 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverse Weight Averaging for Out-of-Distribution Generalization
Paper and Code
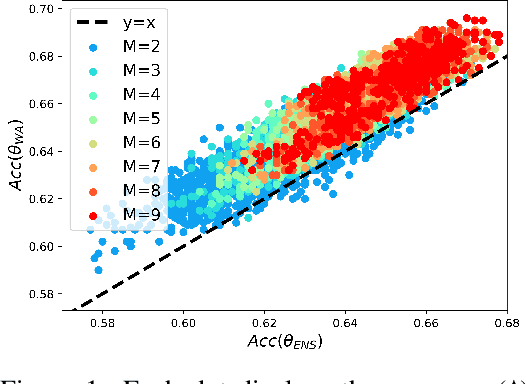



Standard neural networks struggle to generalize under distribution shifts. For out-of-distribution generalization in computer vision, the best current approach averages the weights along a training run. In this paper, we propose Diverse Weight Averaging (DiWA) that makes a simple change to this strategy: DiWA averages the weights obtained from several independent training runs rather than from a single run. Perhaps surprisingly, averaging these weights performs well under soft constraints despite the network's nonlinearities. The main motivation behind DiWA is to increase the functional diversity across averaged models. Indeed, models obtained from different runs are more diverse than those collected along a single run thanks to differences in hyperparameters and training procedures. We motivate the need for diversity by a new bias-variance-covariance-locality decomposition of the expected error, exploiting similarities between DiWA and standard functional ensembling. Moreover, this decomposition highlights that DiWA succeeds when the variance term dominates, which we show happens when the marginal distribution changes at test time. Experimentally, DiWA consistently improves the state of the art on the competitive DomainBed benchmark without inference overhead.