 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the gap between regret minimization and best arm identification, with application to A/B tests
Oct 09, 2018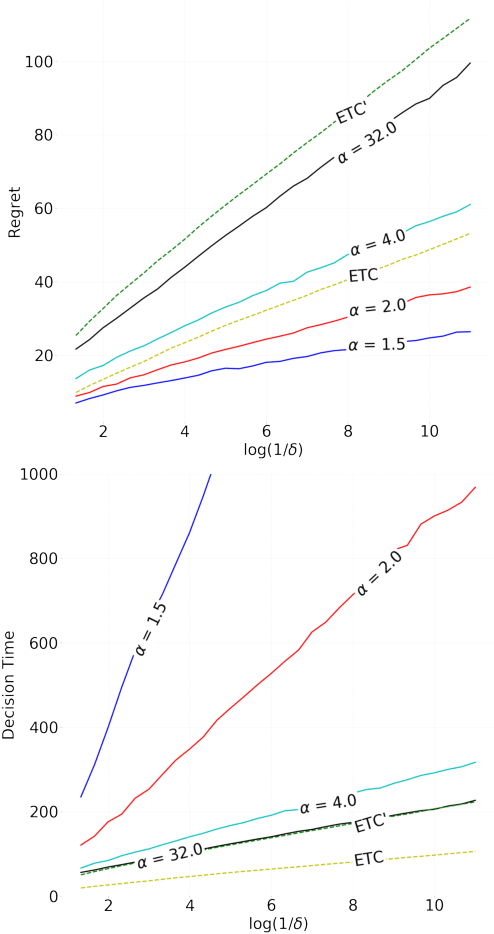
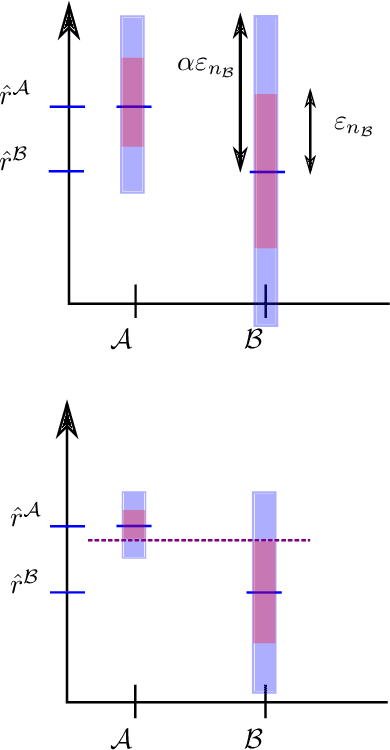
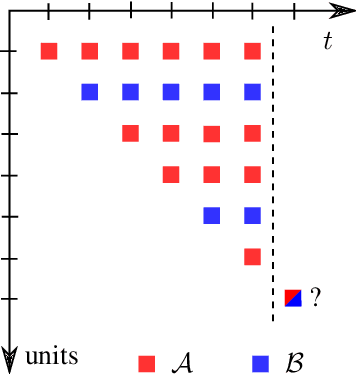
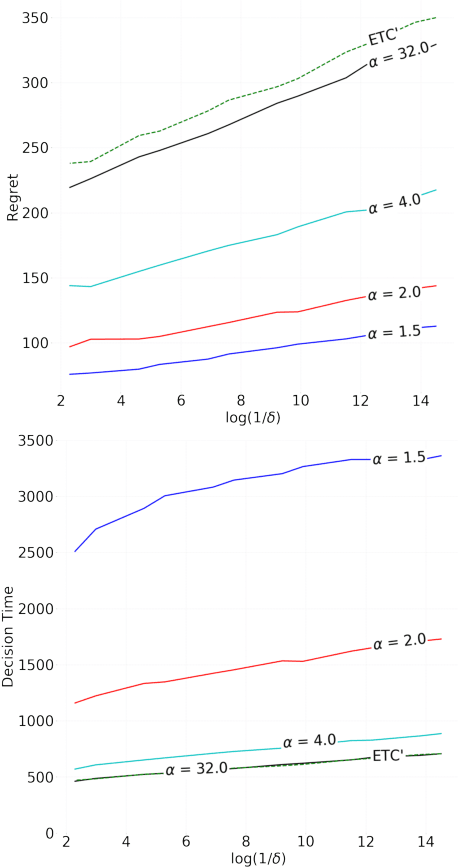
State of the art online learning procedures focus either on selecting the best alternative ("best arm identification") or on minimizing the cost (the "regret"). We merge these two objectives by providing the theoretical analysis of cost minimizing algorithms that are also delta-PAC (with a proven guaranteed bound on the decision time), hence fulfilling at the same time regret minimization and best arm identification. This analysis sheds light on the common observation that ill-callibrated UCB-algorithms minimize regret while still identifying quickly the best arm. We also extend these results to the non-iid case faced by many practitioners. This provides a technique to make cost versus decision time compromise when doing adaptive tests with applications ranging from website A/B testing to clinical trials.
Offline A/B testing for Recommender Systems
Jan 22, 2018


Before A/B testing online a new version of a recommender system, it is usual to perform some offline evaluations on historical data. We focus on evaluation methods that compute an estimator of the potential uplift in revenue that could generate this new technology. It helps to iterate faster and to avoid losing money by detecting poor policies. These estimators are known as counterfactual or off-policy estimators. We show that traditional counterfactual estimators such as capped importance sampling and normalised importance sampling are experimentally not having satisfying bias-variance compromises in the context of personalised product recommendation for online advertising. We propose two variants of counterfactual estimates with different modelling of the bias that prove to be accurate in real-world conditions. We provide a benchmark of these estimators by showing their correlation with business metrics observed by running online A/B tests on a commercial recommender system.
A comparative study of counterfactual estimators
May 02, 2017
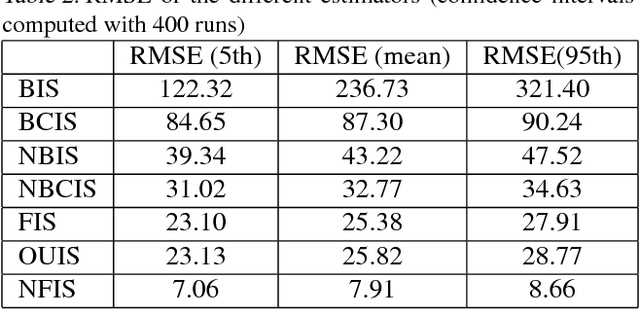
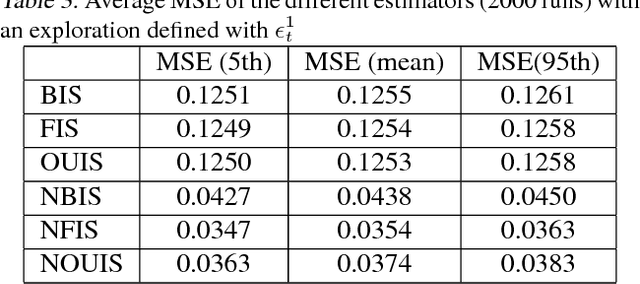
We provide a comparative study of several widely used off-policy estimators (Empirical Average, Basic Importance Sampling and Normalized Importance Sampling), detailing the different regimes where they are individually suboptimal. We then exhibit properties optimal estimators should possess. In the case where examples have been gathered using multiple policies, we show that fused estimators dominate basic ones but can still be improved.