 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Armed Bandits with Minimum Aggregated Revenue Constraints
Oct 14, 2025We examine a multi-armed bandit problem with contextual information, where the objective is to ensure that each arm receives a minimum aggregated reward across contexts while simultaneously maximizing the total cumulative reward. This framework captures a broad class of real-world applications where fair revenue allocation is critical and contextual variation is inherent. The cross-context aggregation of minimum reward constraints, while enabling better performance and easier feasibility, introduces significant technical challenges -- particularly the absence of closed-form optimal allocations typically available in standard MAB settings. We design and analyze algorithms that either optimistically prioritize performance or pessimistically enforce constraint satisfaction. For each algorithm, we derive problem-dependent upper bounds on both regret and constraint violations. Furthermore, we establish a lower bound demonstrating that the dependence on the time horizon in our results is optimal in general and revealing fundamental limitations of the free exploration principle leveraged in prior work.
Strategic Multi-Armed Bandit Problems Under Debt-Free Reporting
Jan 27, 2025


We consider the classical multi-armed bandit problem, but with strategic arms. In this context, each arm is characterized by a bounded support reward distribution and strategically aims to maximize its own utility by potentially retaining a portion of its reward, and disclosing only a fraction of it to the learning agent. This scenario unfolds as a game over $T$ rounds, leading to a competition of objectives between the learning agent, aiming to minimize their regret, and the arms, motivated by the desire to maximize their individual utilities. To address these dynamics, we introduce a new mechanism that establishes an equilibrium wherein each arm behaves truthfully and discloses as much of its rewards as possible. With this mechanism, the agent can attain the second-highest average (true) reward among arms, with a cumulative regret bounded by $O(\log(T)/\Delta)$ (problem-dependent) or $O(\sqrt{T\log(T)})$ (worst-case).
Strategic Arms with Side Communication Prevail Over Low-Regret MAB Algorithms
Aug 30, 2024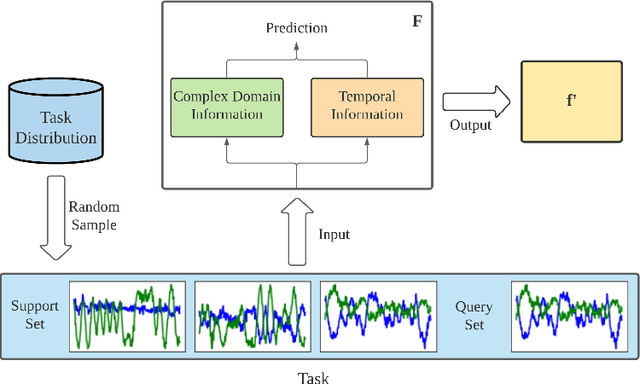
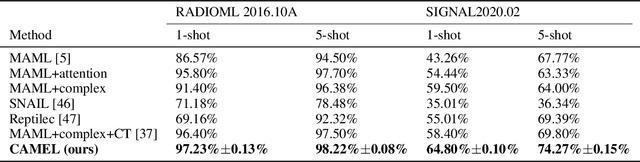

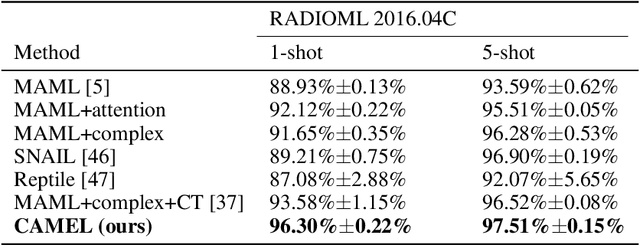
In the strategic multi-armed bandit setting, when arms possess perfect information about the player's behavior, they can establish an equilibrium where: 1. they retain almost all of their value, 2. they leave the player with a substantial (linear) regret. This study illustrates that, even if complete information is not publicly available to all arms but is shared among them, it is possible to achieve a similar equilibrium. The primary challenge lies in designing a communication protocol that incentivizes the arms to communicate truthfully.
Learning from aggregated data with a maximum entropy model
Oct 05, 2022

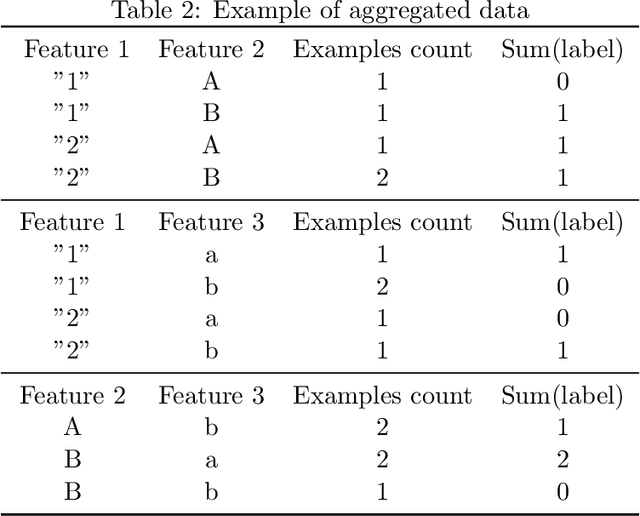
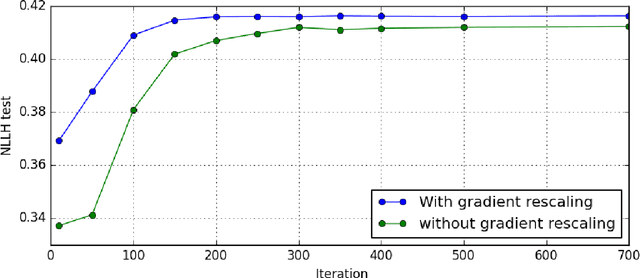
Aggregating a dataset, then injecting some noise, is a simple and common way to release differentially private data.However, aggregated data -- even without noise -- is not an appropriate input for machine learning classifiers.In this work, we show how a new model, similar to a logistic regression, may be learned from aggregated data only by approximating the unobserved feature distribution with a maximum entropy hypothesis. The resulting model is a Markov Random Field (MRF), and we detail how to apply, modify and scale a MRF training algorithm to our setting. Finally we present empirical evidence on several public datasets that the model learned this way can achieve performances comparable to those of a logistic model trained with the full unaggregated data.