 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot Learning with Deep Neural Networks for Object Recognition
Feb 05, 2021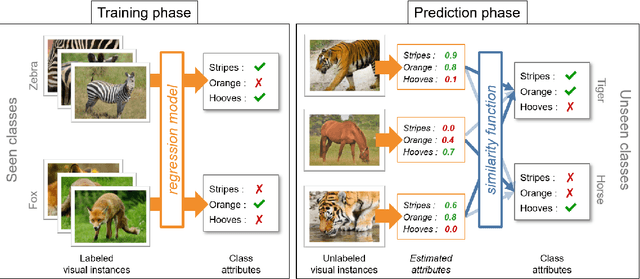

Zero-shot learning deals with the ability to recognize objects without any visual training sample. To counterbalance this lack of visual data, each class to recognize is associated with a semantic prototype that reflects the essential features of the object. The general approach is to learn a mapping from visual data to semantic prototypes, then use it at inference to classify visual samples from the class prototypes only. Different settings of this general configuration can be considered depending on the use case of interest, in particular whether one only wants to classify objects that have not been employed to learn the mapping or whether one can use unlabelled visual examples to learn the mapping. This chapter presents a review of the approaches based on deep neural networks to tackle the ZSL problem. We highlight findings that had a large impact on the evolution of this domain and list its current challenges.
Using Sentences as Semantic Representations in Large Scale Zero-Shot Learning
Oct 06, 2020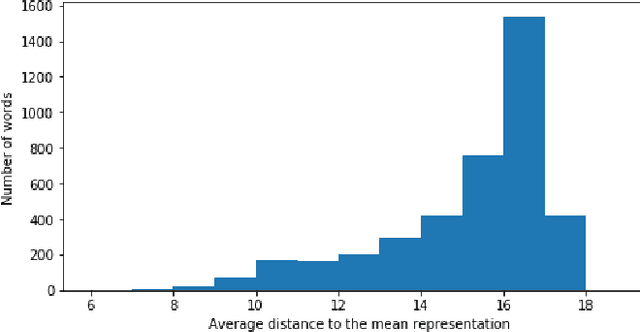



Zero-shot learning aims to recognize instances of unseen classes, for which no visual instance is available during training, by learning multimodal relations between samples from seen classes and corresponding class semantic representations. These class representations usually consist of either attributes, which do not scale well to large datasets, or word embeddings, which lead to poorer performance. A good trade-off could be to employ short sentences in natural language as class descriptions. We explore different solutions to use such short descriptions in a ZSL setting and show that while simple methods cannot achieve very good results with sentences alone, a combination of usual word embeddings and sentences can significantly outperform current state-of-the-art.
Webly Supervised Semantic Embeddings for Large Scale Zero-Shot Learning
Aug 06, 2020
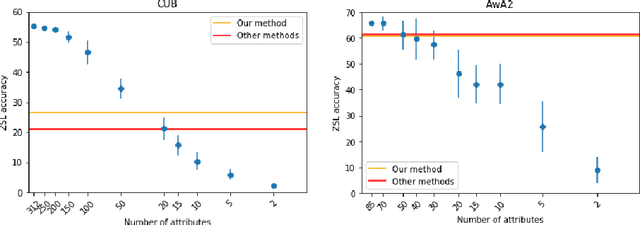

