 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePARHAF, a human-authored corpus of clinical reports for fictitious patients in French
Mar 20, 2026The development of clinical natural language processing (NLP) systems is severely hampered by the sensitive nature of medical records, which restricts data sharing under stringent privacy regulations, particularly in France and the broader European Union. To address this gap, we introduce PARHAF, a large open-source corpus of clinical documents in French. PARHAF comprises expert-authored clinical reports describing realistic yet entirely fictitious patient cases, making it anonymous and freely shareable by design. The corpus was developed using a structured protocol that combined clinician expertise with epidemiological guidance from the French National Health Data System (SNDS), ensuring broad clinical coverage. A total of 104 medical residents across 18 specialties authored and peer-reviewed the reports following predefined clinical scenarios and document templates. The corpus contains 7394 clinical reports covering 5009 patient cases across a wide range of medical and surgical specialties. It includes a general-purpose component designed to approximate real-world hospitalization distributions, and four specialized subsets that support information-extraction use cases in oncology, infectious diseases, and diagnostic coding. Documents are released under a CC-BY open license, with a portion temporarily embargoed to enable future benchmarking under controlled conditions. PARHAF provides a valuable resource for training and evaluating French clinical language models in a fully privacy-preserving setting, and establishes a replicable methodology for building shareable synthetic clinical corpora in other languages and health systems.
Validation of a new, minimally-invasive, software smartphone device to predict sleep apnea and its severity: transversal study
Jun 20, 2024



Obstructive sleep apnea (OSA) is frequent and responsible for cardiovascular complications and excessive daytime sleepiness. It is underdiagnosed due to the difficulty to access the gold standard for diagnosis, polysomnography (PSG). Alternative methods using smartphone sensors could be useful to increase diagnosis. The objective is to assess the performances of Apneal, an application that records the sound using a smartphone's microphone and movements thanks to a smartphone's accelerometer and gyroscope, to estimate patients' AHI. In this article, we perform a monocentric proof-of-concept study with a first manual scoring step, and then an automatic detection of respiratory events from the recorded signals using a sequential deep-learning model which was released internally at Apneal at the end of 2022 (version 0.1 of Apneal automatic scoring of respiratory events), in adult patients during in-hospital polysomnography.46 patients (women 34 per cent, mean BMI 28.7 kg per m2) were included. For AHI superior to 15, sensitivity of manual scoring was 0.91, and positive predictive value (PPV) 0.89. For AHI superior to 30, sensitivity was 0.85, PPV 0.94. We obtained an AUC-ROC of 0.85 and an AUC-PR of 0.94 for the identification of AHI superior to 15, and AUC-ROC of 0.95 and AUC-PR of 0.93 for AHI superior to 30. Promising results are obtained for the automatic annotations of events.This article shows that manual scoring of smartphone-based signals is possible and accurate compared to PSG-based scorings. Automatic scoring method based on a deep learning model provides promising results. A larger multicentric validation study, involving subjects with different SAHS severity is required to confirm these results.
Agent market orders representation through a contrastive learning approach
Jun 09, 2023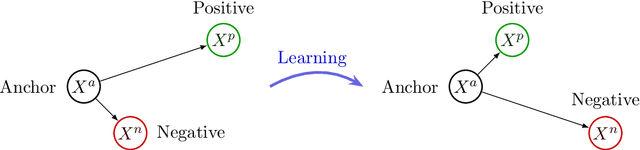
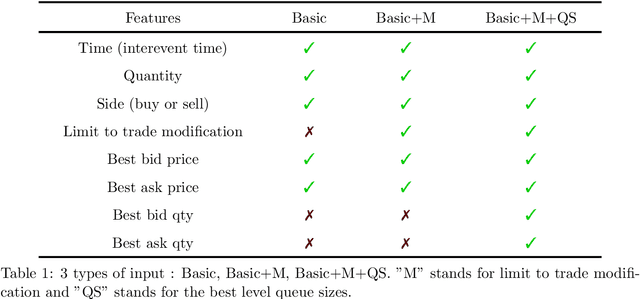
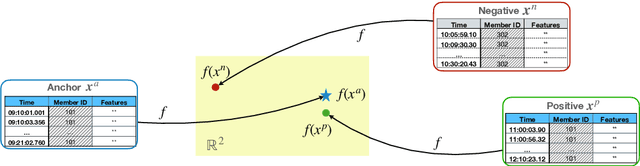

Due to the access to the labeled orders on the CAC40 data from Euronext, we are able to analyse agents' behaviours in the market based on their placed orders. In this study, we construct a self-supervised learning model using triplet loss to effectively learn the representation of agent market orders. By acquiring this learned representation, various downstream tasks become feasible. In this work, we utilise the K-means clustering algorithm on the learned representation vectors of agent orders to identify distinct behaviour types within each cluster.
