 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLessons from the AdKDD'21 Privacy-Preserving ML Challenge
Paper and Code
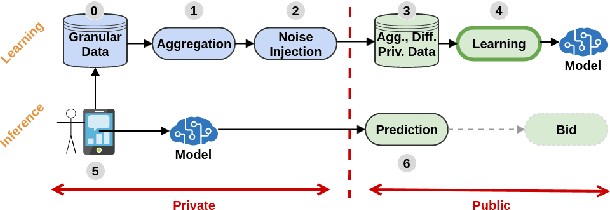
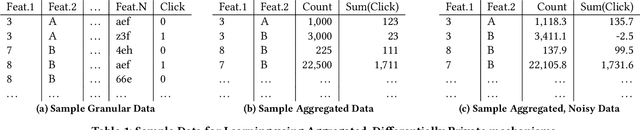
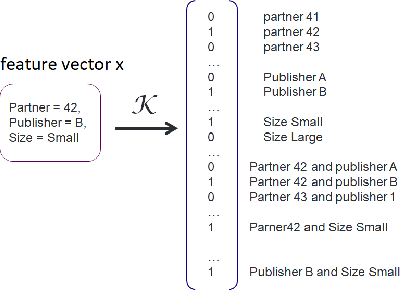
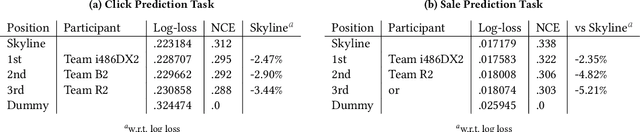
Designing data sharing mechanisms providing performance and strong privacy guarantees is a hot topic for the Online Advertising industry. Namely, a prominent proposal discussed under the Improving Web Advertising Business Group at W3C only allows sharing advertising signals through aggregated, differentially private reports of past displays. To study this proposal extensively, an open Privacy-Preserving Machine Learning Challenge took place at AdKDD'21, a premier workshop on Advertising Science with data provided by advertising company Criteo. In this paper, we describe the challenge tasks, the structure of the available datasets, report the challenge results, and enable its full reproducibility. A key finding is that learning models on large, aggregated data in the presence of a small set of unaggregated data points can be surprisingly efficient and cheap. We also run additional experiments to observe the sensitivity of winning methods to different parameters such as privacy budget or quantity of available privileged side information. We conclude that the industry needs either alternate designs for private data sharing or a breakthrough in learning with aggregated data only to keep ad relevance at a reasonable level.