 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Bandit Feedback: An Overview of the State-of-the-art
Paper and Code
Sep 18, 2019
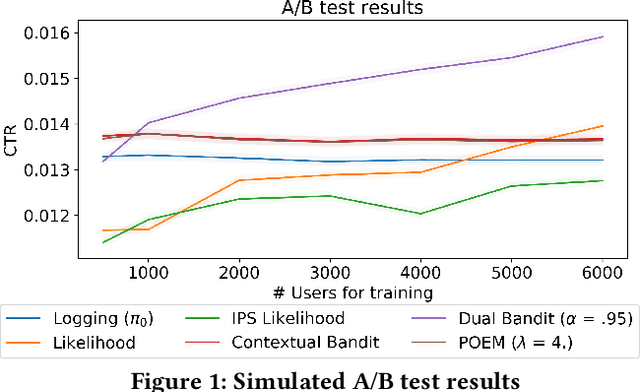
In machine learning we often try to optimise a decision rule that would have worked well over a historical dataset; this is the so called empirical risk minimisation principle. In the context of learning from recommender system logs, applying this principle becomes a problem because we do not have available the reward of decisions we did not do. In order to handle this "bandit-feedback" setting, several Counterfactual Risk Minimisation (CRM) methods have been proposed in recent years, that attempt to estimate the performance of different policies on historical data. Through importance sampling and various variance reduction techniques, these methods allow more robust learning and inference than classical approaches. It is difficult to accurately estimate the performance of policies that frequently perform actions that were infrequently done in the past and a number of different types of estimators have been proposed. In this paper, we review several methods, based on different off-policy estimators, for learning from bandit feedback. We discuss key differences and commonalities among existing approaches, and compare their empirical performance on the RecoGym simulation environment. To the best of our knowledge, this work is the first comparison study for bandit algorithms in a recommender system setting.