About contrastive unsupervised representation learning for classification and its convergence
Dec 02, 2020
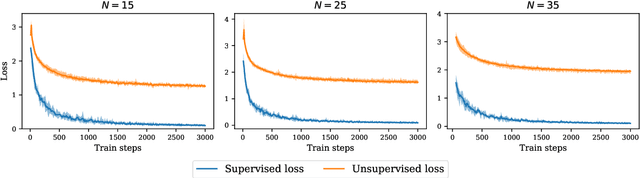
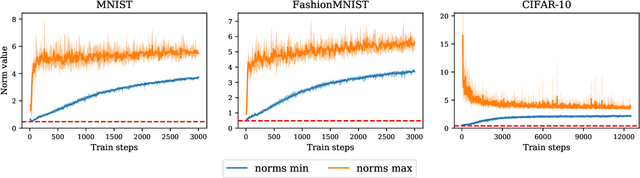
Contrastive representation learning has been recently proved to be very efficient for self-supervised training. These methods have been successfully used to train encoders which perform comparably to supervised training on downstream classification tasks. A few works have started to build a theoretical framework around contrastive learning in which guarantees for its performance can be proven. We provide extensions of these results to training with multiple negative samples and for multiway classification. Furthermore, we provide convergence guarantees for the minimization of the contrastive training error with gradient descent of an overparametrized deep neural encoder, and provide some numerical experiments that complement our theoretical findings
ZiMM: a deep learning model for long term adverse events with non-clinical claims data
Nov 13, 2019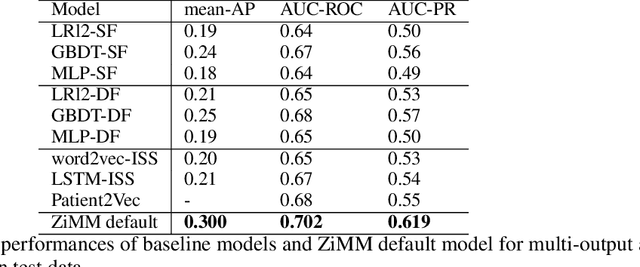
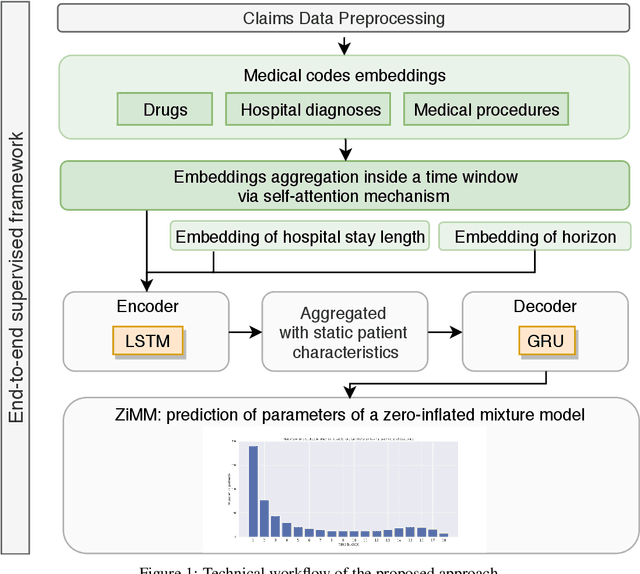
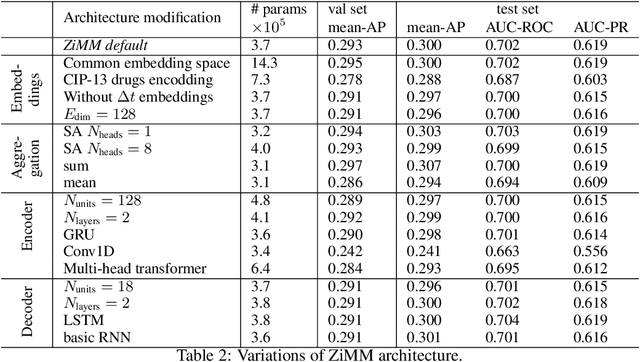
This paper considers the problem of modeling long-term adverse events following prostatic surgery performed on patients with urination problems, using the French national health insurance database (SNIIRAM), which is a non-clinical claims database built around healthcare reimbursements of more than 65 million people. This makes the problem particularly challenging compared to what could be done using clinical hospital data, albeit a much smaller sample, while we exploit here the claims of almost all French citizens diagnosed with prostatic problems (with between 1.5 and 5 years of history). We introduce a new model, called ZiMM (Zero-inflated Mixture of Multinomial distributions) to capture such long-term adverse events, and we build a deep-learning architecture on top of it to deal with the complex, highly heterogeneous and sparse patterns observable in such a large claims database. This architecture combines several ingredients: embedding layers for drugs, medical procedures, and diagnosis codes; embeddings aggregation through a self-attention mechanism; recurrent layers to encode the health pathways of patients before their surgery and a final decoder layer which outputs the ZiMM's parameters.
