 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Representations for Teacher-Guided Compositional Visual Reasoning
Oct 24, 2023



Neural Module Networks (NMN) are a compelling method for visual question answering, enabling the translation of a question into a program consisting of a series of reasoning sub-tasks that are sequentially executed on the image to produce an answer. NMNs provide enhanced explainability compared to integrated models, allowing for a better understanding of the underlying reasoning process. To improve the effectiveness of NMNs we propose to exploit features obtained by a large-scale cross-modal encoder. Also, the current training approach of NMNs relies on the propagation of module outputs to subsequent modules, leading to the accumulation of prediction errors and the generation of false answers. To mitigate this, we introduce an NMN learning strategy involving scheduled teacher guidance. Initially, the model is fully guided by the ground-truth intermediate outputs, but gradually transitions to an autonomous behavior as training progresses. This reduces error accumulation, thus improving training efficiency and final performance.We demonstrate that by incorporating cross-modal features and employing more effective training techniques for NMN, we achieve a favorable balance between performance and transparency in the reasoning process.
Curriculum Learning for Compositional Visual Reasoning
Mar 27, 2023



Visual Question Answering (VQA) is a complex task requiring large datasets and expensive training. Neural Module Networks (NMN) first translate the question to a reasoning path, then follow that path to analyze the image and provide an answer. We propose an NMN method that relies on predefined cross-modal embeddings to ``warm start'' learning on the GQA dataset, then focus on Curriculum Learning (CL) as a way to improve training and make a better use of the data. Several difficulty criteria are employed for defining CL methods. We show that by an appropriate selection of the CL method the cost of training and the amount of training data can be greatly reduced, with a limited impact on the final VQA accuracy. Furthermore, we introduce intermediate losses during training and find that this allows to simplify the CL strategy.
A Reinforcement Learning-driven Translation Model for Search-Oriented Conversational Systems
Aug 29, 2018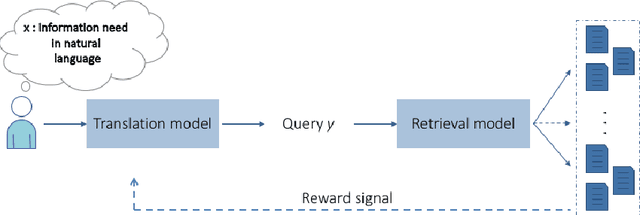

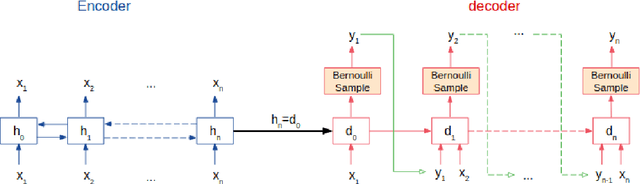
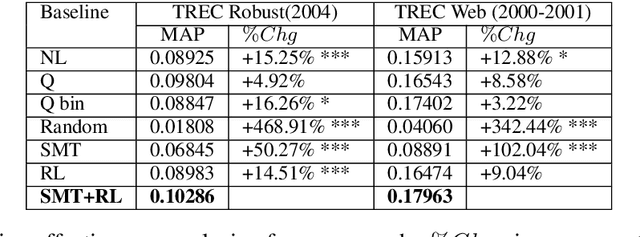
Search-oriented conversational systems rely on information needs expressed in natural language (NL). We focus here on the understanding of NL expressions for building keyword-based queries. We propose a reinforcement-learning-driven translation model framework able to 1) learn the translation from NL expressions to queries in a supervised way, and, 2) to overcome the lack of large-scale dataset by framing the translation model as a word selection approach and injecting relevance feedback in the learning process. Experiments are carried out on two TREC datasets and outline the effectiveness of our approach.