 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Representations for Teacher-Guided Compositional Visual Reasoning
Oct 24, 2023



Neural Module Networks (NMN) are a compelling method for visual question answering, enabling the translation of a question into a program consisting of a series of reasoning sub-tasks that are sequentially executed on the image to produce an answer. NMNs provide enhanced explainability compared to integrated models, allowing for a better understanding of the underlying reasoning process. To improve the effectiveness of NMNs we propose to exploit features obtained by a large-scale cross-modal encoder. Also, the current training approach of NMNs relies on the propagation of module outputs to subsequent modules, leading to the accumulation of prediction errors and the generation of false answers. To mitigate this, we introduce an NMN learning strategy involving scheduled teacher guidance. Initially, the model is fully guided by the ground-truth intermediate outputs, but gradually transitions to an autonomous behavior as training progresses. This reduces error accumulation, thus improving training efficiency and final performance.We demonstrate that by incorporating cross-modal features and employing more effective training techniques for NMN, we achieve a favorable balance between performance and transparency in the reasoning process.
Curriculum Learning for Compositional Visual Reasoning
Mar 27, 2023



Visual Question Answering (VQA) is a complex task requiring large datasets and expensive training. Neural Module Networks (NMN) first translate the question to a reasoning path, then follow that path to analyze the image and provide an answer. We propose an NMN method that relies on predefined cross-modal embeddings to ``warm start'' learning on the GQA dataset, then focus on Curriculum Learning (CL) as a way to improve training and make a better use of the data. Several difficulty criteria are employed for defining CL methods. We show that by an appropriate selection of the CL method the cost of training and the amount of training data can be greatly reduced, with a limited impact on the final VQA accuracy. Furthermore, we introduce intermediate losses during training and find that this allows to simplify the CL strategy.
Why is the prediction wrong? Towards underfitting case explanation via meta-classification
Feb 20, 2023



In this paper we present a heuristic method to provide individual explanations for those elements in a dataset (data points) which are wrongly predicted by a given classifier. Since the general case is too difficult, in the present work we focus on faulty data from an underfitted model. First, we project the faulty data into a hand-crafted, and thus human readable, intermediate representation (meta-representation, profile vectors), with the aim of separating the two main causes of miss-classification: the classifier is not strong enough, or the data point belongs to an area of the input space where classes are not separable. Second, in the space of these profile vectors, we present a method to fit a meta-classifier (decision tree) and express its output as a set of interpretable (human readable) explanation rules, which leads to several target diagnosis labels: data point is either correctly classified, or faulty due to a too weak model, or faulty due to mixed (overlapped) classes in the input space. Experimental results on several real datasets show more than 80% diagnosis label accuracy and confirm that the proposed intermediate representation allows to achieve a high degree of invariance with respect to the classifier used in the input space and to the dataset being classified, i.e. we can learn the metaclassifier on a dataset with a given classifier and successfully predict diagnosis labels for a different dataset or classifier (or both).
Efficient Autoprecoder-based deep learning for massive MU-MIMO Downlink under PA Non-Linearities
Feb 03, 2022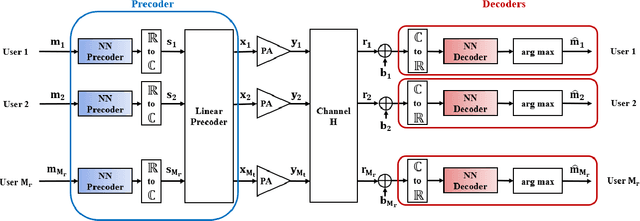

