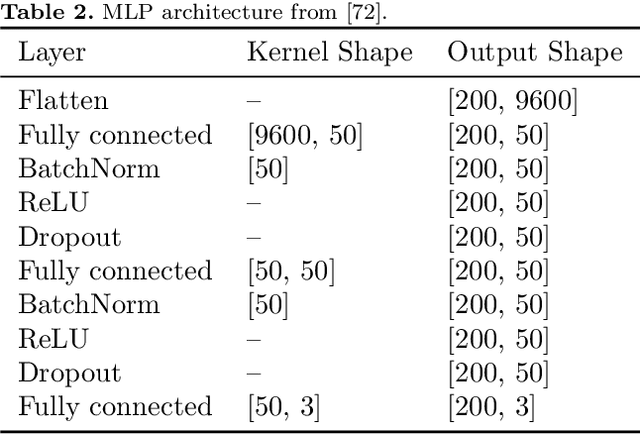
In brain-computer interfaces (BCI) research, recording data is time-consuming and expensive, which limits access to big datasets. This may influence the BCI system performance as machine learning methods depend strongly on the training dataset size. Important questions arise: taking into account neuronal signal characteristics (e.g., non-stationarity), can we achieve higher decoding performance with more data to train decoders? What is the perspective for further improvement with time in the case of long-term BCI studies? In this study, we investigated the impact of long-term recordings on motor imagery decoding from two main perspectives: model requirements regarding dataset size and potential for patient adaptation. We evaluated the multilinear model and two deep learning (DL) models on a long-term BCI and Tetraplegia NCT02550522 clinical trial dataset containing 43 sessions of ECoG recordings performed with a tetraplegic patient. In the experiment, a participant executed 3D virtual hand translation using motor imagery patterns. We designed multiple computational experiments in which training datasets were increased or translated to investigate the relationship between models' performance and different factors influencing recordings. Our analysis showed that adding more data to the training dataset may not instantly increase performance for datasets already containing 40 minutes of the signal. DL decoders showed similar requirements regarding the dataset size compared to the multilinear model while demonstrating higher decoding performance. Moreover, high decoding performance was obtained with relatively small datasets recorded later in the experiment, suggesting motor imagery patterns improvement and patient adaptation. Finally, we proposed UMAP embeddings and local intrinsic dimensionality as a way to visualize the data and potentially evaluate data quality.
Decoding ECoG signal into 3D hand translation using deep learning
Oct 05, 2021


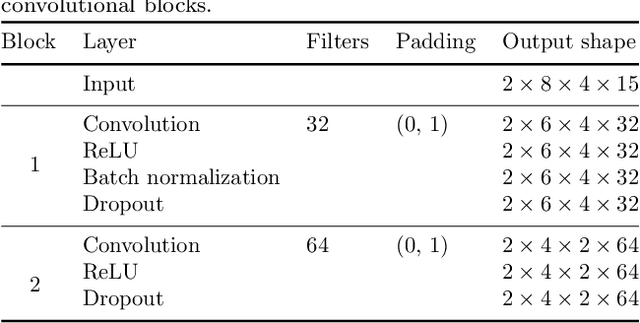
Motor brain-computer interfaces (BCIs) are a promising technology that may enable motor-impaired people to interact with their environment. Designing real-time and accurate BCI is crucial to make such devices useful, safe, and easy to use by patients in a real-life environment. Electrocorticography (ECoG)-based BCIs emerge as a good compromise between invasiveness of the recording device and good spatial and temporal resolution of the recorded signal. However, most ECoG signal decoders used to predict continuous hand movements are linear models. These models have a limited representational capacity and may fail to capture the relationship between ECoG signal and continuous hand movements. Deep learning (DL) models, which are state-of-the-art in many problems, could be a solution to better capture this relationship. In this study, we tested several DL-based architectures to predict imagined 3D continuous hand translation using time-frequency features extracted from ECoG signals. The dataset used in the analysis is a part of a long-term clinical trial (ClinicalTrials.gov identifier: NCT02550522) and was acquired during a closed-loop experiment with a tetraplegic subject. The proposed architectures include multilayer perceptron (MLP), convolutional neural networks (CNN), and long short-term memory networks (LSTM). The accuracy of the DL-based and multilinear models was compared offline using cosine similarity. Our results show that CNN-based architectures outperform the current state-of-the-art multilinear model. The best architecture exploited the spatial correlation between neighboring electrodes with CNN and benefited from the sequential character of the desired hand trajectory by using LSTMs. Overall, DL increased the average cosine similarity, compared to the multilinear model, by up to 60%, from 0.189 to 0.302 and from 0.157 to 0.249 for the left and right hand, respectively.