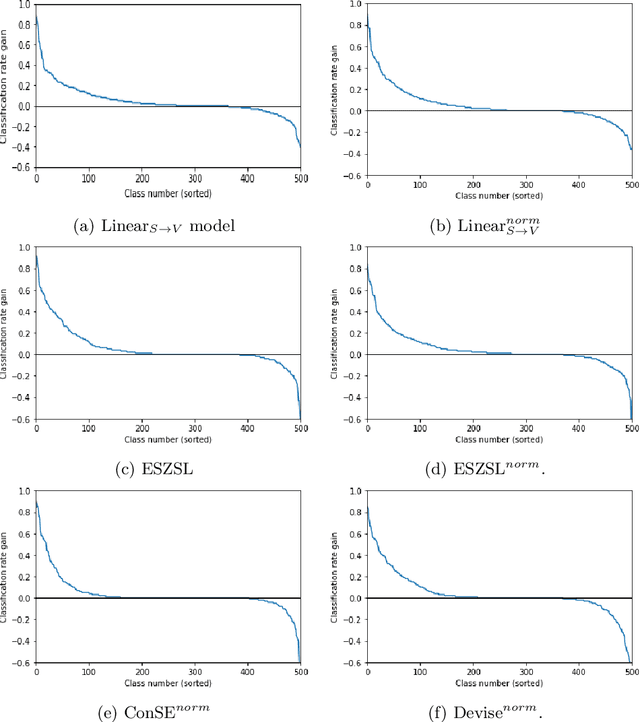
Zero-shot learning (ZSL) makes object recognition in images possible in absence of visual training data for a part of the classes from a dataset. When the number of classes is large, classes are usually represented by semantic class prototypes learned automatically from unannotated text collections. This typically leads to much lower performances than with manually designed semantic prototypes such as attributes. While most ZSL works focus on the visual aspect and reuse standard semantic prototypes learned from generic text collections, we focus on the problem of semantic class prototype design for large scale ZSL. More specifically, we investigate the use of noisy textual metadata associated to photos as text collections, as we hypothesize they are likely to provide more plausible semantic embeddings for visual classes if exploited appropriately. We thus make use of a source-based voting strategy to improve the robustness of semantic prototypes. Evaluation on the large scale ImageNet dataset shows a significant improvement in ZSL performances over two strong baselines, and over usual semantic embeddings used in previous works. We show that this improvement is obtained for several embedding methods, leading to state of the art results when one uses automatically created visual and text features.
From Classical to Generalized Zero-Shot Learning: a Simple Adaptation Process
Sep 26, 2018
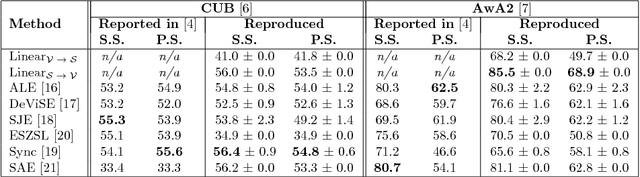
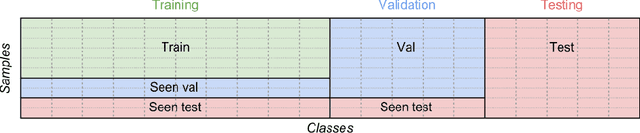
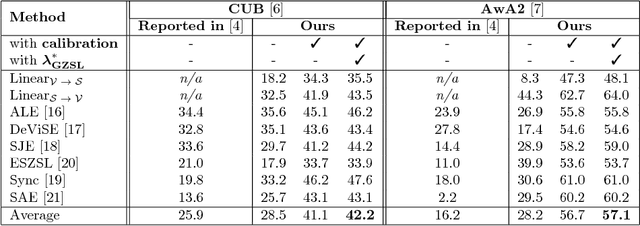
Zero-shot learning (ZSL) is concerned with the recognition of previously unseen classes. It relies on additional semantic knowledge for which a mapping can be learned with training examples of seen classes. While classical ZSL considers the recognition performance on unseen classes only, generalized zero-shot learning (GZSL) aims at maximizing performance on both seen and unseen classes. In this paper, we propose a new process for training and evaluation in the GZSL setting; this process addresses the gap in performance between samples from unseen and seen classes by penalizing the latter, and enables to select hyper-parameters well-suited to the GZSL task. It can be applied to any existing ZSL approach and leads to a significant performance boost: the experimental evaluation shows that GZSL performance, averaged over eight state-of-the-art methods, is improved from 28.5 to 42.2 on CUB and from 28.2 to 57.1 on AwA2.