 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWebly Supervised Semantic Embeddings for Large Scale Zero-Shot Learning
Paper and Code

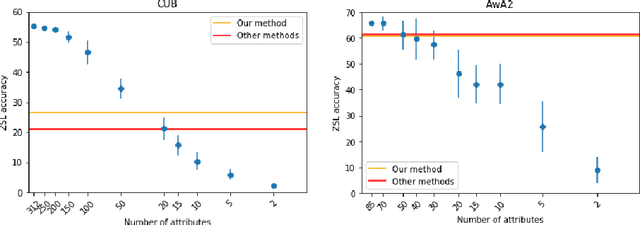

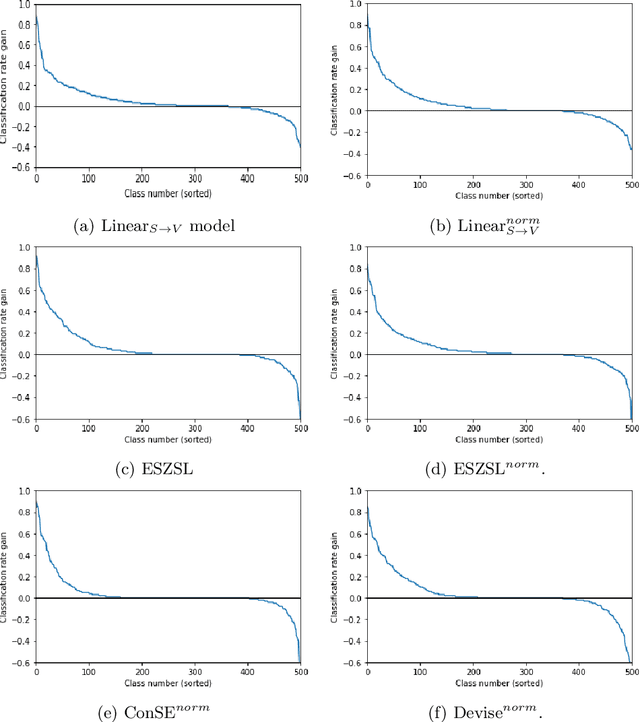
Zero-shot learning (ZSL) makes object recognition in images possible in absence of visual training data for a part of the classes from a dataset. When the number of classes is large, classes are usually represented by semantic class prototypes learned automatically from unannotated text collections. This typically leads to much lower performances than with manually designed semantic prototypes such as attributes. While most ZSL works focus on the visual aspect and reuse standard semantic prototypes learned from generic text collections, we focus on the problem of semantic class prototype design for large scale ZSL. More specifically, we investigate the use of noisy textual metadata associated to photos as text collections, as we hypothesize they are likely to provide more plausible semantic embeddings for visual classes if exploited appropriately. We thus make use of a source-based voting strategy to improve the robustness of semantic prototypes. Evaluation on the large scale ImageNet dataset shows a significant improvement in ZSL performances over two strong baselines, and over usual semantic embeddings used in previous works. We show that this improvement is obtained for several embedding methods, leading to state of the art results when one uses automatically created visual and text features.