An exact counterfactual-example-based approach to tree-ensemble models interpretability
May 31, 2021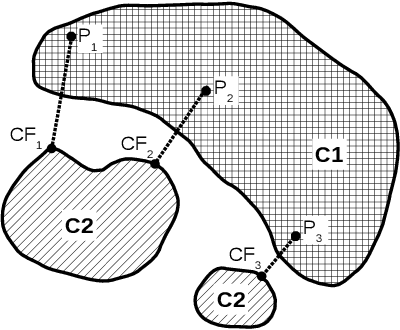
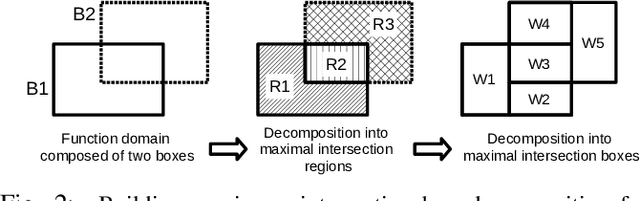
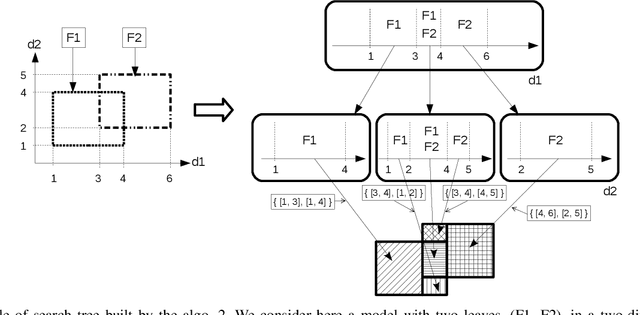
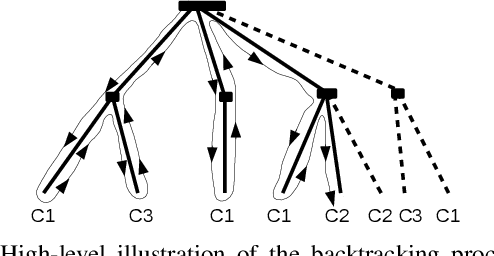
Explaining the decisions of machine learning models is becoming a necessity in many areas where trust in ML models decision is key to their accreditation/adoption. The ability to explain models decisions also allows to provide diagnosis in addition to the model decision, which is highly valuable in scenarios such as fault detection. Unfortunately, high-performance models do not exhibit the necessary transparency to make their decisions fully understandable. And the black-boxes approaches, which are used to explain such model decisions, suffer from a lack of accuracy in tracing back the exact cause of a model decision regarding a given input. Indeed, they do not have the ability to explicitly describe the decision regions of the model around that input, which is necessary to determine what influences the model towards one decision or the other. We thus asked ourselves the question: is there a category of high-performance models among the ones currently used for which we could explicitly and exactly characterise the decision regions in the input feature space using a geometrical characterisation? Surprisingly we came out with a positive answer for any model that enters the category of tree ensemble models, which encompasses a wide range of high-performance models such as XGBoost, LightGBM, random forests ... We could derive an exact geometrical characterisation of their decision regions under the form of a collection of multidimensional intervals. This characterisation makes it straightforward to compute the optimal counterfactual (CF) example associated with a query point. We demonstrate several possibilities of the approach, such as computing the CF example based only on a subset of features. This allows to obtain more plausible explanations by adding prior knowledge about which variables the user can control. An adaptation to CF reasoning on regression problems is also envisaged.