 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA pragmatic policy learning approach to account for users' fatigue in repeated auctions
Jul 15, 2024Online advertising banners are sold in real-time through auctions.Typically, the more banners a user is shown, the smaller the marginalvalue of the next banner for this user is. This fact can be detected bybasic ML models, that can be used to predict how previously won auctionsdecrease the current opportunity value. However, learning is not enough toproduce a bid that correctly accounts for how winning the current auctionimpacts the future values. Indeed, a policy that uses this prediction tomaximize the expected payoff of the current auction could be dubbedimpatient because such policy does not fully account for the repeatednature of the auctions. Under this perspective, it seems that most biddersin the literature are impatient. Unsurprisingly, impatience induces a cost.We provide two empirical arguments for the importance of this cost ofimpatience. First, an offline counterfactual analysis and, second, a notablebusiness metrics improvement by mitigating the cost of impatience withpolicy learning
Learning from aggregated data with a maximum entropy model
Oct 05, 2022

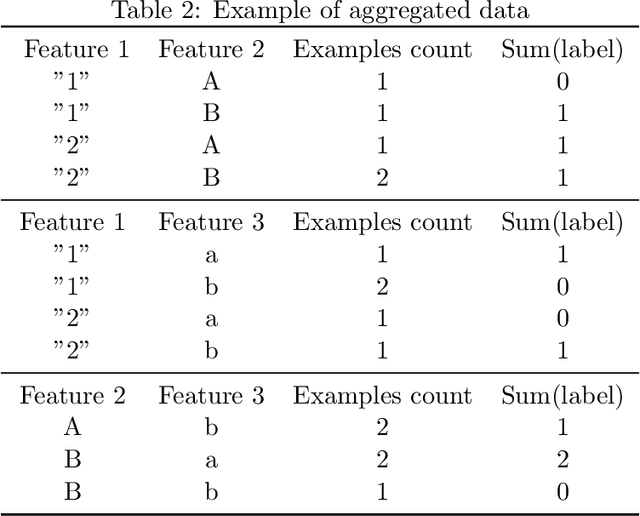
Aggregating a dataset, then injecting some noise, is a simple and common way to release differentially private data.However, aggregated data -- even without noise -- is not an appropriate input for machine learning classifiers.In this work, we show how a new model, similar to a logistic regression, may be learned from aggregated data only by approximating the unobserved feature distribution with a maximum entropy hypothesis. The resulting model is a Markov Random Field (MRF), and we detail how to apply, modify and scale a MRF training algorithm to our setting. Finally we present empirical evidence on several public datasets that the model learned this way can achieve performances comparable to those of a logistic model trained with the full unaggregated data.
Fast Offline Policy Optimization for Large Scale Recommendation
Aug 11, 2022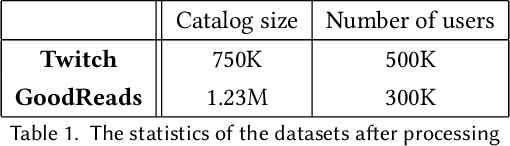
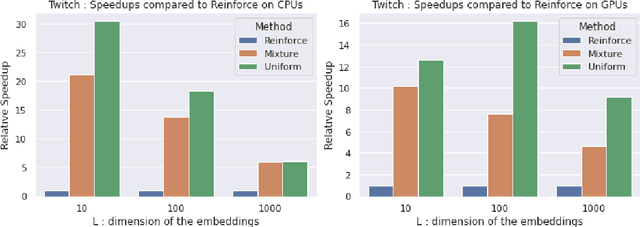
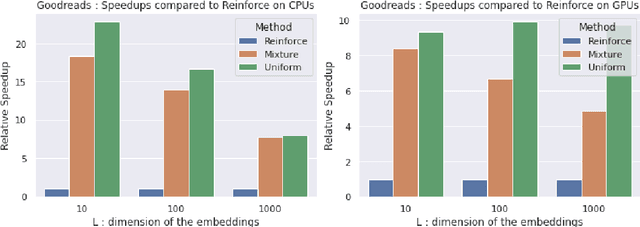
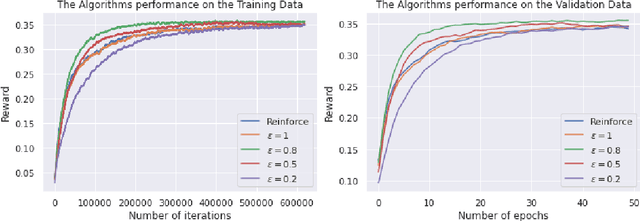
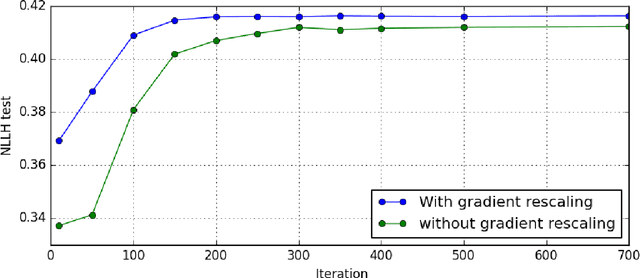
Personalised interactive systems such as recommender systems require selecting relevant items dependent on context. Production systems need to identify the items rapidly from very large catalogues which can be efficiently solved using maximum inner product search technology. Offline optimisation of maximum inner product search can be achieved by a relaxation of the discrete problem resulting in policy learning or reinforce style learning algorithms. Unfortunately this relaxation step requires computing a sum over the entire catalogue making the complexity of the evaluation of the gradient (and hence each stochastic gradient descent iterations) linear in the catalogue size. This calculation is untenable in many real world examples such as large catalogue recommender systems severely limiting the usefulness of this method in practice. In this paper we show how it is possible to produce an excellent approximation of these policy learning algorithms that scale logarithmically with the catalogue size. Our contribution is based upon combining three novel ideas: a new Monte Carlo estimate of the gradient of a policy, the self normalised importance sampling estimator and the use of fast maximum inner product search at training time. Extensive experiments show our algorithm is an order of magnitude faster than naive approaches yet produces equally good policies.
