 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Attribute Balanced Sampling for Disentangled GAN Controls
Paper and Code
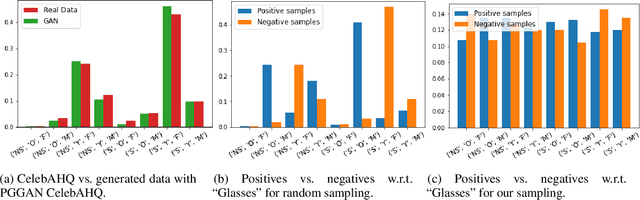
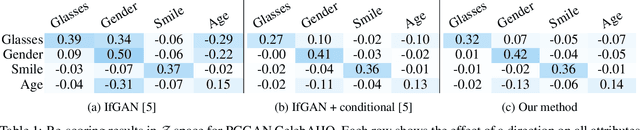
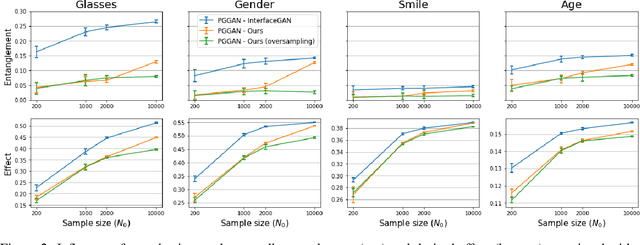
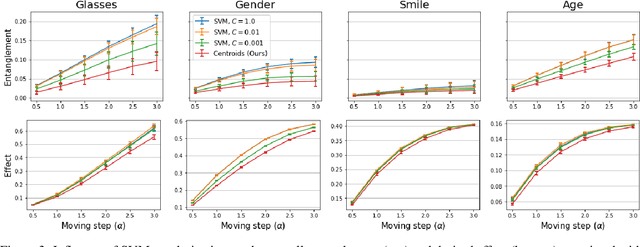
Various controls over the generated data can be extracted from the latent space of a pre-trained GAN, as it implicitly encodes the semantics of the training data. The discovered controls allow to vary semantic attributes in the generated images but usually lead to entangled edits that affect multiple attributes at the same time. Supervised approaches typically sample and annotate a collection of latent codes, then train classifiers in the latent space to identify the controls. Since the data generated by GANs reflects the biases of the original dataset, so do the resulting semantic controls. We propose to address disentanglement by subsampling the generated data to remove over-represented co-occuring attributes thus balancing the semantics of the dataset before training the classifiers. We demonstrate the effectiveness of this approach by extracting disentangled linear directions for face manipulation on two popular GAN architectures, PGGAN and StyleGAN, and two datasets, CelebAHQ and FFHQ. We show that this approach outperforms state-of-the-art classifier-based methods while avoiding the need for disentanglement-enforcing post-processing.