 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Offline Policy Optimization for Large Scale Recommendation
Paper and Code
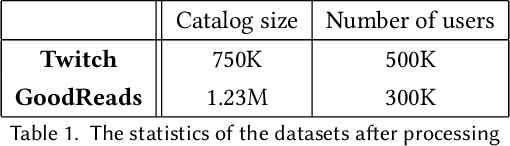
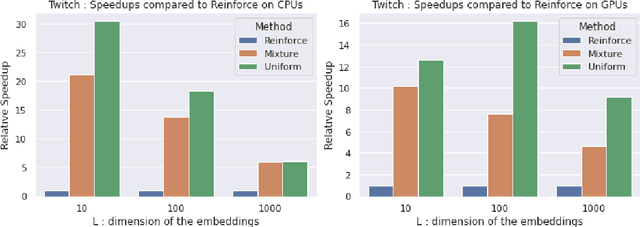
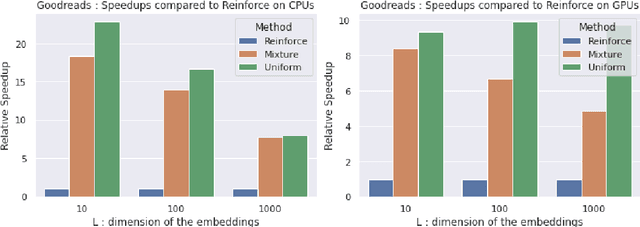
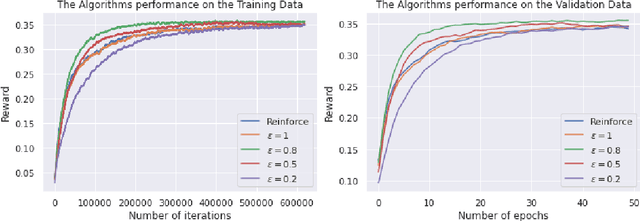
Personalised interactive systems such as recommender systems require selecting relevant items dependent on context. Production systems need to identify the items rapidly from very large catalogues which can be efficiently solved using maximum inner product search technology. Offline optimisation of maximum inner product search can be achieved by a relaxation of the discrete problem resulting in policy learning or reinforce style learning algorithms. Unfortunately this relaxation step requires computing a sum over the entire catalogue making the complexity of the evaluation of the gradient (and hence each stochastic gradient descent iterations) linear in the catalogue size. This calculation is untenable in many real world examples such as large catalogue recommender systems severely limiting the usefulness of this method in practice. In this paper we show how it is possible to produce an excellent approximation of these policy learning algorithms that scale logarithmically with the catalogue size. Our contribution is based upon combining three novel ideas: a new Monte Carlo estimate of the gradient of a policy, the self normalised importance sampling estimator and the use of fast maximum inner product search at training time. Extensive experiments show our algorithm is an order of magnitude faster than naive approaches yet produces equally good policies.