 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Representations for Teacher-Guided Compositional Visual Reasoning
Oct 24, 2023



Neural Module Networks (NMN) are a compelling method for visual question answering, enabling the translation of a question into a program consisting of a series of reasoning sub-tasks that are sequentially executed on the image to produce an answer. NMNs provide enhanced explainability compared to integrated models, allowing for a better understanding of the underlying reasoning process. To improve the effectiveness of NMNs we propose to exploit features obtained by a large-scale cross-modal encoder. Also, the current training approach of NMNs relies on the propagation of module outputs to subsequent modules, leading to the accumulation of prediction errors and the generation of false answers. To mitigate this, we introduce an NMN learning strategy involving scheduled teacher guidance. Initially, the model is fully guided by the ground-truth intermediate outputs, but gradually transitions to an autonomous behavior as training progresses. This reduces error accumulation, thus improving training efficiency and final performance.We demonstrate that by incorporating cross-modal features and employing more effective training techniques for NMN, we achieve a favorable balance between performance and transparency in the reasoning process.
Curriculum Learning for Compositional Visual Reasoning
Mar 27, 2023



Visual Question Answering (VQA) is a complex task requiring large datasets and expensive training. Neural Module Networks (NMN) first translate the question to a reasoning path, then follow that path to analyze the image and provide an answer. We propose an NMN method that relies on predefined cross-modal embeddings to ``warm start'' learning on the GQA dataset, then focus on Curriculum Learning (CL) as a way to improve training and make a better use of the data. Several difficulty criteria are employed for defining CL methods. We show that by an appropriate selection of the CL method the cost of training and the amount of training data can be greatly reduced, with a limited impact on the final VQA accuracy. Furthermore, we introduce intermediate losses during training and find that this allows to simplify the CL strategy.
Why is the prediction wrong? Towards underfitting case explanation via meta-classification
Feb 20, 2023



In this paper we present a heuristic method to provide individual explanations for those elements in a dataset (data points) which are wrongly predicted by a given classifier. Since the general case is too difficult, in the present work we focus on faulty data from an underfitted model. First, we project the faulty data into a hand-crafted, and thus human readable, intermediate representation (meta-representation, profile vectors), with the aim of separating the two main causes of miss-classification: the classifier is not strong enough, or the data point belongs to an area of the input space where classes are not separable. Second, in the space of these profile vectors, we present a method to fit a meta-classifier (decision tree) and express its output as a set of interpretable (human readable) explanation rules, which leads to several target diagnosis labels: data point is either correctly classified, or faulty due to a too weak model, or faulty due to mixed (overlapped) classes in the input space. Experimental results on several real datasets show more than 80% diagnosis label accuracy and confirm that the proposed intermediate representation allows to achieve a high degree of invariance with respect to the classifier used in the input space and to the dataset being classified, i.e. we can learn the metaclassifier on a dataset with a given classifier and successfully predict diagnosis labels for a different dataset or classifier (or both).
Multi-Attribute Balanced Sampling for Disentangled GAN Controls
Oct 28, 2021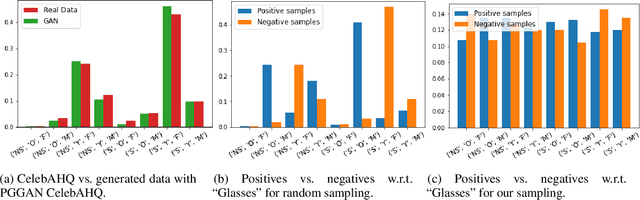
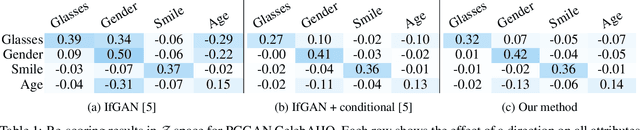
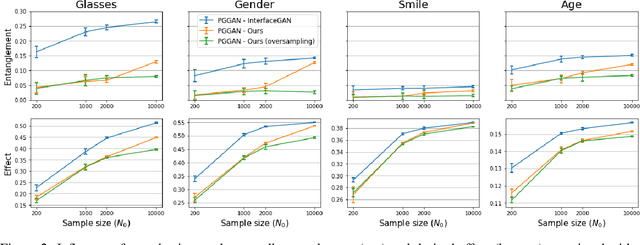
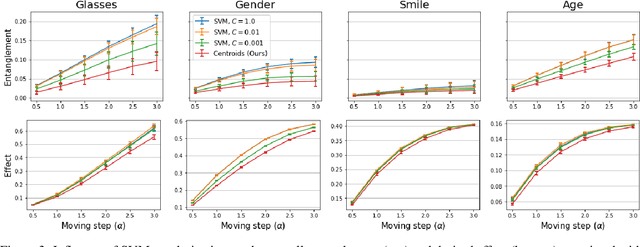
Various controls over the generated data can be extracted from the latent space of a pre-trained GAN, as it implicitly encodes the semantics of the training data. The discovered controls allow to vary semantic attributes in the generated images but usually lead to entangled edits that affect multiple attributes at the same time. Supervised approaches typically sample and annotate a collection of latent codes, then train classifiers in the latent space to identify the controls. Since the data generated by GANs reflects the biases of the original dataset, so do the resulting semantic controls. We propose to address disentanglement by subsampling the generated data to remove over-represented co-occuring attributes thus balancing the semantics of the dataset before training the classifiers. We demonstrate the effectiveness of this approach by extracting disentangled linear directions for face manipulation on two popular GAN architectures, PGGAN and StyleGAN, and two datasets, CelebAHQ and FFHQ. We show that this approach outperforms state-of-the-art classifier-based methods while avoiding the need for disentanglement-enforcing post-processing.
Zero-shot Learning with Deep Neural Networks for Object Recognition
Feb 05, 2021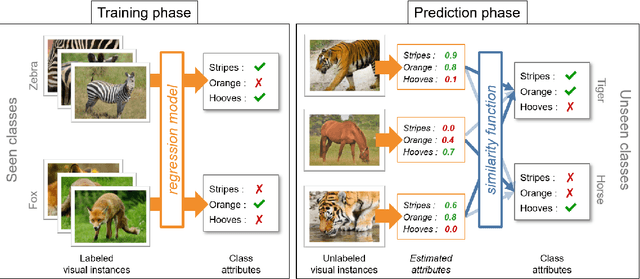