Lessons from the AdKDD'21 Privacy-Preserving ML Challenge
Jan 31, 2022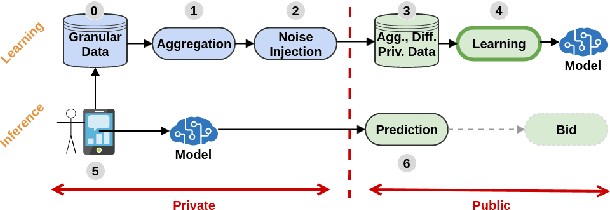
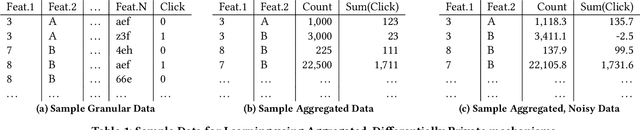
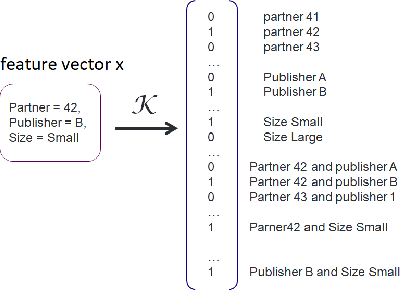
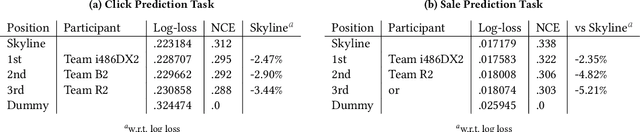
Designing data sharing mechanisms providing performance and strong privacy guarantees is a hot topic for the Online Advertising industry. Namely, a prominent proposal discussed under the Improving Web Advertising Business Group at W3C only allows sharing advertising signals through aggregated, differentially private reports of past displays. To study this proposal extensively, an open Privacy-Preserving Machine Learning Challenge took place at AdKDD'21, a premier workshop on Advertising Science with data provided by advertising company Criteo. In this paper, we describe the challenge tasks, the structure of the available datasets, report the challenge results, and enable its full reproducibility. A key finding is that learning models on large, aggregated data in the presence of a small set of unaggregated data points can be surprisingly efficient and cheap. We also run additional experiments to observe the sensitivity of winning methods to different parameters such as privacy budget or quantity of available privileged side information. We conclude that the industry needs either alternate designs for private data sharing or a breakthrough in learning with aggregated data only to keep ad relevance at a reasonable level.
Learning from Bandit Feedback: An Overview of the State-of-the-art
Sep 18, 2019
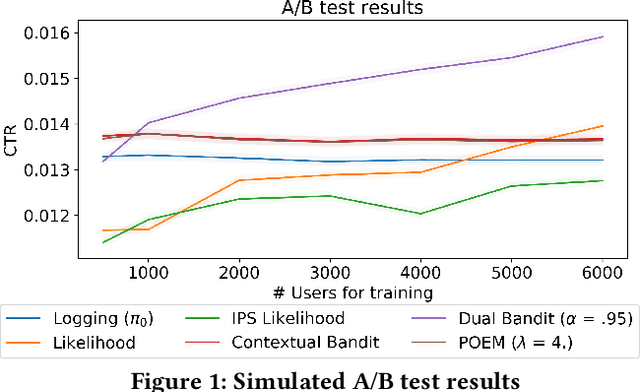
In machine learning we often try to optimise a decision rule that would have worked well over a historical dataset; this is the so called empirical risk minimisation principle. In the context of learning from recommender system logs, applying this principle becomes a problem because we do not have available the reward of decisions we did not do. In order to handle this "bandit-feedback" setting, several Counterfactual Risk Minimisation (CRM) methods have been proposed in recent years, that attempt to estimate the performance of different policies on historical data. Through importance sampling and various variance reduction techniques, these methods allow more robust learning and inference than classical approaches. It is difficult to accurately estimate the performance of policies that frequently perform actions that were infrequently done in the past and a number of different types of estimators have been proposed. In this paper, we review several methods, based on different off-policy estimators, for learning from bandit feedback. We discuss key differences and commonalities among existing approaches, and compare their empirical performance on the RecoGym simulation environment. To the best of our knowledge, this work is the first comparison study for bandit algorithms in a recommender system setting.
