 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimization Approaches for Counterfactual Risk Minimization with Continuous Actions
Paper and Code
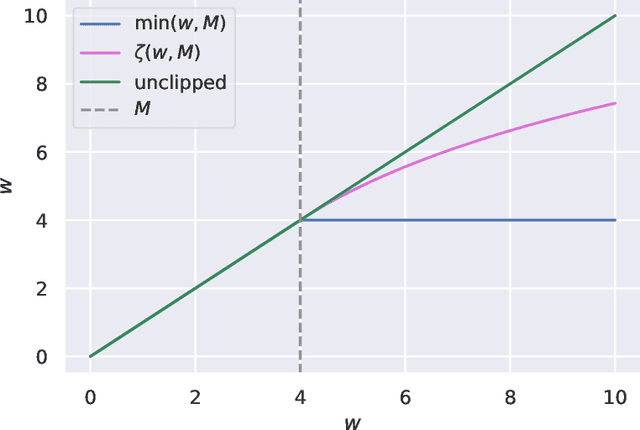
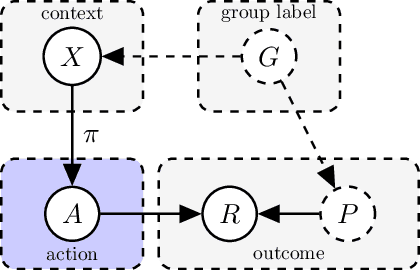
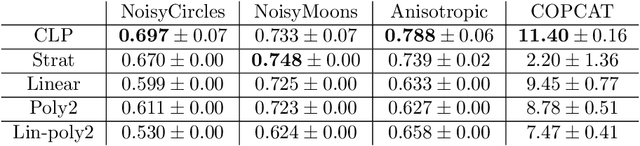

Counterfactual reasoning from logged data has become increasingly important for a large range of applications such as web advertising or healthcare. In this paper, we address the problem of counterfactual risk minimization for learning a stochastic policy with a continuous action space. Whereas previous works have mostly focused on deriving statistical estimators with importance sampling, we show that the optimization perspective is equally important for solving the resulting nonconvex optimization problems.Specifically, we demonstrate the benefits of proximal point algorithms and soft-clipping estimators which are more amenable to gradient-based optimization than classical hard clipping. We propose multiple synthetic, yet realistic, evaluation setups, and we release a new large-scale dataset based on web advertising data for this problem that is crucially missing public benchmarks.