Dual optimization for convex constrained objectives without the gradient-Lipschitz assumption
Jul 10, 2018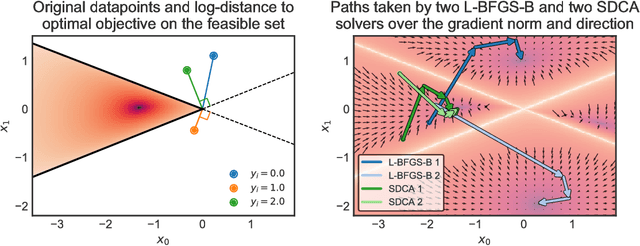
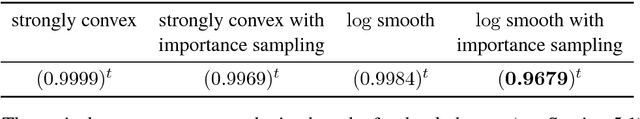
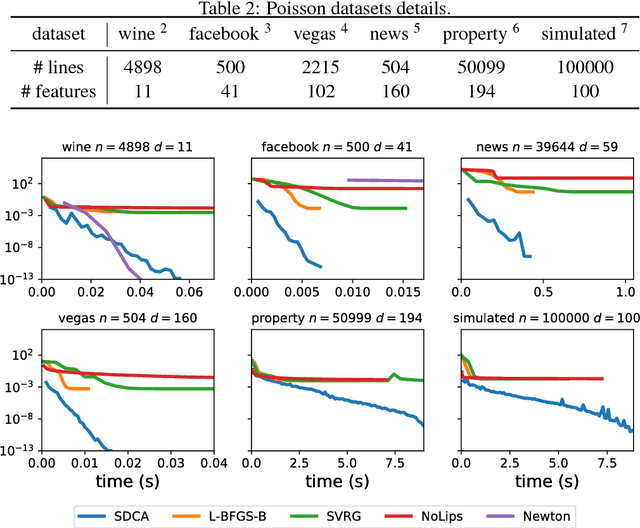
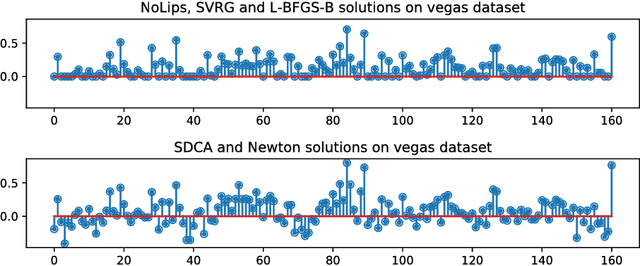
The minimization of convex objectives coming from linear supervised learning problems, such as penalized generalized linear models, can be formulated as finite sums of convex functions. For such problems, a large set of stochastic first-order solvers based on the idea of variance reduction are available and combine both computational efficiency and sound theoretical guarantees (linear convergence rates). Such rates are obtained under both gradient-Lipschitz and strong convexity assumptions. Motivated by learning problems that do not meet the gradient-Lipschitz assumption, such as linear Poisson regression, we work under another smoothness assumption, and obtain a linear convergence rate for a shifted version of Stochastic Dual Coordinate Ascent (SDCA) that improves the current state-of-the-art. Our motivation for considering a solver working on the Fenchel-dual problem comes from the fact that such objectives include many linear constraints, that are easier to deal with in the dual. Our approach and theoretical findings are validated on several datasets, for Poisson regression and another objective coming from the negative log-likelihood of the Hawkes process, which is a family of models which proves extremely useful for the modeling of information propagation in social networks and causality inference.
