 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Classical to Generalized Zero-Shot Learning: a Simple Adaptation Process
Paper and Code
Sep 26, 2018
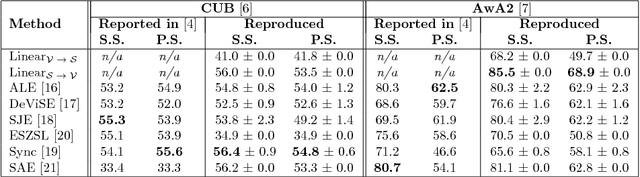
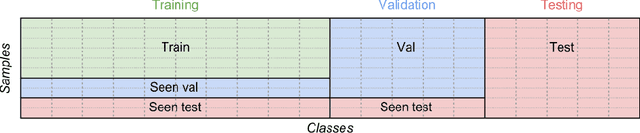
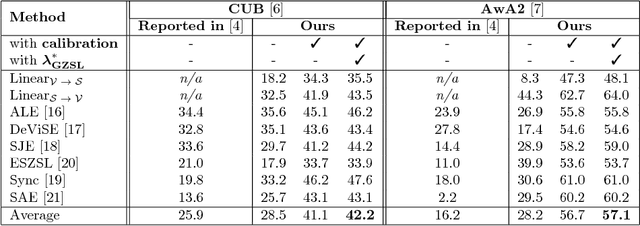
Zero-shot learning (ZSL) is concerned with the recognition of previously unseen classes. It relies on additional semantic knowledge for which a mapping can be learned with training examples of seen classes. While classical ZSL considers the recognition performance on unseen classes only, generalized zero-shot learning (GZSL) aims at maximizing performance on both seen and unseen classes. In this paper, we propose a new process for training and evaluation in the GZSL setting; this process addresses the gap in performance between samples from unseen and seen classes by penalizing the latter, and enables to select hyper-parameters well-suited to the GZSL task. It can be applied to any existing ZSL approach and leads to a significant performance boost: the experimental evaluation shows that GZSL performance, averaged over eight state-of-the-art methods, is improved from 28.5 to 42.2 on CUB and from 28.2 to 57.1 on AwA2.