Zero-shot learning deals with the ability to recognize objects without any visual training sample. To counterbalance this lack of visual data, each class to recognize is associated with a semantic prototype that reflects the essential features of the object. The general approach is to learn a mapping from visual data to semantic prototypes, then use it at inference to classify visual samples from the class prototypes only. Different settings of this general configuration can be considered depending on the use case of interest, in particular whether one only wants to classify objects that have not been employed to learn the mapping or whether one can use unlabelled visual examples to learn the mapping. This chapter presents a review of the approaches based on deep neural networks to tackle the ZSL problem. We highlight findings that had a large impact on the evolution of this domain and list its current challenges.
Using Sentences as Semantic Representations in Large Scale Zero-Shot Learning
Oct 06, 2020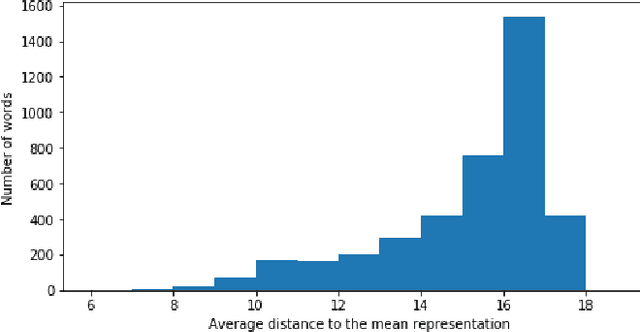



Zero-shot learning aims to recognize instances of unseen classes, for which no visual instance is available during training, by learning multimodal relations between samples from seen classes and corresponding class semantic representations. These class representations usually consist of either attributes, which do not scale well to large datasets, or word embeddings, which lead to poorer performance. A good trade-off could be to employ short sentences in natural language as class descriptions. We explore different solutions to use such short descriptions in a ZSL setting and show that while simple methods cannot achieve very good results with sentences alone, a combination of usual word embeddings and sentences can significantly outperform current state-of-the-art.
From Classical to Generalized Zero-Shot Learning: a Simple Adaptation Process
Sep 26, 2018
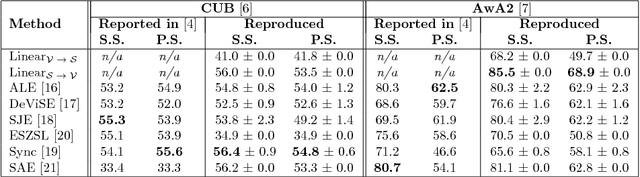
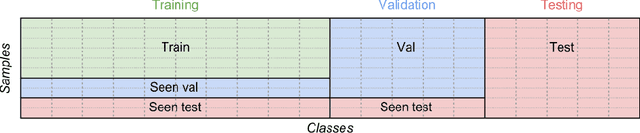
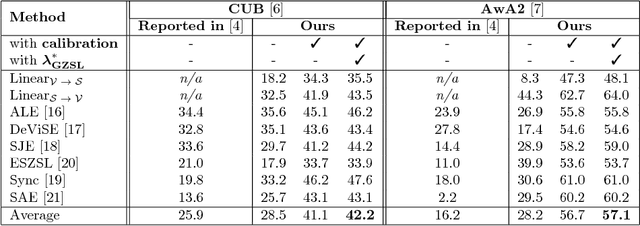
Zero-shot learning (ZSL) is concerned with the recognition of previously unseen classes. It relies on additional semantic knowledge for which a mapping can be learned with training examples of seen classes. While classical ZSL considers the recognition performance on unseen classes only, generalized zero-shot learning (GZSL) aims at maximizing performance on both seen and unseen classes. In this paper, we propose a new process for training and evaluation in the GZSL setting; this process addresses the gap in performance between samples from unseen and seen classes by penalizing the latter, and enables to select hyper-parameters well-suited to the GZSL task. It can be applied to any existing ZSL approach and leads to a significant performance boost: the experimental evaluation shows that GZSL performance, averaged over eight state-of-the-art methods, is improved from 28.5 to 42.2 on CUB and from 28.2 to 57.1 on AwA2.