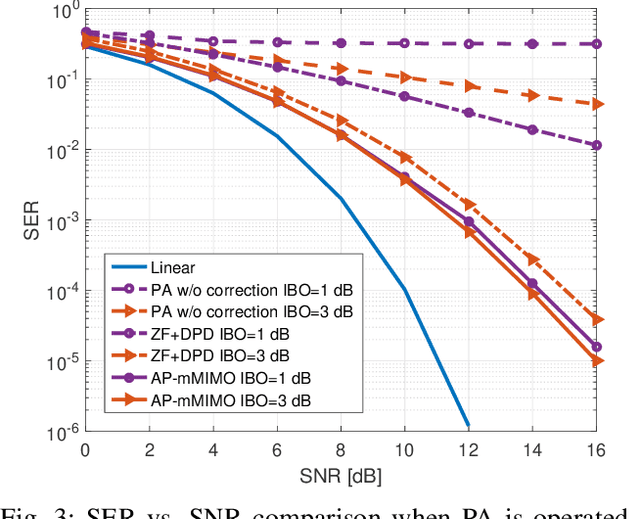
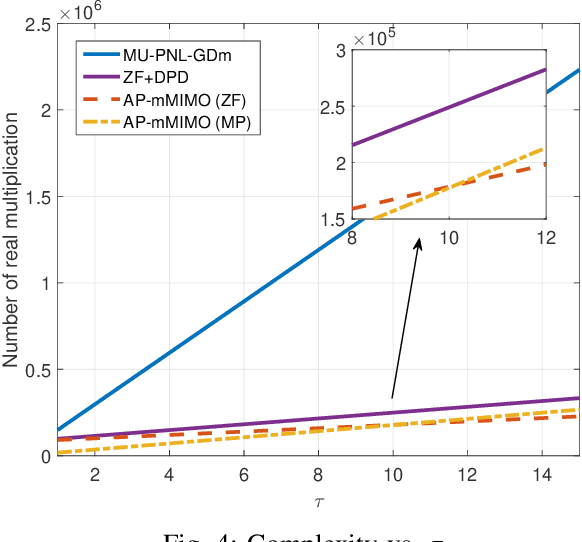
This paper introduces a new efficient autoprecoder (AP) based deep learning approach for massive multiple-input multiple-output (mMIMO) downlink systems in which the base station is equipped with a large number of antennas with energy-efficient power amplifiers (PAs) and serves multiple user terminals. We present AP-mMIMO, a new method that jointly eliminates the multiuser interference and compensates the severe nonlinear (NL) PA distortions. Unlike previous works, AP-mMIMO has a low computational complexity, making it suitable for a global energy-efficient system. Specifically, we aim to design the PA-aware precoder and the receive decoder by leveraging the concept of autoprecoder, whereas the end-to-end massive multiuser (MU)-MIMO downlink is designed using a deep neural network (NN). Most importantly, the proposed AP-mMIMO is suited for the varying block fading channel scenario. To deal with such scenarios, we consider a two-stage precoding scheme: 1) a NN-precoder is used to address the PA non-linearities and 2) a linear precoder is used to suppress the multiuser interference. The NN-precoder and the receive decoder are trained off-line and when the channel varies, only the linear precoder changes on-line. This latter is designed by using the widely used zero-forcing precoding scheme or its lowcomplexity version based on matrix polynomials. Numerical simulations show that the proposed AP-mMIMO approach achieves competitive performance with a significantly lower complexity compared to existing literature. Index Terms-multiuser (MU) precoding, massive multipleinput multiple-output (MIMO), energy-efficiency, hardware impairment, power amplifier (PA) nonlinearities, autoprecoder, deep learning, neural network (NN)
Global Vertices and the Noising Paradox
Aug 02, 2016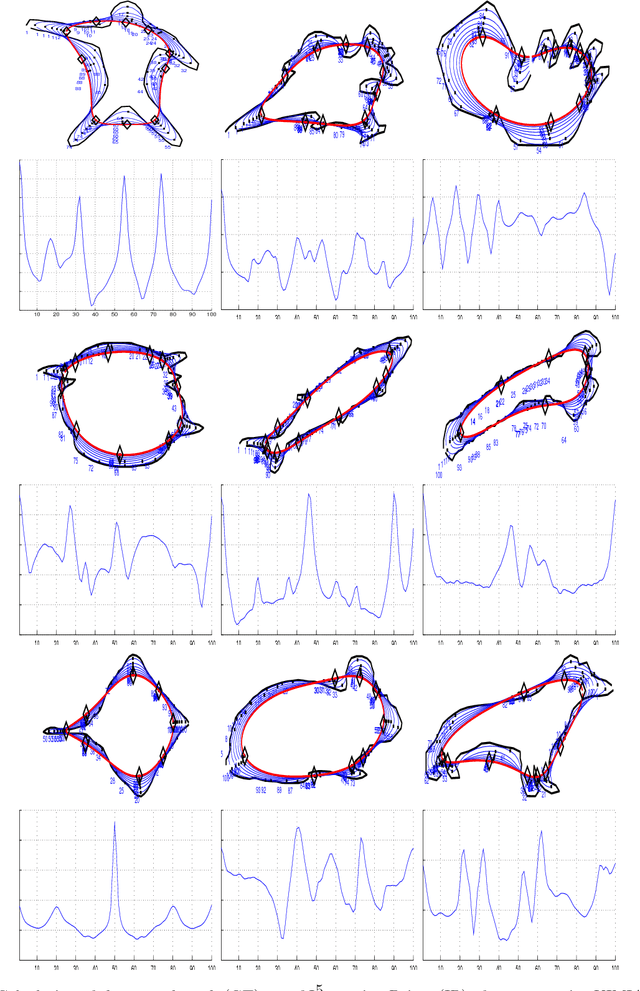
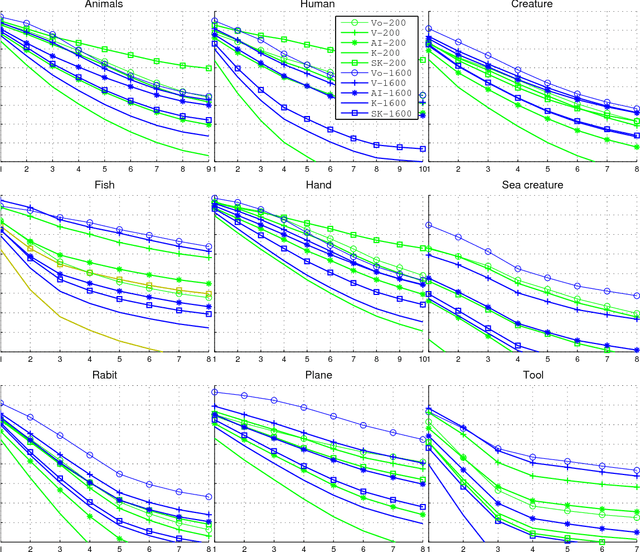