Tick: a Python library for statistical learning, with a particular emphasis on time-dependent modelling
Mar 15, 2018


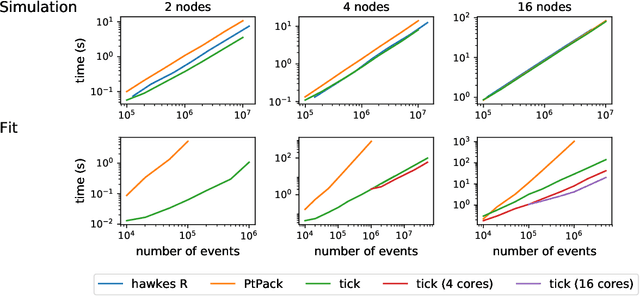
Tick is a statistical learning library for Python~3, with a particular emphasis on time-dependent models, such as point processes, and tools for generalized linear models and survival analysis. The core of the library is an optimization module providing model computational classes, solvers and proximal operators for regularization. tick relies on a C++ implementation and state-of-the-art optimization algorithms to provide very fast computations in a single node multi-core setting. Source code and documentation can be downloaded from https://github.com/X-DataInitiative/tick
ConvSCCS: convolutional self-controlled case series model for lagged adverse event detection
Jan 25, 2018
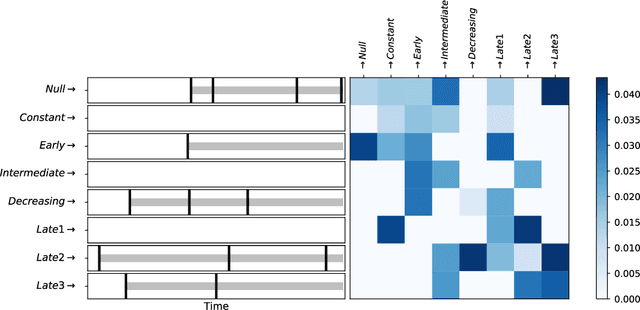
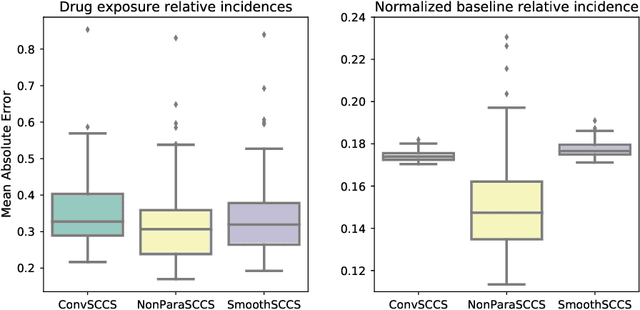
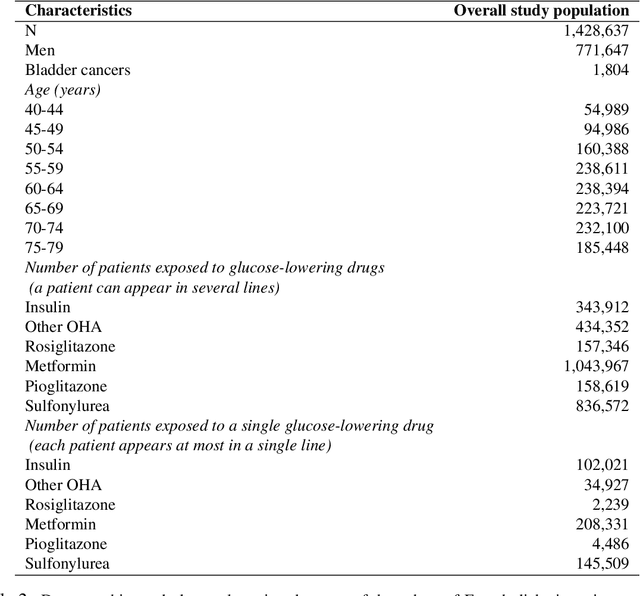
With the increased availability of large databases of electronic health records (EHRs) comes the chance of enhancing health risks screening. Most post-marketing detections of adverse drug reaction (ADR) rely on physicians' spontaneous reports, leading to under reporting. To take up this challenge, we develop a scalable model to estimate the effect of multiple longitudinal features (drug exposures) on a rare longitudinal outcome. Our procedure is based on a conditional Poisson model also known as self-controlled case series (SCCS). We model the intensity of outcomes using a convolution between exposures and step functions, that are penalized using a combination of group-Lasso and total-variation. This approach does not require the specification of precise risk periods, and allows to study in the same model several exposures at the same time. We illustrate the fact that this approach improves the state-of-the-art for the estimation of the relative risks both on simulations and on a cohort of diabetic patients, extracted from the large French national health insurance database (SNIIRAM), a SQL database built around medical reimbursements of more than 65 million people. This work has been done in the context of a research partnership between Ecole Polytechnique and CNAMTS (in charge of SNIIRAM).