Ranking metrics on non-shuffled traffic
Sep 17, 2019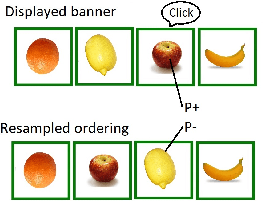
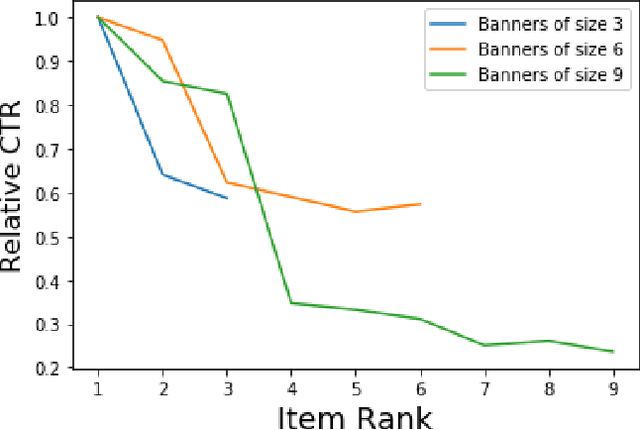
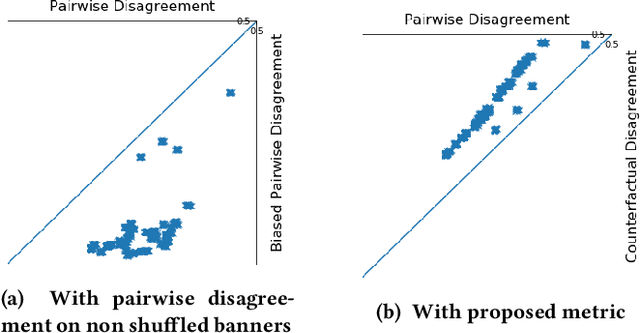
Ranking metrics are a family of metrics largely used to evaluate recommender systems. However they typically suffer from the fact the reward is affected by the order in which recommended items are displayed to the user. A classical way to overcome this position bias is to uniformly shuffle a proportion of the recommendations, but this method may result in a bad user experience. It is nevertheless common to use a stochastic policy to generate the recommendations, and we suggest a new method to overcome the position bias, by leveraging the stochasticity of the policy used to collect the dataset.
Offline A/B testing for Recommender Systems
Jan 22, 2018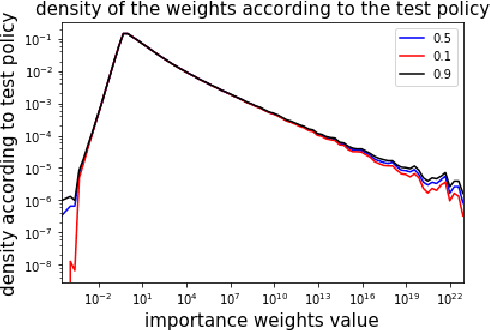

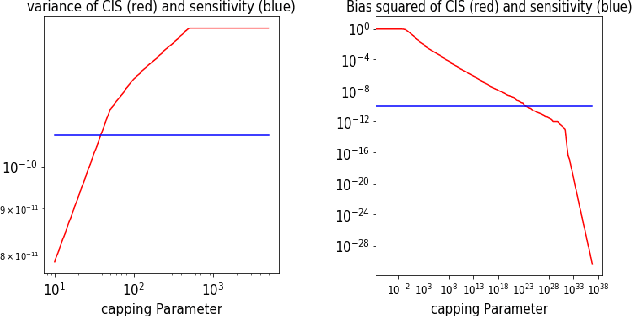

Before A/B testing online a new version of a recommender system, it is usual to perform some offline evaluations on historical data. We focus on evaluation methods that compute an estimator of the potential uplift in revenue that could generate this new technology. It helps to iterate faster and to avoid losing money by detecting poor policies. These estimators are known as counterfactual or off-policy estimators. We show that traditional counterfactual estimators such as capped importance sampling and normalised importance sampling are experimentally not having satisfying bias-variance compromises in the context of personalised product recommendation for online advertising. We propose two variants of counterfactual estimates with different modelling of the bias that prove to be accurate in real-world conditions. We provide a benchmark of these estimators by showing their correlation with business metrics observed by running online A/B tests on a commercial recommender system.