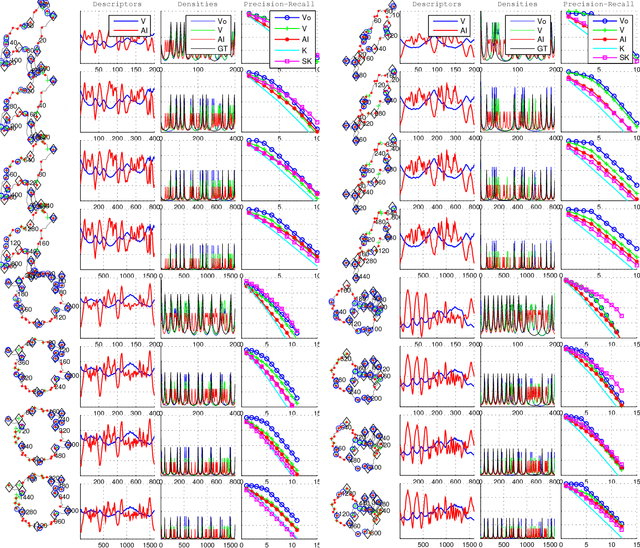
A theoretical and experimental analysis related to the identification of vertices of unknown shapes is presented. Shapes are seen as real functions of their closed boundary. Unlike traditional approaches, which see curvature as the rate of change of the tangent to the curve, an alternative global perspective of curvature is examined providing insight into the process of noise-enabled vertex localization. The analysis leads to a paradox, that certain vertices can be localized better in the presence of noise. The concept of noising is thus considered and a relevant global method for localizing "Global Vertices" is investigated. Theoretical analysis reveals that induced noise can help localizing certain vertices if combined with global descriptors. Experiments with noise and a comparison to localized methods validate the theoretical results.
* 19 pages, 11 figures
Incremental Noising and its Fractal Behavior
Aug 01, 2016This manuscript is about further elucidating the concept of noising. The concept of noising first appeared in \cite{CVPR14}, in the context of curvature estimation and vertex localization on planar shapes. There are indications that noising can play for global methods the role smoothing plays for local methods in this task. This manuscript is about investigating this claim by introducing incremental noising, in a recursive deterministic manner, analogous to how smoothing is extended to progressive smoothing in similar tasks. As investigating the properties and behavior of incremental noising is the purpose of this manuscript, a surprising connection between incremental noising and progressive smoothing is revealed by the experiments. To explain this phenomenon, the fractal and the space filling properties of the two methods respectively, are considered in a unifying context.
* 10 pages, 5 figures