 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline Evaluation of Reward-Optimizing Recommender Systems: The Case of Simulation
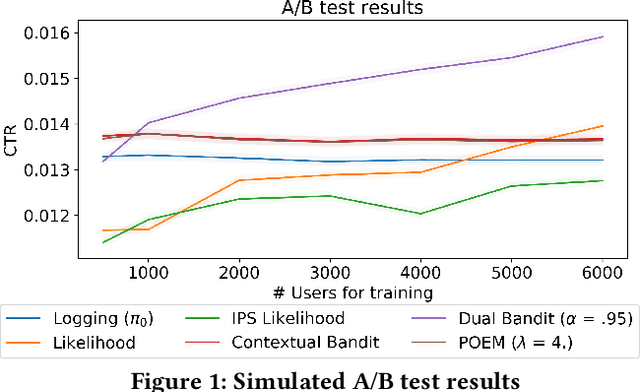
Sep 18, 2022Both in academic and industry-based research, online evaluation methods are seen as the golden standard for interactive applications like recommendation systems. Naturally, the reason for this is that we can directly measure utility metrics that rely on interventions, being the recommendations that are being shown to users. Nevertheless, online evaluation methods are costly for a number of reasons, and a clear need remains for reliable offline evaluation procedures. In industry, offline metrics are often used as a first-line evaluation to generate promising candidate models to evaluate online. In academic work, limited access to online systems makes offline metrics the de facto approach to validating novel methods. Two classes of offline metrics exist: proxy-based methods, and counterfactual methods. The first class is often poorly correlated with the online metrics we care about, and the latter class only provides theoretical guarantees under assumptions that cannot be fulfilled in real-world environments. Here, we make the case that simulation-based comparisons provide ways forward beyond offline metrics, and argue that they are a preferable means of evaluation.
Learning from Bandit Feedback: An Overview of the State-of-the-art
Sep 18, 2019
In machine learning we often try to optimise a decision rule that would have worked well over a historical dataset; this is the so called empirical risk minimisation principle. In the context of learning from recommender system logs, applying this principle becomes a problem because we do not have available the reward of decisions we did not do. In order to handle this "bandit-feedback" setting, several Counterfactual Risk Minimisation (CRM) methods have been proposed in recent years, that attempt to estimate the performance of different policies on historical data. Through importance sampling and various variance reduction techniques, these methods allow more robust learning and inference than classical approaches. It is difficult to accurately estimate the performance of policies that frequently perform actions that were infrequently done in the past and a number of different types of estimators have been proposed. In this paper, we review several methods, based on different off-policy estimators, for learning from bandit feedback. We discuss key differences and commonalities among existing approaches, and compare their empirical performance on the RecoGym simulation environment. To the best of our knowledge, this work is the first comparison study for bandit algorithms in a recommender system setting.
Dual optimization for convex constrained objectives without the gradient-Lipschitz assumption
Jul 10, 2018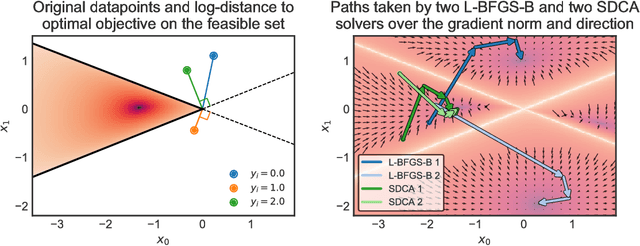
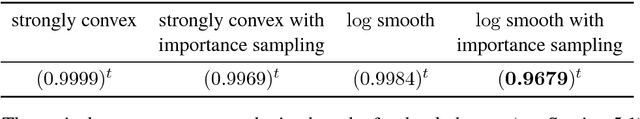
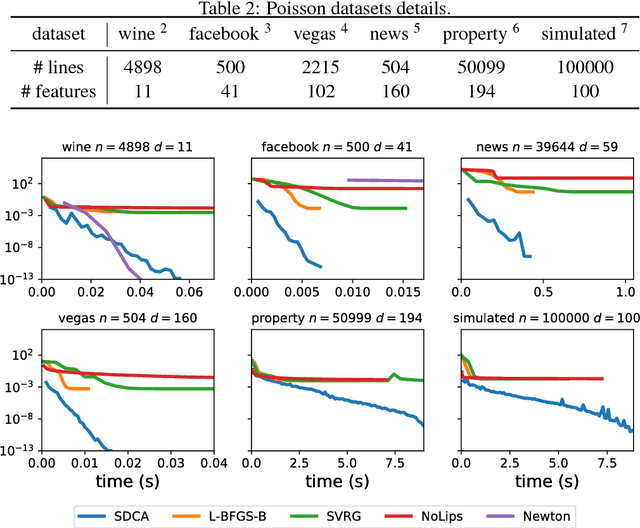
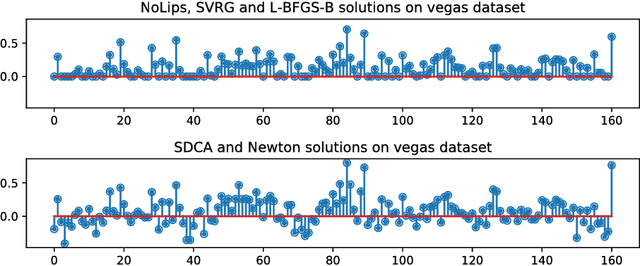
The minimization of convex objectives coming from linear supervised learning problems, such as penalized generalized linear models, can be formulated as finite sums of convex functions. For such problems, a large set of stochastic first-order solvers based on the idea of variance reduction are available and combine both computational efficiency and sound theoretical guarantees (linear convergence rates). Such rates are obtained under both gradient-Lipschitz and strong convexity assumptions. Motivated by learning problems that do not meet the gradient-Lipschitz assumption, such as linear Poisson regression, we work under another smoothness assumption, and obtain a linear convergence rate for a shifted version of Stochastic Dual Coordinate Ascent (SDCA) that improves the current state-of-the-art. Our motivation for considering a solver working on the Fenchel-dual problem comes from the fact that such objectives include many linear constraints, that are easier to deal with in the dual. Our approach and theoretical findings are validated on several datasets, for Poisson regression and another objective coming from the negative log-likelihood of the Hawkes process, which is a family of models which proves extremely useful for the modeling of information propagation in social networks and causality inference.
Tick: a Python library for statistical learning, with a particular emphasis on time-dependent modelling
Mar 15, 2018


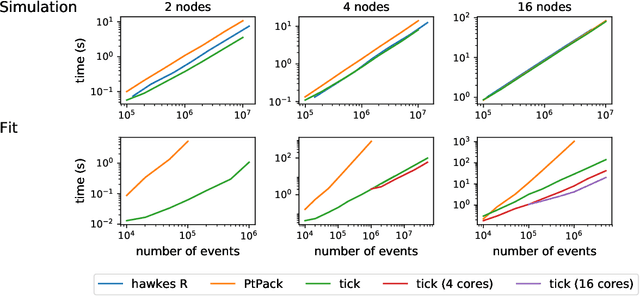
Tick is a statistical learning library for Python~3, with a particular emphasis on time-dependent models, such as point processes, and tools for generalized linear models and survival analysis. The core of the library is an optimization module providing model computational classes, solvers and proximal operators for regularization. tick relies on a C++ implementation and state-of-the-art optimization algorithms to provide very fast computations in a single node multi-core setting. Source code and documentation can be downloaded from https://github.com/X-DataInitiative/tick