Uncovering Causality from Multivariate Hawkes Integrated Cumulants
May 30, 2017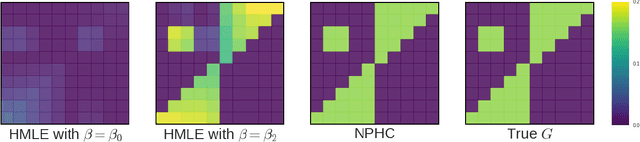

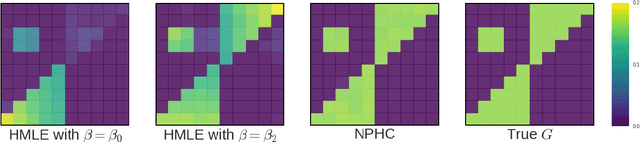
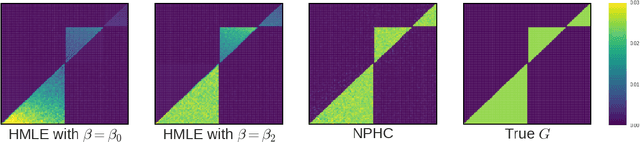
We design a new nonparametric method that allows one to estimate the matrix of integrated kernels of a multivariate Hawkes process. This matrix not only encodes the mutual influences of each nodes of the process, but also disentangles the causality relationships between them. Our approach is the first that leads to an estimation of this matrix without any parametric modeling and estimation of the kernels themselves. A consequence is that it can give an estimation of causality relationships between nodes (or users), based on their activity timestamps (on a social network for instance), without knowing or estimating the shape of the activities lifetime. For that purpose, we introduce a moment matching method that fits the third-order integrated cumulants of the process. We show on numerical experiments that our approach is indeed very robust to the shape of the kernels, and gives appealing results on the MemeTracker database.
SGD with Variance Reduction beyond Empirical Risk Minimization
Nov 08, 2016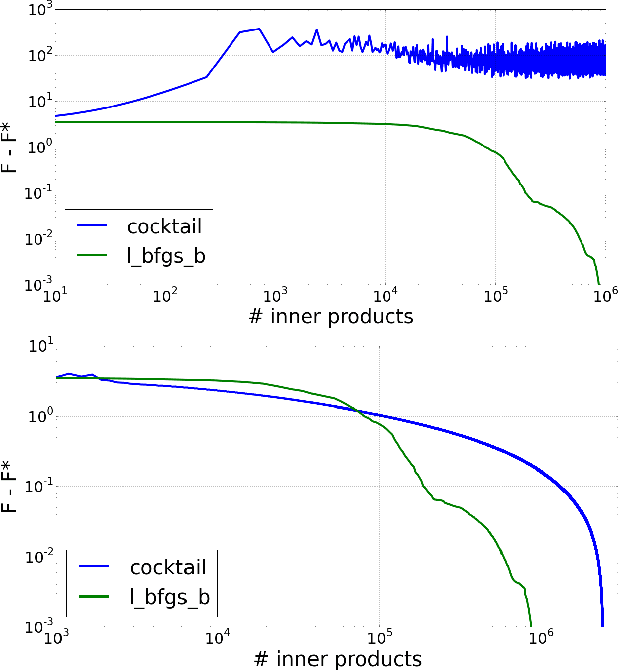
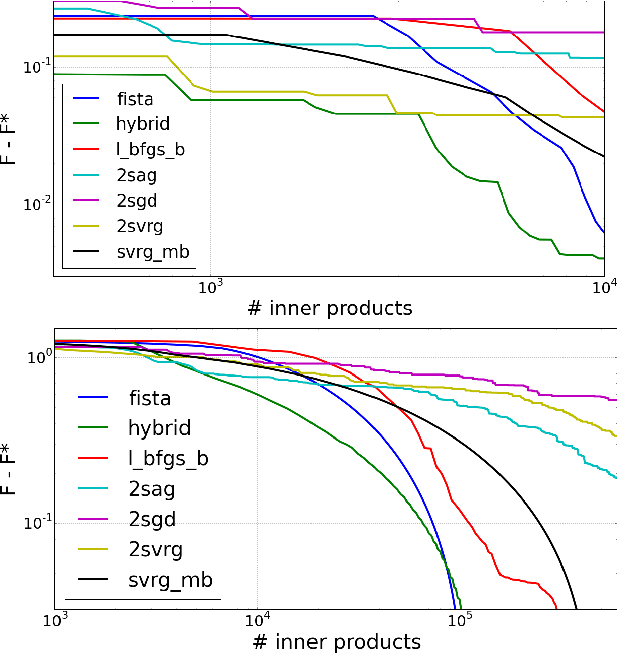
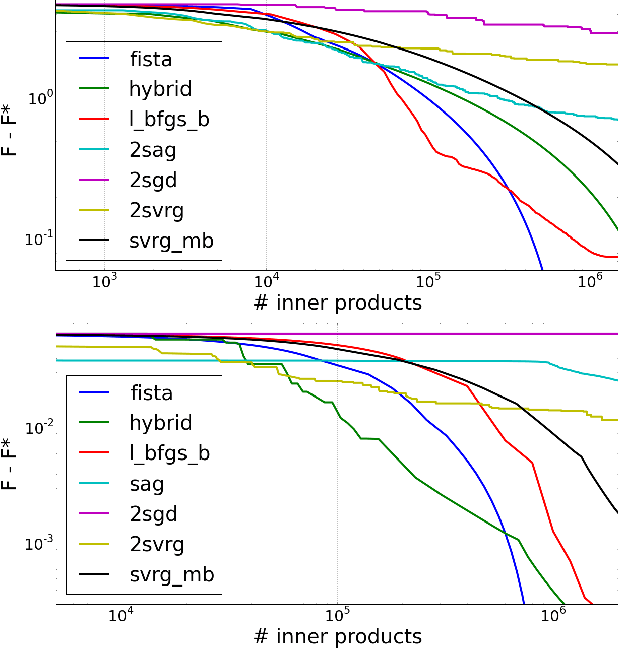
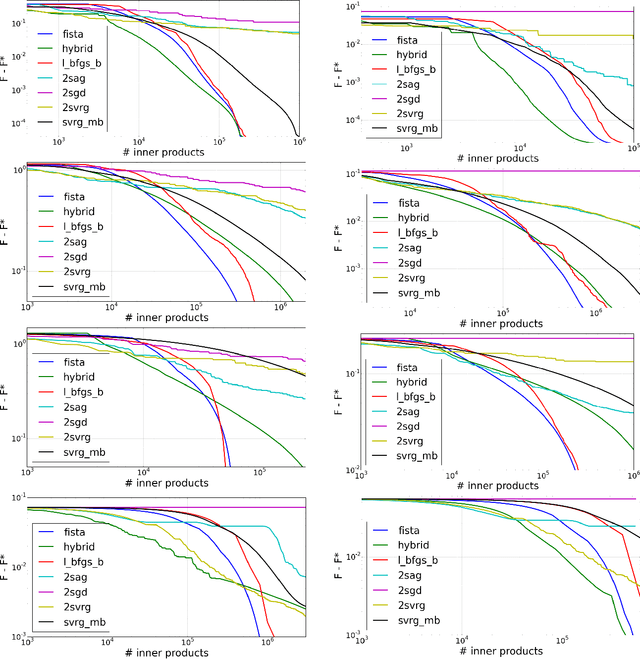
We introduce a doubly stochastic proximal gradient algorithm for optimizing a finite average of smooth convex functions, whose gradients depend on numerically expensive expectations. Our main motivation is the acceleration of the optimization of the regularized Cox partial-likelihood (the core model used in survival analysis), but our algorithm can be used in different settings as well. The proposed algorithm is doubly stochastic in the sense that gradient steps are done using stochastic gradient descent (SGD) with variance reduction, where the inner expectations are approximated by a Monte-Carlo Markov-Chain (MCMC) algorithm. We derive conditions on the MCMC number of iterations guaranteeing convergence, and obtain a linear rate of convergence under strong convexity and a sublinear rate without this assumption. We illustrate the fact that our algorithm improves the state-of-the-art solver for regularized Cox partial-likelihood on several datasets from survival analysis.